本文主要是介绍详解ZNS SSD基本原理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
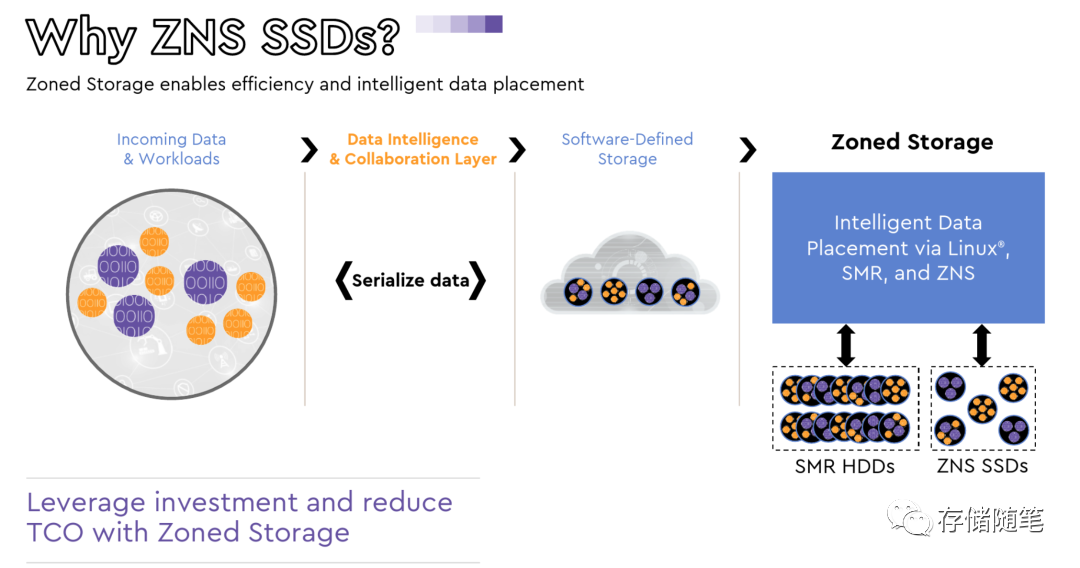
ZNS SSD的原理是把namespace空间划分多个zone空间,zone空间内部执行顺序写。这样做的优势:
-
降低SSD内部的写放大,提升SSD的寿命
-
降低OP空间,host可以获得更大的使用空间
-
降低SSD内部DRAM的容量,降低整体的SSD成本
-
降低SSD写延迟
-
ZNS写入了标准NVME协议,更易于打造软件生态,利于普及
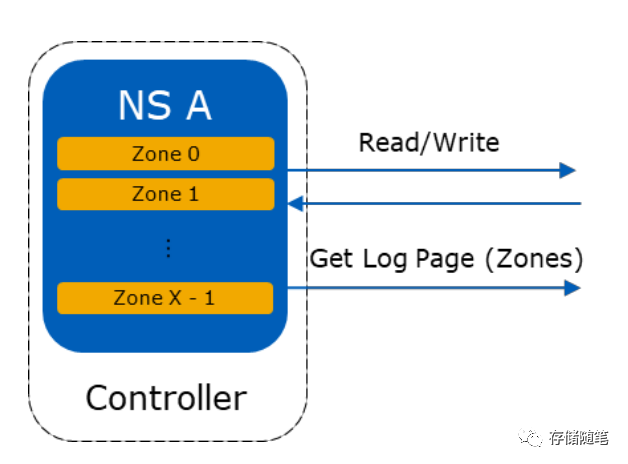
