本文主要是介绍DirectX11学习笔记十三 进阶的程序框架,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
其实就是Chili Framework,我想从头到尾把框架再梳理一遍,可能不按教程顺序,代码也不是最新的。主要记录思路,有的放矢。
一 从最底层说起
1. Bindable&Codex模式
对于渲染一个最基本的立方体来说,一般最最最简单的步骤是这样的(忽略掉WindowsSDK那些东西):
void Init()
{DXGI_SWAP_CHAIN_DESC sd = {};sd.BufferDesc.Width = 0;sd.BufferDesc.Height = 0;sd.BufferDesc.Format = DXGI_FORMAT_B8G8R8A8_UNORM;sd.BufferDesc.RefreshRate.Numerator = 0;sd.BufferDesc.RefreshRate.Denominator = 0;sd.BufferDesc.Scaling = DXGI_MODE_SCALING_UNSPECIFIED;sd.BufferDesc.ScanlineOrdering = DXGI_MODE_SCANLINE_ORDER_UNSPECIFIED;sd.SampleDesc.Count = 1;sd.SampleDesc.Quality = 0;sd.BufferUsage = DXGI_USAGE_RENDER_TARGET_OUTPUT;sd.BufferCount = 1;sd.OutputWindow = hWnd;sd.Windowed = TRUE;sd.SwapEffect = DXGI_SWAP_EFFECT_DISCARD;sd.Flags = 0;UINT swapCreateFlags = 0u;
#ifndef NDEBUGswapCreateFlags |= D3D11_CREATE_DEVICE_DEBUG;
#endifD3D11CreateDeviceAndSwapChain(nullptr,D3D_DRIVER_TYPE_HARDWARE,nullptr,swapCreateFlags,nullptr,0,D3D11_SDK_VERSION,&sd,pSwap.ReleaseAndGetAddressOf(),pDevice.ReleaseAndGetAddressOf(),nullptr,pContext.ReleaseAndGetAddressOf());// gain access to texture subresource in swap chain (back buffer)wrl::ComPtr<ID3D11Resource> pBackBuffer;pSwap->GetBuffer(0, __uuidof(ID3D11Resource), reinterpret_cast<void**>(pBackBuffer.GetAddressOf()));pDevice->CreateRenderTargetView(pBackBuffer.Get(), nullptr, pTarget.ReleaseAndGetAddressOf());// create depth stensil stateD3D11_DEPTH_STENCIL_DESC dsDesc = {};dsDesc.DepthEnable = TRUE;dsDesc.DepthFunc = D3D11_COMPARISON_LESS;dsDesc.DepthWriteMask = D3D11_DEPTH_WRITE_MASK_ALL;wrl::ComPtr<ID3D11DepthStencilState> pDSState;pDevice->CreateDepthStencilState(&dsDesc, pDSState.GetAddressOf());//bind depth statepContext->OMSetDepthStencilState(pDSState.Get(), 1u);// create depth stensil texturewrl::ComPtr<ID3D11Texture2D> pDepthStencil;D3D11_TEXTURE2D_DESC descDepth = {};descDepth.Width = 800u;descDepth.Height = 600u;descDepth.MipLevels = 1u;descDepth.ArraySize = 1u;descDepth.Format = DXGI_FORMAT_D32_FLOAT;descDepth.SampleDesc.Count = 1u;descDepth.SampleDesc.Quality = 0u;descDepth.Usage = D3D11_USAGE_DEFAULT;descDepth.BindFlags = D3D11_BIND_DEPTH_STENCIL;pDevice->CreateTexture2D(&descDepth, nullptr, pDepthStencil.GetAddressOf());// create view of depth stensil textureCD3D11_DEPTH_STENCIL_VIEW_DESC descDSV = {};descDSV.Format = DXGI_FORMAT_D32_FLOAT;descDSV.ViewDimension = D3D11_DSV_DIMENSION_TEXTURE2D;descDSV.Texture2D.MipSlice = 0u;pDevice->CreateDepthStencilView(pDepthStencil.Get(),&descDSV,&pDSV);// bind depth stensil view to OMpContext->OMSetRenderTargets(1u, pTarget.GetAddressOf(), pDSV.Get());
}void PreBeginFrame()
{// clear bufferconst float color[] = { red,green,blue ,1.0f };pContext->ClearRenderTargetView(pTarget.Get(), color);pContext->ClearDepthStencilView(pDSV.Get(), D3D11_CLEAR_DEPTH, 1.0f, 0u);
