本文主要是介绍【网络奇缘系列】计算机网络|数据通信方式|数据传输方式,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

🌈个人主页: Aileen_0v0
🔥系列专栏: 一见倾心,再见倾城 --- 计算机网络~
💫个人格言:"没有罗马,那就自己创造罗马~"
这篇文章是关于计算机网络中数据通信的基础知识点,
从模型,术语再到数据通信方式,传输方式,以及如何实现数据的同步传输
追光的人,终会光芒万丈
【Those who pursue light will eventually shine brightly💫】

目录
编辑
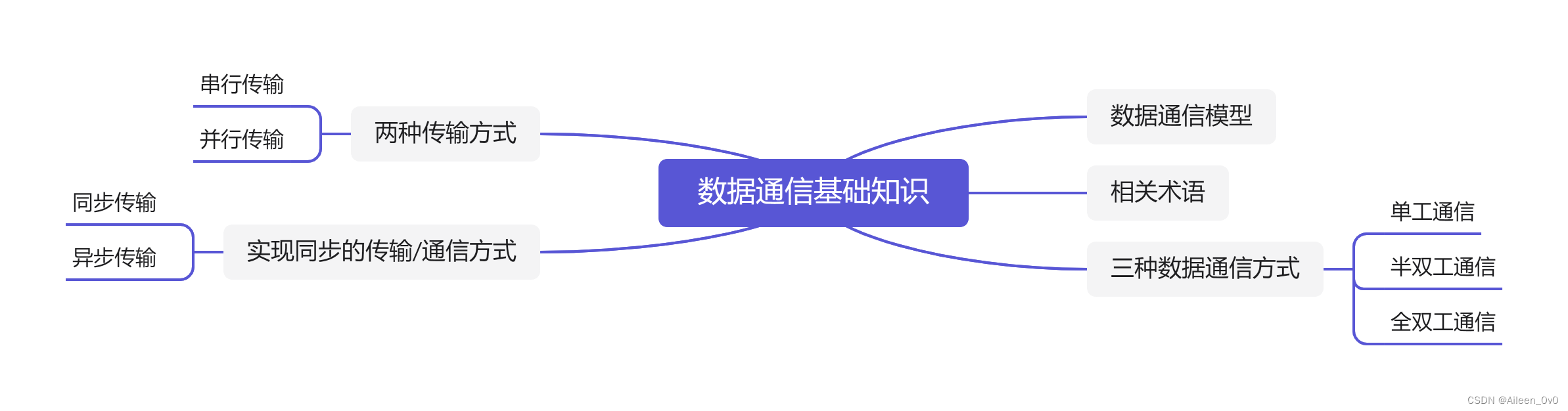
数据通信模型编辑
数据通信相关术语
通信目的:
数据data:
信号:
编辑信源:
信宿:
信道:
数据通信三种方式
1.单工通信 - 广播
2.半双工通信/双相交替通信 - 对讲机