与SMR架构类似,ZNS SSD的zone空间内部,也是追加写。每次顺序写完成后,有一个标记位“Write Pointer”来记录已经写过数据所在的LBA位置。
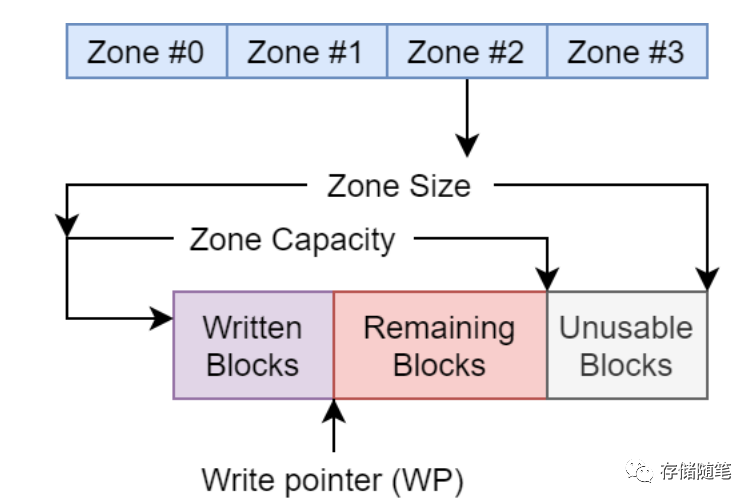
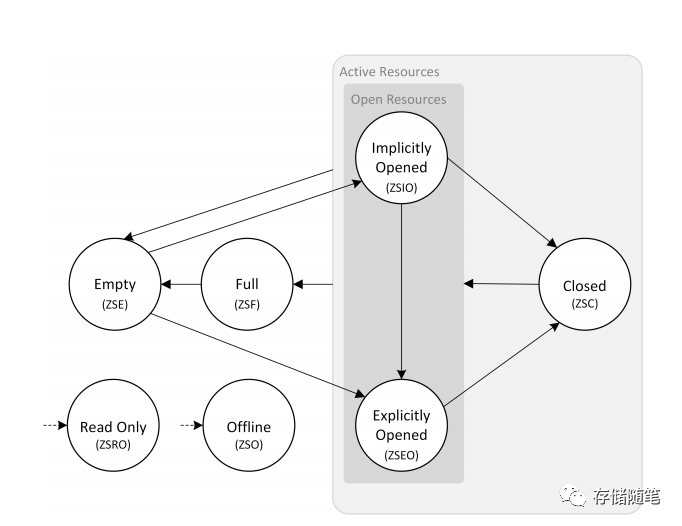
Zone的状态有以下几个:
-
Full:zone写满的状态
-
Empty:zone数据空的状态
-
Explicitly Opened:对zone执行open zone命令成功后的状态
-
Implicitly Opened:对处于Empty或者Closed状态的zone完成写数据后的状态
-
Closed:还未写满的zone,在close zone命令成功后的状态