}void DrawTestCube(float xAngle, float yAngle, float zAngle, float x, float y,float z)
{namespace wrl = Microsoft::WRL;HRESULT hr;// ********* pixel shader *********wrl::ComPtr<ID3D11PixelShader> pPixelShader;wrl::ComPtr<ID3DBlob> pBlob;D3DReadFileToBlob(L"PixelShader.cso", pBlob.GetAddressOf());pDevice->CreatePixelShader(pBlob->GetBufferPointer(), pBlob->GetBufferSize(), nullptr, pPixelShader.GetAddressOf());pContext->PSSetShader(pPixelShader.Get(), nullptr, 0u);// ********* end pixel shader *********// ********* vertex shader *********wrl::ComPtr<ID3D11VertexShader> pVertexShader;//pBlob.Reset();D3DReadFileToBlob(L"VertexShader.cso", pBlob.GetAddressOf());pDevice->CreateVertexShader(pBlob->GetBufferPointer(), pBlob->GetBufferSize(), nullptr, pVertexShader.GetAddressOf());pContext->VSSetShader(pVertexShader.Get(), nullptr, 0u);// ********* end vertex shader// ********* vertices *********struct VertexPos3{dx::XMFLOAT3 pos;};VertexPos3 vertices[] ={{ dx::XMFLOAT3(-1.0f, -1.0f, -1.0f) },{ dx::XMFLOAT3(-1.0f, 1.0f, -1.0f) },{ dx::XMFLOAT3(1.0f, 1.0f, -1.0f) },{ dx::XMFLOAT3(1.0f, -1.0f, -1.0f) },{ dx::XMFLOAT3(-1.0f, -1.0f, 1.0f) },{ dx::XMFLOAT3(-1.0f, 1.0f, 1.0f) },{ dx::XMFLOAT3(1.0f, 1.0f, 1.0f) },{ dx::XMFLOAT3(1.0f, -1.0f, 1.0f) }};// input layoutwrl::ComPtr<ID3D11InputLayout> pInputLayout;D3D11_INPUT_ELEMENT_DESC ied[] = {{ "POSITION", 0, DXGI_FORMAT_R32G32B32_FLOAT, 0, 0, D3D11_INPUT_PER_VERTEX_DATA, 0 }};pDevice->CreateInputLayout(ied,(UINT)std::size(ied),pBlob->GetBufferPointer(),pBlob->GetBufferSize(),pInputLayout.GetAddressOf());pContext->IASetInputLayout(pInputLayout.Get());// vertex bufferwrl::ComPtr<ID3D11Buffer> pVertexBuffer;D3D11_BUFFER_DESC vbd;vbd.ByteWidth = sizeof(vertices);vbd.Usage = D3D11_USAGE_DEFAULT;vbd.BindFlags = D3D11_BIND_VERTEX_BUFFER;vbd.CPUAccessFlags = 0;vbd.MiscFlags = 0;vbd.StructureByteStride = 8u;D3D11_SUBRESOURCE_DATA vsd = {};vsd.pSysMem = vertices;GFX_THROW_INFO(pDevice->CreateBuffer(&vbd, &vsd, pVertexBuffer.GetAddressOf()));const UINT stride = sizeof(VertexPos3);const UINT offset = 0u;pContext->IASetVertexBuffers(0, 1, pVertexBuffer.GetAddressOf(), &stride, &offset);// ********* end vertex buffer *********// ********* indices *********WORD indices[] = {// 正面0, 1, 2,2, 3, 0,// 左面4, 5, 1,1, 0, 4,// 顶面1, 5, 6,6, 2, 1,// 背面7, 6, 5,5, 4, 7,// 右面3, 2, 6,6, 7, 3,// 底面4, 0, 3,3, 7, 4};// indices bufferwrl::ComPtr<ID3D11Buffer> pIndexBuffer;D3D11_BUFFER_DESC ibd;ibd.ByteWidth = sizeof(indices);ibd.Usage = D3D11_USAGE_IMMUTABLE;ibd.BindFlags = D3D11_BIND_INDEX_BUFFER;ibd.CPUAccessFlags = 0;ibd.MiscFlags = 0;ibd.StructureByteStride = sizeof(WORD);D3D11_SUBRESOURCE_DATA isd = {};isd.pSysMem = indices;pDevice->CreateBuffer(&ibd, &isd, pIndexBuffer.GetAddressOf());pContext->IASetIndexBuffer(pIndexBuffer.Get(), DXGI_FORMAT_R16_UINT, 