本文主要是介绍The Load Slice Core Microarchitecture,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
The Load Slice Core Microarchitecture
-
摘要:
- 背景:
- 为了挖掘ILP,处理器从简单的按序流水线发展为超标量乱序流水线。利用超标量乱序流水线在提高ILP的同时,也能够提高cache和memory操作的并行。
- 但是随着片外的存储墙和更复杂多核中的缓存层级结构,cache和memory的访问代价变得更大,因此MHP(memory hierarchy parallelism)的重要性也更加重要。
- 多核处理器经常工作在功耗和能耗受限的环境中,因此能效将会更加重要
- 论文工作
- 目标:提出一种处理器微架构(Load Slice Core),能够提供对存储层次结构的并行访问,同时最大化能效
- Load Slice Core:使用第二条按序流水线扩展了一个按序,stall-on-use(正在使用而停顿)的高效流水线,第二条流水线允许内存访问和地址生成指令绕过原本流水线中停顿的指令
- 在该结构中,利用硬件实现了自动提取包含load和store指令的地址计算指令的向后程序片(backward program slice)
- 论文结果:
- LSC相对于基准的按序处理器,性能提升了53%,面积增加了13%,功耗增加了22%。在能效上(MIPS/Watt),相对于按序和乱序流水线提高了43%和4.7倍
- 对于一个功耗和面积限制的众核设计中,LSC相对于乱序和按序设计,能够提高53%和95%的性能
- 背景:
-
介绍:
- 现状:首先处理器性能的发展和主存的发展不协调,出现了存储墙;其次是ILP提取的饱和和功耗的限制使得多核和众核的出现;随着而来的是众核导致的更加复杂的片上存储层级结构和更复杂的一致性处理,存储的访问延迟也会因此提高
- MHP(memory hierarchy parallelism):论文定义为从核的角度,是发生在缓存的所有层次的重叠的存储存取操作的平均数目
- 乱序处理器:乱序处理器在挖掘ILP的同时也会自动提高MHP,但是这种做法的代价很大,包括芯片设计复杂度,功耗和面积
- 已有的阻止处理器由于长延迟loads而停顿的技术
- runahead execution:提前执行,以发现并且预取独立的数据
- slice processor:静态/动态的提取独立的代码片段,这些代码片可以根据阻塞的指令流,乱序的调度执行。
- 构建独立代码片段的方法:软件上的分析或者在硬件上标识这些代码片段,用于推测和重新执行,或者是缓存这些代码片段以便重新执行
- 问题:添加额外复杂的硬件结构,需要重新编译或者修改现有软件,依赖于重新执行浪费时间和能量的部分指令流
- 为了解决之前技术的限制,论文提出了Load Slice Core微架构,一种受限的乱序处理器,用于直接从内存层次结构中提取并行性
- 提供了一种高能效的硬件方式构建,存储和重新调用的反向代码片段(在论文中指代存储指令的计算地址部分的代码)
- LSC的基础处理器是超标量按序处理器,采用stall-on-use(相关停顿)策略。额外增加第二条按序流水线用于处理load指令和相关的地址生成
- 提高MHP:相对于主指令流而言,乱序的执行选择的指令来提高MHP
- LSC的优势:严格的限制可以旁路的指令,使用简单的结构(RAM和FIFO),从而保证好的功效和面积效率,并且性能接近于乱序的设计
-
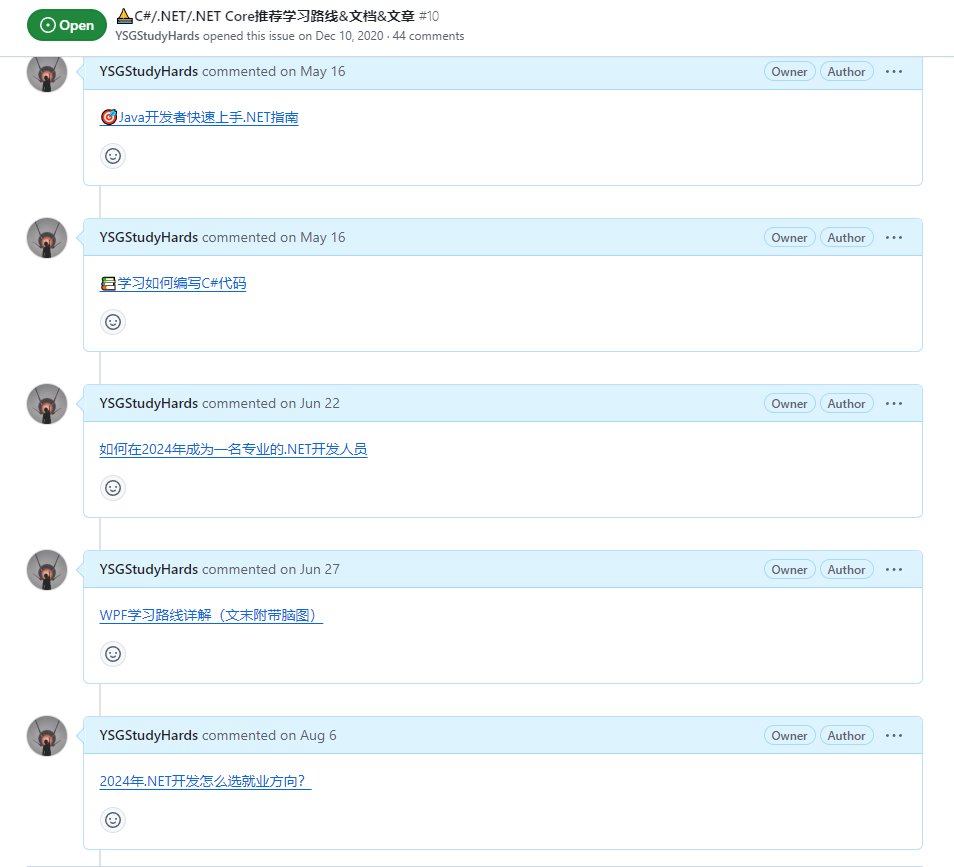