3.全双工通信/双向同时通信 - 打电话
数据传输方式
串行传输:
并行传输:
实现同步传输/通信方式
同步传输:
异步传输:
总结 ✍️
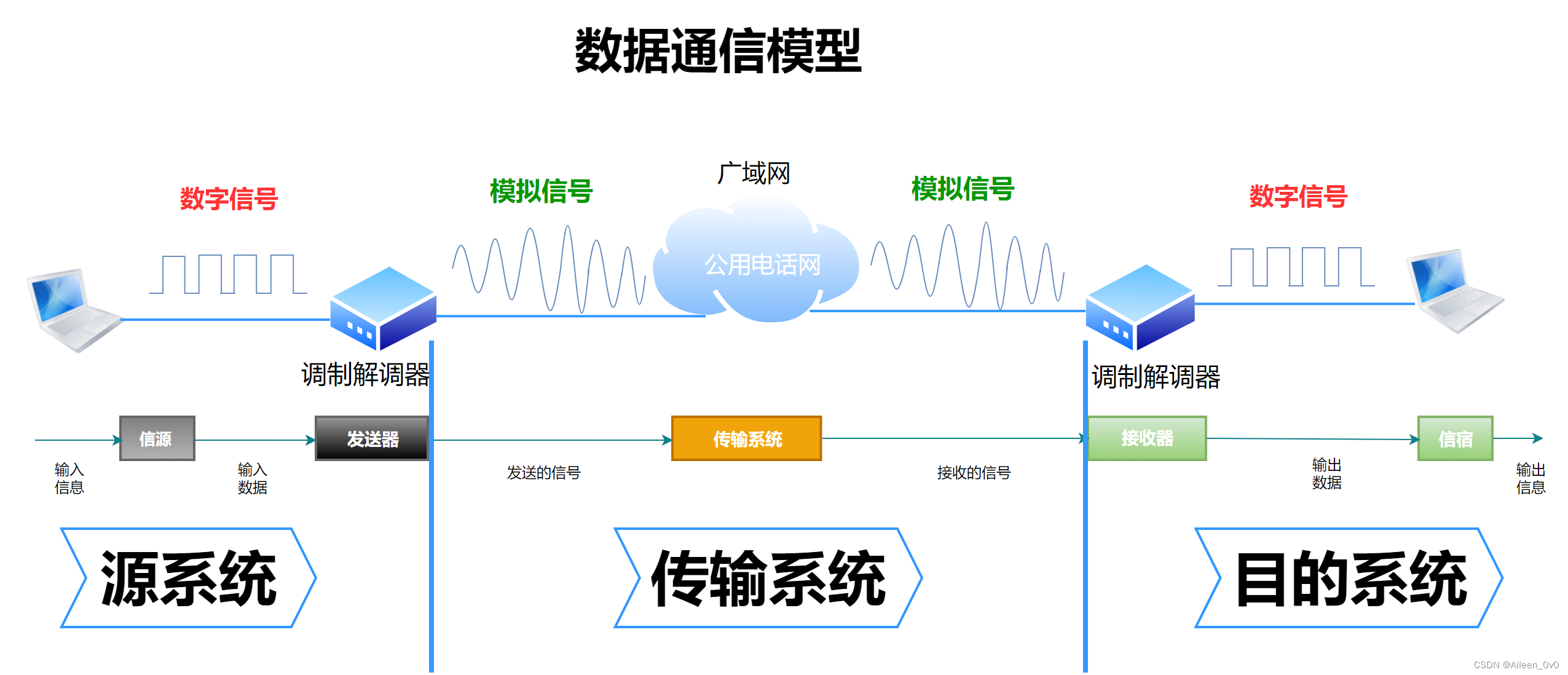
数据通信模型
广域网中有很多的模拟信道,模拟信道只能传模拟信号,所以数字信号需要先通过调制解压器将其转化成模拟信号
数据通信相关术语
通信目的:
传送消息(消息:语音,文字,图像,视频等).
数据通信是指在不同计算机之间,传输表示二进制数0,1序列的过程。
数据data:
传送信息的实体,通常是有意义的符号序列。
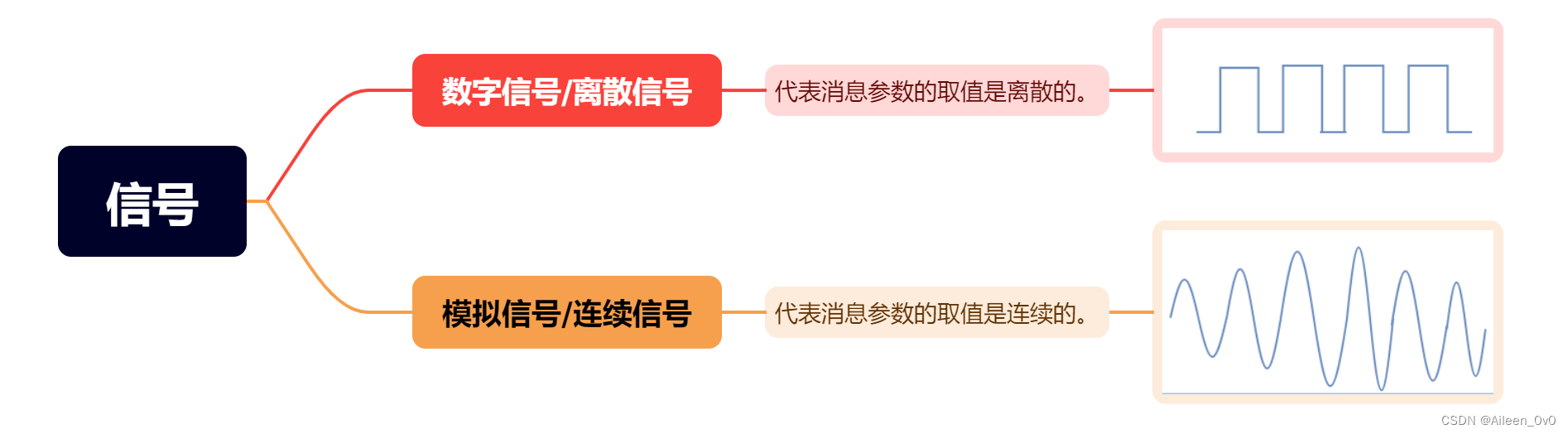
信号:
数据的电气/电磁的表现,是数据在传输过程中的存在形式。
 信源:
信源:
产生和发送数据的源头。
信宿:
接收数据的终点。
信道:
信号的传输媒介。一般用来表示某一个方向传送信息的介质,因此一条信道线路往往包含一条发送信道和一条接收信道。