0);// ********* end indices *********// ********* constant buffer *********// configue constant buffer 1 value for VSstruct ConstantBuffer{dx::XMMATRIX Scale;dx::XMMATRIX Rotation;dx::XMMATRIX Translation;dx::XMMATRIX View;dx::XMMATRIX Projection;};ConstantBuffer cb;cb.Scale = dx::XMMatrixTranspose(dx::XMMatrixIdentity());cb.Rotation = dx::XMMatrixTranspose(dx::XMMatrixRotationX(xAngle) * dx::XMMatrixRotationY(yAngle) * dx::XMMatrixRotationZ(zAngle));cb.Translation = dx::XMMatrixTranspose(dx::XMMatrixTranslation(x, 0, z*4));cb.View = dx::XMMatrixTranspose(dx::XMMatrixLookAtLH(dx::XMVectorSet(0.0f, 0.0f, -5.0f, 0.0f),dx::XMVectorSet(0.0f, 0.0f, 0.0f, 0.0f),dx::XMVectorSet(0.0f, 1.0f, 0.0f, 0.0f)));cb.Projection = dx::XMMatrixTranspose(dx::XMMatrixPerspectiveFovLH(dx::XM_PIDIV2,800.0f / 600.0f,1.0f,1000.0f));wrl::ComPtr<ID3D11Buffer> pConstantBuffer;D3D11_BUFFER_DESC cbd = {};cbd.ByteWidth = sizeof(ConstantBuffer);cbd.Usage = D3D11_USAGE_DYNAMIC;cbd.BindFlags = D3D11_BIND_CONSTANT_BUFFER;cbd.CPUAccessFlags = D3D11_CPU_ACCESS_WRITE;cbd.MiscFlags = 0;D3D11_SUBRESOURCE_DATA csd = {};csd.pSysMem = &cb;GFX_THROW_INFO(pDevice->CreateBuffer(&cbd, &csd, pConstantBuffer.GetAddressOf()));pContext->VSSetConstantBuffers(0, 1, pConstantBuffer.GetAddressOf());// configue constant buffer 2 value for PSstruct ConstantBuffer2{struct{float r, g, b, a;}face_color[6];};const ConstantBuffer2 cb2 ={{{1.0f,0.0f,1.0f},{1.0f,0.0f,0.0f},{0.0f,1.0f,0.0f},{0.0f,0.0f,1.0f},{1.0f,1.0f,0.0f},{0.0f,1.0f,1.0f},}};wrl::ComPtr<ID3D11Buffer> pConstantBuffer2;D3D11_BUFFER_DESC cbd2 = {};cbd2.BindFlags = D3D11_BIND_CONSTANT_BUFFER;cbd2.Usage = D3D11_USAGE_DEFAULT;cbd2.CPUAccessFlags = 0u;cbd2.MiscFlags = 0u;cbd2.ByteWidth = sizeof(cb2);cbd2.StructureByteStride = 0u;D3D11_SUBRESOURCE_DATA csd2 = {};csd2.pSysMem = &cb2;pDevice->CreateBuffer(&cbd2, &csd2, pConstantBuffer2.GetAddressOf());pContext->PSSetConstantBuffers(0, 1, pConstantBuffer2.GetAddressOf());// ********* end constant buffer *********// view portCD3D11_VIEWPORT vp;vp.Width = 800;vp.Height = 600;vp.MinDepth = 0;vp.MaxDepth = 1;vp.TopLeftX = 0;vp.TopLeftY = 0;pContext->RSSetViewports(1u, &vp);// Set primitive topology to triangle list (groups of 3 vertices)pContext->IASetPrimitiveTopology(D3D11_PRIMITIVE_TOPOLOGY_TRIANGLELIST);// drawpContext->DrawIndexed(36,0u, 0u);
}
可以说这是DirectX&OpenGL入门的第一座大山。
可见,基本的套路就是Create&Bind,创建和绑定。所以,可以按照这种套路创建一个Bindable系统,将每个模块(顶点,索引,着色器,etc)封装起来,在类里构造模块的创建、封装方法来绑定到DirectX渲染管线。
对于单Pass渲染框架,我们暂时可以将RenderTarget,DepthStencil等不需要经常更新的模块单独封装到Graphics类,在这个类中处理缓冲区的清除,摄像机设置等操作。
// Graphics.h
private: Microsoft::WRL::ComPtr <ID3D11Device> pDevice;Microsoft::WRL::ComPtr <IDXGISwapChain> pSwap;Microsoft::WRL::ComPtr <ID3D11DeviceContext> pContext;Microsoft::WRL::ComPtr <ID3D11RenderTargetView> pTarget;Microsoft::WRL::ComPtr <ID3D11DepthStencilView> pDSV;