动机:为了分析ILP和MHP对性能的影响,论文进行了一些实验,用于不同的发射规则产生的影响
-
实验环境:2路乱序超标量处理器,指令窗口32表项(OOO) +spec CPU2006
-
实验1:
- 乱序发射,每周期最多可以发射两条指令(假设有理想的旁路,也可以消除所有load和store之间的地址歧义)
- 按序发射:在指令窗口顶部的指令可以发射
-
实验2:乱序发射的loads
- 在按序核中,乱序执行某些选择的指令。在实验中,当load指令的地址可用并且与之前没有完成的store指令不冲突时,load指令就可以被发射出去
- 虽然可以乱序发射,但是每个周期最多只能执行两条指令
-
实验3:ooo loads+AGI(地址生成指令)
- AGI:定义为仍然在指令窗口中的任何一条指令,如果该指令与load指令(可能跨越控制流)之间存在依赖关系链
- 该实验假设可以知道哪些指令之后会用于地址计算
-
实验4:ooo load+AGI(no-spec)
- 相对于前一个实验,该实验要求虽然load指令和AGI乱序执行,但是不能够跨域尚未解决的分支指令
- 如果期望包括MHP,一般都需要推测执行,因此也需要规则用于处理错误分支预测之后的恢复
-
实验5:ooo load+AGI(in-order)
- 之前实验中乱序执行load和AGI指令,会使得实现复杂度基本和乱序执行一样
- 在这个实验中,按序执行load和AGI指令,但是相对于主指令流乱序执行。在实验中采用两条简单的按序流水线,在两者之间增加bypass队列,用于传递数据
-
论文设计Load Slice Core微结构的三个关键见解
- 扩展一个高效,按序的stall-on-use处理器,以支持乱序执行load和AGI指令,并且允许将load的数据传递给更老的由于存储访问而阻塞的指令
- load指令和AGI指令的乱序执行是相对于主指令流而言的,在load和AGI指令之间仍旧是按序执行。从而避免了复杂的wake-up和selection逻辑
- 通过程序中出现的循环行为,迭代的检测地址生成指令,每次后退一步
-
LSC中解决load和store之间的相关检测的问题
- 当load指令和更早的相关的store指令重叠时,必须能够检查这种相关
- 论文将store指令拆分成地址计算和更新存储两个部分,前者可以bypass queue中执行,后者在main queue中执行。这种情况下,如果store的地址没有得到,将会阻塞之后的旁路队列中load指令执行,之后执行的load指令将可以检查之前的store指令,从而满足RAW的相关
-
-
迭代向后依赖分析(IBDA,iterative backward dependency analysis,用于标记地址生成指令)
- 目的:使用低成本,易于硬件实现的方式识别出地址生成指令
- 主要思想:对于循环中的指令,每次识别反向代码片段中的一条指令。在下一次循环迭代中,再次标记上一次找到指令的生产者指令,从而最终找到所有的地址生成的相关指令
- 实现:在处理器前端,包括两个结构:IST和RDT
- IST(instruction slice table):用于记录被识别为反向代码片段中的指令的地址。当指令要被分派时,利用IST的数据,决定当前指令应该被分发到bypass队列还是main队列
- RDT(register dependency table):每个物理寄存器对应于一个表项,在表项中记录当前哪一条指令将会写入该寄存器。通过根据当前load指令的源寄存器,可以利用RDT找到上一层的生产者指令。如果是load指令的相关生产者指令,将会被记录在IST中