-
Read Only:处于只读状态的zone
-
Offline:zone处于异常状态,可能是介质异常或者其他的问题
在Linux内核适配方面,针对zoned设备,之前针对SMR已经有ZAC/ZBC命令规范,并在4.10内核已经支持。针对ZNS SSD,在内核5.10以后也支持了ZNS SSD,软件生态已经基本完善。

在传统的SSD中,SSD控制器会搭配10-100个NAND Die存储介质,管理这些NAND介质就需要一个强大的算法,这里就有一个FTL管理层。
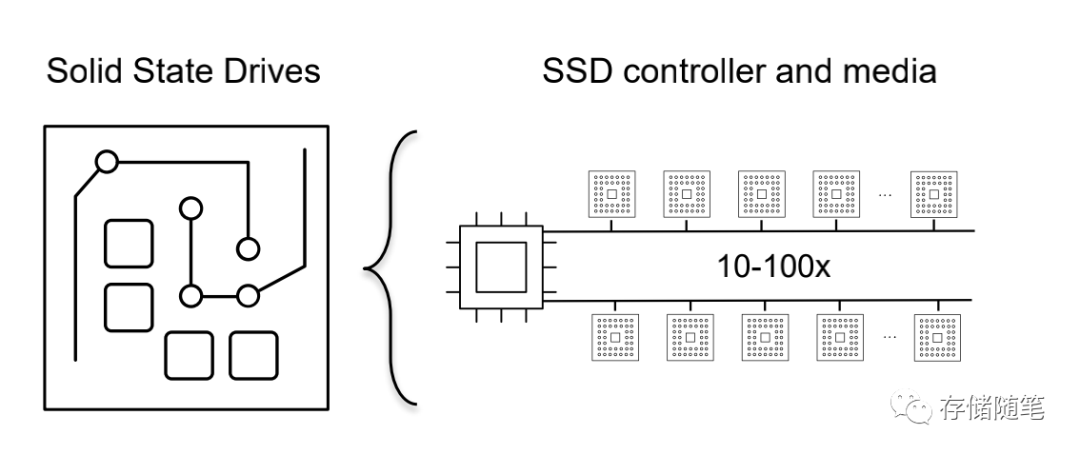
在这个过程中,ZNS SSD最大的优势是取消了块接口税(Block Inteface Tax)。