将VertexBuffer,IndexBuffer等经常需要更新的拆开单独封装,全部继承基类Bindable,执行Create&Bind操作。用一个资源字典Codex来存储创建出来的所有Bindable,用字符串做索引。


class Bindable
{public:Bindable() = default;virtual void Bind(Graphics& gfx) noexcept = 0;virtual std::string GetUID() const noexcept // Used to create a key to codex resources{assert(false);return "";}protected:static ID3D11DeviceContext* GetContext(Graphics& gfx) noexcept;static ID3D11Device* GetDevice(Graphics& gfx) noexcept;
};
Codex类是个单例
class Codex{public:template<class T, typename...Params>static std::shared_ptr<T> Resolve(Graphics& gfx, Params&&...p) noxnd{static_assert(std::is_base_of<Bindable, T>::value, "Can only resolve classes derived from Bindable");return Get().Resolve_<T>(gfx, std::forward<Params>(p)...);}private:template<class T, typename...Params>std::shared_ptr<T> Resolve_(Graphics& gfx, Params&&...p) noxnd{const auto key = T::GenerateUID(std::forward<Params>(p)...);const auto i = binds.find(key);if (i == binds.end()){auto bind = std::make_shared<T>(gfx, std::forward<Params>(p)...);binds[key] = bind;return bind;}else{return std::static_pointer_cast<T>(i->second);}}static Codex& Get(){static Codex codex;return codex;}private:std::unordered_map<std::string, std::shared_ptr<Bindable>> binds;};
如果字典中没有资源,则通过传入的变长参数包(必须是构造函数需要的全部参数)来实例化一个新的,并通过索引保存。已经创建过的对象,通过索引取出。索引的创建方法随意,比如文件地址啊,aiMesh的名字啦,或者特效名称啦之类的。
| 资源名 | |
| Blender | |
| VertexBuffer | |
| IndexBuffer | |
| InputLayout | |
| PixelShader | |
| Rasterizer | |
| Sampler | |
| Texture | |
| Topology | |
| TransformCBuf | |
| VertexShader | |
| ConstantBuffer模版 |
-
创建输入布局需要用到指向顶点着色器资源ID3D11VertexShader的ID3DBlob,会产生一点点耦合,写个函数来拿到VS的返回值
-
常量缓冲区中,一般包含经常修改的和不经常修改的,所以将TransformCBuf抽离出来,作为封装了ConstantBuffer的类,包含MVP矩阵信息,每次Draw时更新MVP矩阵并绑定。
-
顶点信息数组或者索引可以用vector.data()获取。
-
Texture的读取流程可以参考Chili的,也可以直接用DirectXTex的,参考DDSTextureLoader和WICTextureLoader(用于加载GIF)
-
所有Bindable的UML图如下(没画Codex)

Drawable代码
class Drawable
{
public:Drawable() = default;Drawable(const Drawable&) = delete;virtual DirectX::XMMATRIX GetTransformXM() const noexcept = 0;void Draw(Graphics& gfx) const noxnd;virtual ~Drawable() = default;template<class T>T* QueryBindable() noexcept // used to get and update constant buffer{for (auto& pb : binds){if (auto pt = dynamic_cast<T*>(pb.get())){return pt;}}return nullptr;}
protected:void AddBind(std::shared_ptr<Bind::Bindable> bind) noxnd;
private:const Bind::IndexBuffer* pIndexBuffer = nullptr;std::vector<std::shared_ptr<Bind::Bindable>> binds; // store all the bindable that we need to bind to the pipeline
};
那么,在这套系统之下,渲染一个plane的代码看起来应该是这样的。
// TestPlane inherit from Drawable
TestPlane::TestPlane(Graphics& gfx, float size)