- 利用IST和RDT,每一次可以找到上一层的生产者指令,直到所有的相关指令都被记录在IST中。这种方式的依据是未来的执行行为将会看到同样的相关链
-
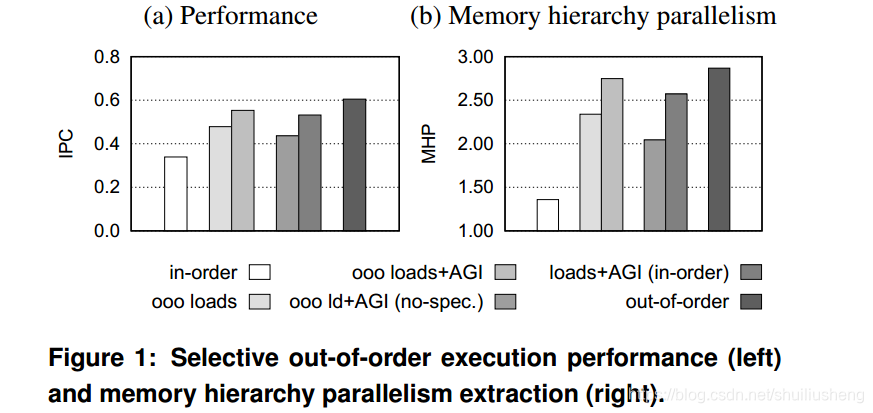
Load Slice Core微结构
- 前端流水线:
- 取值阶段,当获取到指令之后,利用指令地址索引IST表,判断是否是已知的地址生成指令,并且将该信息传递到dispatch阶段使用
- 当选择的体系结构是边长指令时,该过程将需要在译码之后才能够开始(确定指令地址)
- 寄存器重命名:用于消除LSC中假的相关关系
- 保证bypass队列中提前执行的指令的计算结果可以存储在寄存器堆中,并且在之后被主队列或者旁路队列引用
- 使用寄存器映射表将逻辑寄存器映射为物理寄存器,重命名过程基本和OOO一样
- 提供恢复log,用于在发生分支预测错误和异常时回滚和恢复寄存器映射表
- 相关分析(dependency analysis),IBDA
- IST:使用cache结构,包括tag位域,共128表项,2路组相联,LRU替换算法。每个表项不包括任何的数据位。IST采用指令地址索引,如果命中,则该指令为AGI,否则代表不是或者未记录。load和store指令不需要存储在IST中,而是直接分派到bypass队列中
- RDT:表项数和物理寄存器数一致,表项中存储着写入该寄存器的最后一条指令。当指令译码和重命名时,指令的地址和当前的IST hit位将会被写入RDT表项中
- 一条指令的生产者指令,可以通过根据该指令的源寄存器查询RDT得到。如果当前指令是load,store或者是AGI指令,通过RDT查找该指令的生产者指令;如果生产者指令在RDT中的IST bit没有设置,则将该指令的地址插入到IST中(如果为1,意味着IST中已经包括)
- Instruction dispatch,指令分派
- 根据指令的类型(load/store)和IST hit位,决定指令分派到哪一个队列。
- Store指令会同时进入两个队列,地址计算会放在bypass队列中,获取数据更新存储器会在main队列中(原因之前介绍过)
- 发射和执行
- 每周期最多调度两条指令执行(每个队列最多可以发射两条,但是一共也是最多两条)
- 如果两个队列都有ready的执行,则选择最老的指令发射
- 为了简化,所有FU在两个队列之间共享
- 存储相关:memory dependencies
- Store指令会分解成两个部分分别进入两个队列,地址计算在bypass队列,保证store指令一定会在后面的load指令之前完成,存储更新在main队列,当地址计算完成之后才会发射出去
- Store指令的地址计算完成之后,会将地址存储在store buffer中,等待store的更新操作达到main队列的头部
- 提交Commit
- 用于检查异常和改变体系结构状态,释放一些结构,例如store buffer,Rename寄存器
- 指令在分派时,按序进入记分板中,乱序的记录指令的完成状态,按序的提交
- 前端流水线:
-
实验
-
实验环境:Sniper多核模拟器和时钟级别的按序和乱序模型+SPEC CPU2006
-
处理器参数:

-
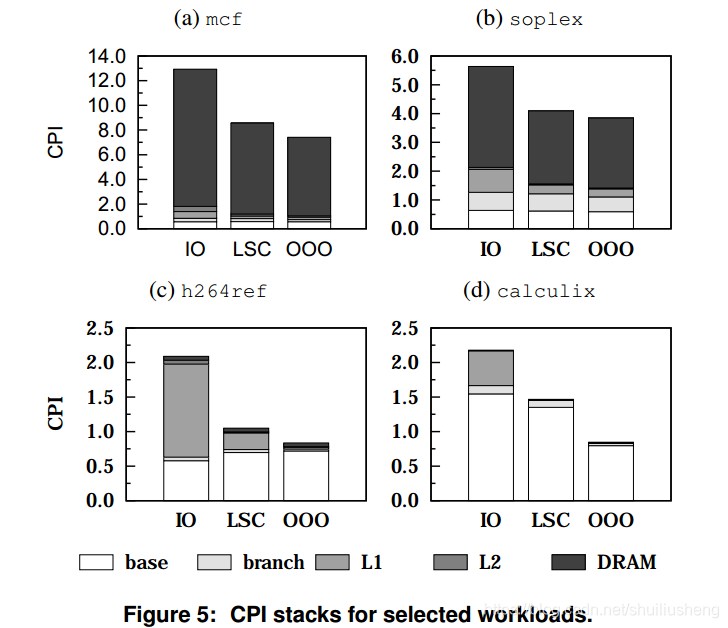
单核测试的性能

-
不同部分对CPI的贡献情况
-
这篇关于The Load Slice Core Microarchitecture的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!