数据通信三种方式
从双方信息交互方式上看,数据通信有三种基本方式:
1.单工通信 - 广播
只有一个方向的通信没有反方向的交互,仅需一条信道。
2.半双工通信/双相交替通信 - 对讲机
通信的双方都可以发送或接收信息,但任何一方都不能同时发送和接收,需要两条信道。
3.全双工通信/双向同时通信 - 打电话
通信双方可以同时发送和接收信息,需要两条通道
数据传输方式
数据传输方式包括:串行传输和并行传输。
串行传输:
相当于一个人吃掉八个包子
并行传输:
相当于找八个人每个人吃一个包子

实现同步传输/通信方式
同步传输:
同步传输模式下,数据的传送以一个数据区块为单位,So 同步传输又称为区块传输。
在传输数据时,需先送出一个或多个同步字符,再送出整批的数据。

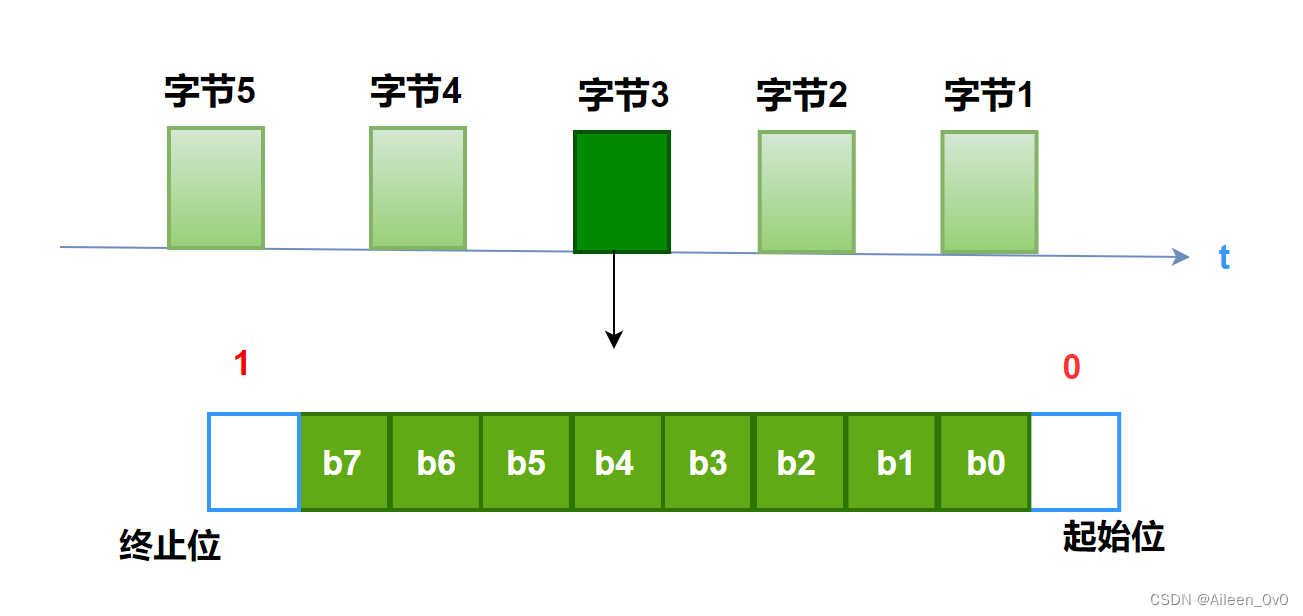
异步传输:
异步传输将比特分成小组进行传递,小组可以是8位的一个字符或更长。
发送方可在任何时刻发送这些比特组,而接收方不知道它们什么时候到达。
为了实现同步传输,数据在传输时,会在数据头尾分别加上一个字符起始位和一个字符终止位。
总结 ✍️




这篇关于【网络奇缘系列】计算机网络|数据通信方式|数据传输方式的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