{using namespace Bind;namespace dx = DirectX;auto model = Plane::Make();model.Transform(dx::XMMatrixScaling(size, size, 1.0f));const auto geometryTag = "$plane." + std::to_string(size);AddBind(VertexBuffer::Resolve(gfx, geometryTag, model.vertices));AddBind(IndexBuffer::Resolve(gfx, geometryTag, model.indices));AddBind(Texture::Resolve(gfx, "Images\\brickwall.jpg"));AddBind(Texture::Resolve(gfx, "Images\\brickwall_normal_obj.png", 2u));auto pvs = VertexShader::Resolve(gfx, "PhongVS.cso");auto pvsbc = pvs->GetBytecode();AddBind(std::move(pvs));AddBind(PixelShader::Resolve(gfx, "PhongPSNormalMapObject.cso"));AddBind(PixelConstantBuffer<PSMaterialConstant>::Resolve(gfx, pmc, 1u));AddBind(InputLayout::Resolve(gfx, model.vertices.GetLayout(), pvsbc));AddBind(Topology::Resolve(gfx, D3D11_PRIMITIVE_TOPOLOGY_TRIANGLELIST));AddBind(std::make_shared<TransformCBufDouble>(gfx, *this, 0u, 2u));
}DirectX::XMMATRIX TestPlane::GetTransformXM() const noexcept
{return DirectX::XMMatrixRotationRollPitchYaw(roll, pitch, yaw) *DirectX::XMMatrixTranslation(pos.x, pos.y, pos.z);
}
在Draw函数中调用所有Bindable的Bind方法,然后IndexDraw即可。
2. 动态顶点缓冲区
给两段代码对比了解一下具体什么意思
// without dynamic vertex bufferstruct Vertex{dx::XMFLOAT3 pos;dx::XMFLOAT3 n;};Assimp::Importer imp;const auto pModel = imp.ReadFile("models\\suzanne.obj",aiProcess_Triangulate |aiProcess_JoinIdenticalVertices);const auto pMesh = pModel->mMeshes[0];std::vector<Vertex> vertices;vertices.reserve(pMesh->mNumVertices);for (unsigned int i = 0; i < pMesh->mNumVertices; i++){vertices.push_back({{ pMesh->mVertices[i].x * scale,pMesh->mVertices[i].y * scale,pMesh->mVertices[i].z * scale },*reinterpret_cast<dx::XMFLOAT3*>(&pMesh->mNormals[i])});}// with dynamic vertex bufferusing hw3dexp::VertexLayout;hw3dexp::VertexBuffer vbuf(std::move(VertexLayout{}.Append(VertexLayout::Position3D).Append(VertexLayout::Normal)));Assimp::Importer imp;const auto pModel = imp.ReadFile("models\\suzanne.obj",aiProcess_Triangulate |aiProcess_JoinIdenticalVertices);const auto pMesh = pModel->mMeshes[0];for (unsigned int i = 0; i < pMesh->mNumVertices; i++){vbuf.EmplaceBack(dx::XMFLOAT3{ pMesh->mVertices[i].x * scale,pMesh->mVertices[i].y * scale,pMesh->mVertices[i].z * scale },*reinterpret_cast<dx::XMFLOAT3*>(&pMesh->mNormals[i]));}
对于一个未知的模型而言,他可能只包含顶点,顶点+法线,或者顶点+法线+UV等等不同的数据组合,而我们要读取并存储模型的数据,则必须要定义多种数据类型,在编译时检查。但是,如果有了动态顶点缓冲区,就可以在运行时动态的调用。并在动态顶点缓冲区中包含InputLayout相关定义。
实现原理:
- reinterpret_cast<>按位拷贝
float占4个字节,char占1个,那么就可以用4个char表示一个float,用reinterpret_cast拷贝即可。按照顶点数据格式,计算offset,用vector存储和读取。
// the simplest code boilerplateauto x = std::make_unique<X>(1.0f);auto xy = std::make_unique<XY>(2.0f, 3.0f); // 1,2,3auto chars = std::vector<char>(sizeof(X) + sizeof(XY));*reinterpret_cast<X*>(chars.data()) = *x; *reinterpret_cast<XY*>(chars.data() + sizeof(X)) = *xy;*x += 20.0f; *xy += 20.0f; // 21,22,23*x = *reinterpret_cast<X*>(chars.data()); *xy = *reinterpret_cast<XY*>(chars.data() + sizeof(X)); // 1,2,3