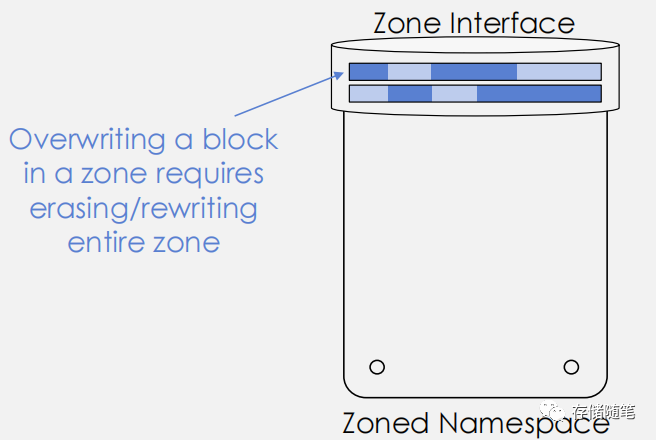
与传统Block SSD相比,性能更加稳定,不受OP的影响。

如果在文件系统层删除一个文件,比如下图文件C,在没有GC搬迁的情况下,会在无效数据C会占用大量的存储空间。
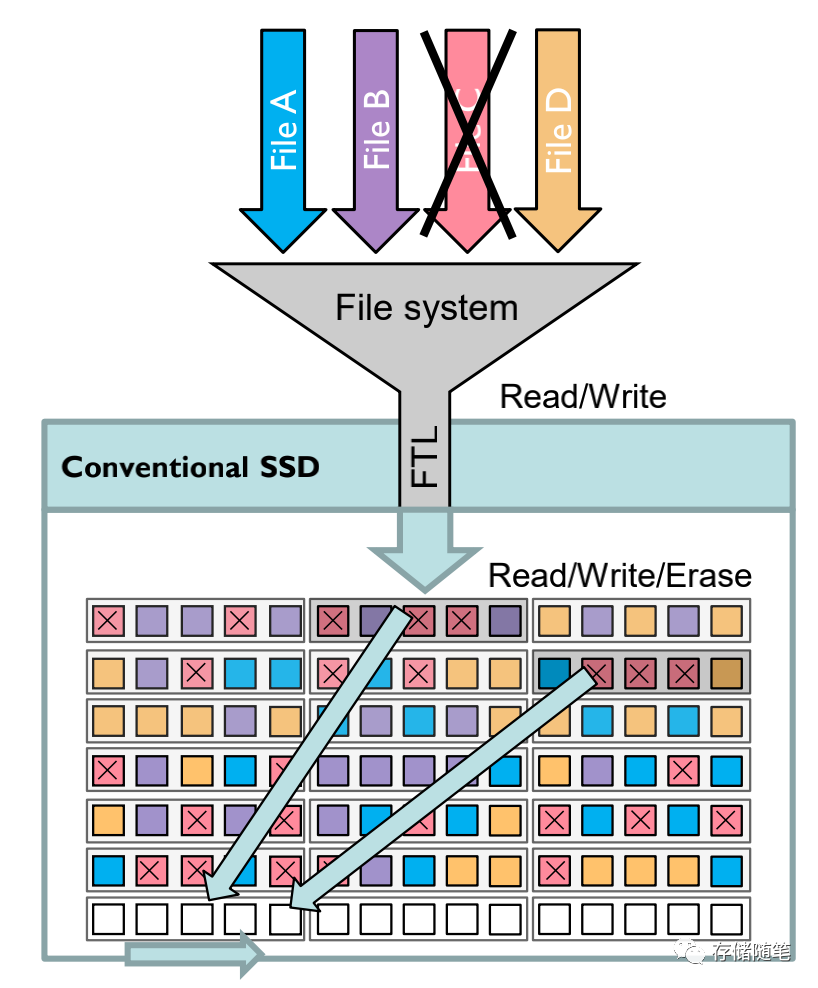
GC搬迁有效数据到空的block后,之前无效文件C所在数据块block就可以被整个block擦除了。
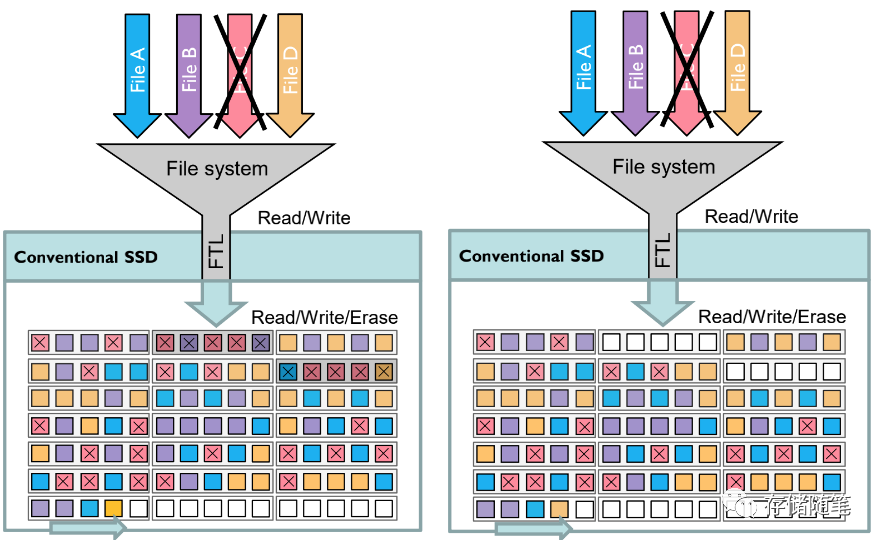
整个GC的过程最终导致写放大WAF的增加。写放大的增加相应对SSD带来的负面效应就是写带宽下降、读延迟升高、使用寿命下降等问题。