- 模版递归
c++11引入了可变长模版参数,用法如下,加三个点就行。
如果想要处理一群输入,使用模版参数递归,反复调用自己,每调用一次就取出一个参数,然后将其余的参数作为下一次递归的输入,最后留一个递归收敛函数(所有参数全部取出)。
class Printer
{
public:Printer() = default;template<typename T,typename ...Args>void Print(const T& t,const Args&&... args)const noexcept{std::cout << t << std::endl;Print(args...);}void Print() const noexcept{}
};//usage
printer.Print("1","2","3");
递归的方法有很多,我这里写了一个最好理解的,但其实思想都差不多。
3. 两者结合,new的时候定义号顶点输入布局,再循环从assimp中读取顶点数据,参数可变长。读进来后根据输入布局计算char的offset,依次按位存到vector<char>中,交给DirectX的时候,直接把vector<char>作为data即可。以下是我按照这个思路写的弱智版本。看着来回绕其实自己写一下就能抓住思路了。
class VertexBuffer
{
public:VertexBuffer(VertexLayout vl):vl(std::move(vl)),buf(),index(0){}template<typename T, typename ...Args>void Push(T& t, Args&&... args){PushByIndex(0, t,args...);}
private:const size_t GetNodeOffset(const size_t t){const size_t i = t * vl.GetLayoutSize();return i;}const size_t GetNodeAttOffset(const size_t n, const size_t a){return GetNodeOffset(n) + a * vl.GetAttSize(a);}template<typename T, typename ...Args>void PushByIndex(size_t layoutIndex, T& t, Args&&... args){layoutIndex = layoutIndex % vl.GetLayoutCount();if (layoutIndex == 0)buf.resize(buf.size() + vl.GetLayoutSize());const size_t offset = vl.GetAttOffset(layoutIndex);*reinterpret_cast<T*>(BackNode() + offset) = t;PushByIndex(layoutIndex + 1, std::forward<Args>(args)...);}void PushByIndex(size_t layoutIndex){}char* BackNode(){return buf.data() + buf.size() - vl.GetLayoutSize();}
private:size_t index;VertexLayout vl;std::vector<char> buf;
};class VertexLayout
{
public:VertexLayout() :tv(), layoutSize(0){}VertexLayout& Append(const Type type){tv.emplace_back(type);layoutSize += GetAttSize(type);return *this;}// size of single attconst size_t GetAttSize(const size_t i){switch (tv[i]){case Type::FLOAT: return 1*4;case Type::FLOAT2: return 2*4;default:assert("Parameter attribute type mismatch" && false);}}const size_t GetAttOffset(const int index){size_t offset = 0;for (int i = 0; i < index; i++){offset += GetAttSize(index-1);}return offset;}const size_t GetAttSize(const Type t){switch (t){case Type::FLOAT: return 1;case Type::FLOAT2: return 2;default:assert("Parameter attribute type mismatch" && false);}}// counts of input elementsconst size_t GetLayoutCount(){return tv.size();}// size of single vertexconst size_t GetLayoutSize(){return layoutSize * 4;}
private:std::vector<Type> tv;size_t layoutSize;
};// usageauto vl = VertexLayout().Append(Type::FLOAT).Append(Type::FLOAT2);VertexBuffer vbuf(std::move(vl));for (float i = 1; i < 3.0f; i++){X x(1.0f);XY xy(2.0f, 3.0f);vbuf.Push(x, xy);}
- 既然输入布局在这里都设定好了,那么计算InputLayout也是顺理成章,在这里创建好传给InputLayout即可。
- 绕这么一大圈,为啥不直接用vector<float>?
Wwwwwwwwell,我不知道,Chili也没讲,我想去问,可是之前我问过一次其他的,Chili说去Discord上聊,我这英语可能水平接不上话(虽然英二84),所以如果有大佬好奇这个问题,希望能帮我问一下 😃。
二 Scene Graph/Hierarchy 场景树
就是这么个玩意(图片随手搜的),只是没有图形界面
 ]
]
之前我们渲染一个物体,比如Cube或者Plane,都要给物体单独定义一个类,在里面继承Drawable并定义相关资源。如果物体很多,那就没辙了,这种写法比较适合测试新模块,但不适合渲染大量物体,所以为其单独封装一个类Node。当一个模型内有大量的零件网格时,将其存储成一个个包含Mesh指针的Node(类似unity中的GameObject),并为其设置上下层级关系,特别是Transform的叠加,解决父子类物体的移动关系。
要实现这个框架,首先要明白assimp读取进来的数据格式。
参考assimp官方说明文档(黑科技上网)

图片出处
或者参考CSDN
根据翻译,一个Node包含一个或多个mesh的指针,而mesh在aiScene的aiMesh数组中存储而不是Node。Node只通过数组下标来引用mesh。也就是说,多个node可以指向同一个mesh。node存储mesh的局部坐标系。
aiMesh包括很多数据频道,一定包括的是aiMesh::mVertices和aiMesh::mFaces(包含每个面的索引mFaces[3]),其他的频道可以用其他代码获取。
aiScene还包含aiMaterial信息,用数组存储,每个aiMesh通过数组下标指向对应的aiMaterial。aiMaterial包含纹理等信息。
由此可知,我们可以设计Model、Mesh、Node三个类来管理模型的数据类型。
| 类名 | 用处 |
|---|---|
| Model | 加载存储aiMesh,并存储aiScene的rootNode |
| Mesh | 实际要渲染的顶点数据网格 |
| Node | 指向Mesh,处理坐标变换,Node之间用树形存储 |
- Model是总入口,调用assimp取得本地模型资源,保存成一个个Mesh存到数组中,渲染时循环调用每个Mesh的Draw并计算Transform。
重点是Model是怎么存储Mesh和Node。
Model::Model(Graphics& gfx, const std::string& pathString, const float scale):pWindow(std::make_unique<ModelWindow>())
{Assimp::Importer imp;const auto pScene = imp.ReadFile(pathString.c_str(),aiProcess_Triangulate |aiProcess_JoinIdenticalVertices |aiProcess_ConvertToLeftHanded |aiProcess_GenNormals |aiProcess_CalcTangentSpace);if (pScene == nullptr){throw ModelException(__LINE__, __FILE__, imp.GetErrorString());}for (size_t i = 0; i < pScene->mNumMeshes; i++){meshPtrs.push_back(ParseMesh(gfx, *pScene->mMeshes[i], pScene->mMaterials, pathString, scale));}int nextId = 0;pRoot = ParseNode(nextId, *pScene->mRootNode);
}
Mesh :Mesh集成Drawable,众所周知,Mesh包含的数据是可变化的,可能有法线纹理,也可能只有漫反射纹理,Chili暂时不得不使用了又臭又长的ifelse判断包含的数据然后根据数据类型创建不同的Mesh,大致分为漫反射图,高光(Specular)图,高光强度(Gloss,Specular的aplha值),法线图,漫反射图是否有Alpha通道。
Diffuse,Specular,Normal Map扫盲
一般的判断方法:
if(AI_SUCCESS != mat->Get(<material-key>,<where-to-store>)) {// handle epic failure here}// oraiColor3D color (0.f,0.f,0.f);mat->Get(AI_MATKEY_COLOR_DIFFUSE,color);
根据不同的组合,定义不同的结构体来创建常量缓冲区。
假如要渲染sponza,可能需要多个Shader(Phong光照需要的元素略)
| 顶点着色器 | 用法 |
|---|---|
| PhongVSNotex | 顶点坐标+法线 |
| PhongVS | 顶点坐标+法线+UV |
| PhongVSNormalMap | 顶点坐标+法线+切线+Bitangent(Optional)+UV+ |
| 像素着色器 | 用法 |
|---|---|
| PhongPS | 坐标+法线+UV |
| PhongPSNotex | 坐标+法线 |
| PhongPSSpec | 坐标+法线+UV+漫反射纹理+(高光纹理+高光Gloss(Optional)) |
| PhongPSNormalMap | 坐标+法线+UV+切线+Bitangent(Optional)+漫反射纹理+法线纹理 |
| PhongPSSpecNormalMap | 坐标+法线+切线+Bitangent(Optional)+UV+漫反射纹理+(高光纹理+高光强度(Gloss)(Optional))+法线纹理 |
| PhongPSSpecNormalMask | 同PhongPSSpecNormalMap,主要为了渲染漫反射纹理带透明通道的铁链之类的,当摄像机处在铁链背面时,将法线反转以正确处理光照 |

if (dot(viewNormal, viewFragPos) >= 0.0f){viewNormal = -viewNormal;}
Node:Model只保留Node树的根节点pRoot,用深度优先遍历递归地创建整个树,每个Node节点保留该节点的Transform、名字、id、所指向的mesh指针数组,同时,每个Node还会维护一个子节点的指针数组,作为叶子节点。最后,Node再存一个用于保存坐标变换的修改值AppliedTransform,用于对默认坐标变换做修改。每个子物体的Transform都必须乘上父物体的Transform,以实现父子关系。