在ZNS的场景下,不同应用按照Zone配置信息,相应存放业务数据。主要集中在顺序读写的workload场景。由于是Host管理数据的摆放和存取位置,会最大程度减少GC垃圾回收。
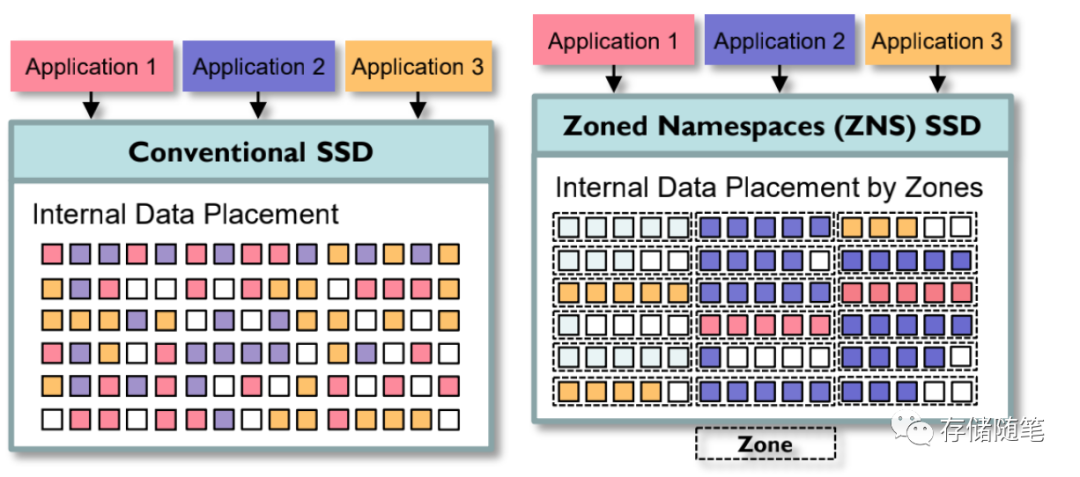
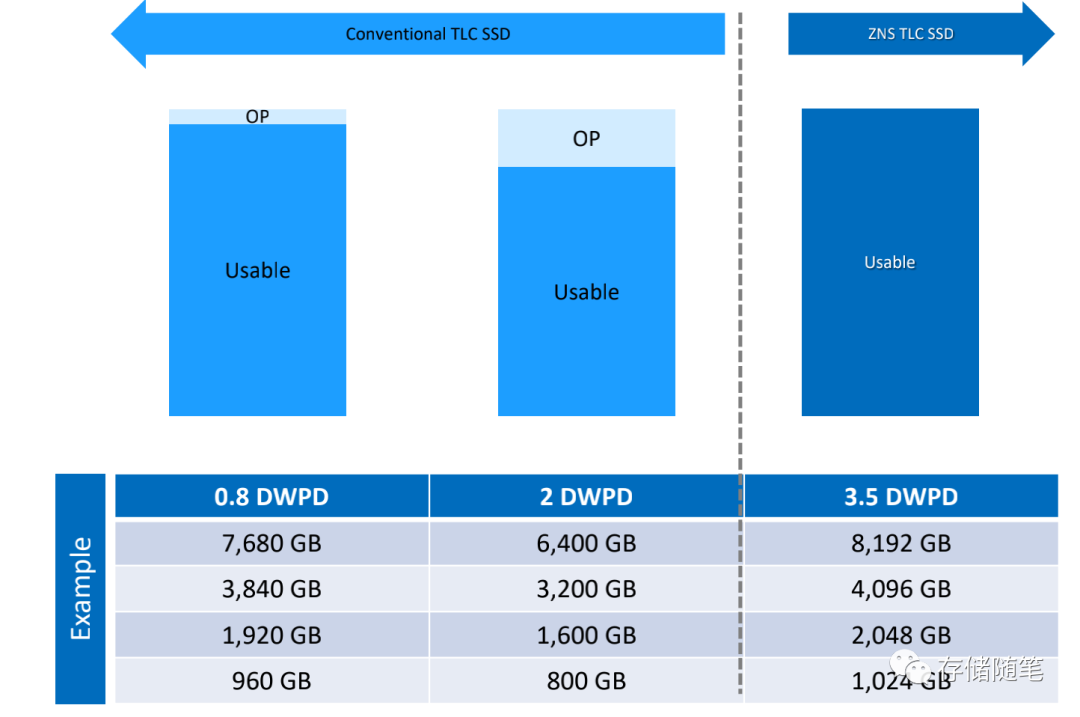
减少SSD的DRAM空间和去掉OP冗余空间,提升用户可用的容量。
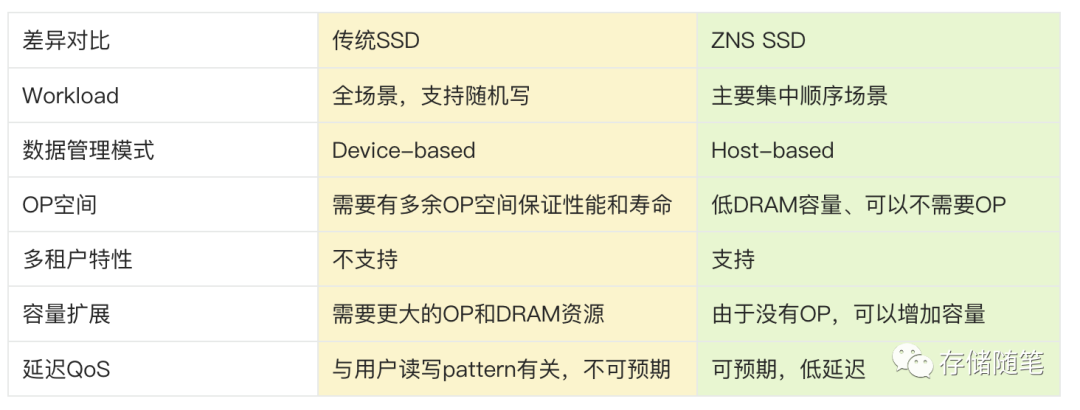
二者具体的优劣对比:
扩展阅读:NVMe SSD:ZNS与FDP对决,你选谁?
这篇关于详解ZNS SSD基本原理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