// info that a node containsstd::string name;int id;std::vector<std::unique_ptr<Node>> childPtrs;std::vector<Mesh*> meshPtrs;DirectX::XMFLOAT4X4 transform;DirectX::XMFLOAT4X4 appliedTransform;
std::unique_ptr<Node> Model::ParseNode(int& nextId, const aiNode& node) noexcept
{namespace dx = DirectX;const auto transform = dx::XMMatrixTranspose(dx::XMLoadFloat4x4(reinterpret_cast<const dx::XMFLOAT4X4*>(&node.mTransformation)));std::vector<Mesh*> curMeshPtrs;curMeshPtrs.reserve(node.mNumMeshes);// store all needed mesh for renderingfor (size_t i = 0; i < node.mNumMeshes; i++){const auto meshIdx = node.mMeshes[i];curMeshPtrs.push_back(meshPtrs.at(meshIdx).get());}// store all info needed for creating nodeauto pNode = std::make_unique<Node>(nextId++, node.mName.C_Str(), std::move(curMeshPtrs), transform);// loop child node dfsfor (size_t i = 0; i < node.mNumChildren; i++){pNode->AddChild(ParseNode(nextId, *node.mChildren[i]));}return pNode;
}// entry code
pRoot = ParseNode(nextId, *pScene->mRootNode);

2. 调用Draw时,还是以Model为代码入口,首先得到从GUI上设置的坐标变换的修改值,保存到Node的AppliedTransform中,最后调用根节点Node的Draw。根节点Node调用其指向的Mesh的Draw,再调用子Node的Draw,递归地渲染。
3. GUI的管理模式:暂时略
三 动态常量缓冲区 Dynamic Constant Buffer
这一节Chili讲了一个多小时,并作为一种选学的内容,可见其难度和工作量。。。。
用法类似
// old versionstruct PSMaterialConstantDiffuse{float specularIntensity;float specularPower;float padding[2];} pmc;pmc.specularPower = shininess;pmc.specularIntensity = (specularColor.x + specularColor.y + specularColor.z) / 3.0f;// this is CLEARLY an issue... all meshes will share same mat const, but may have different// Ns (specular power) specified for each in the material properties... bad conflictbindablePtrs.push_back(PixelConstantBuffer<PSMaterialConstantDiffuse>::Resolve(gfx, pmc, 1u));// latest versionDcb::RawLayout lay;lay.Add<Dcb::Bool>("normalMapEnabled");lay.Add<Dcb::Bool>("specularMapEnabled");lay.Add<Dcb::Bool>("hasGlossMap");lay.Add<Dcb::Float>("specularPower");lay.Add<Dcb::Float3>("specularColor");lay.Add<Dcb::Float>("specularMapWeight");auto buf = Dcb::Buffer(std::move(lay));buf["normalMapEnabled"] = true;buf["specularMapEnabled"] = true;buf["hasGlossMap"] = hasAlphaGloss;buf["specularPower"] = shininess;buf["specularColor"] = dx::XMFLOAT3{ 0.75f,0.75f,0.75f };buf["specularMapWeight"] = 0.671f;bindablePtrs.push_back(std::make_shared<CachingPixelConstantBufferEX>(gfx, buf, 1u));
好处就是,假如要渲染一个物体,那么就像上面讲的Mesh/Model/Node系统一样,要判断物体的资源里是否包含高光/法线等等就要根据不同的组合定义不同的结构体,而如果我们使用动态常量缓冲区,就可以根据不同的物体资源逐个增加需要的元素即可。
此外,还有个优势是,用imGUI来修改属性参数更方便了
ImGui::Text("Material");if (auto v = mat["normalMapEnabled"]; v.Exists()){dcheck(ImGui::Checkbox("Norm Map", &v));}if (auto v = mat["specularMapEnabled"]; v.Exists()){dcheck(ImGui::Checkbox("Spec Map", &v));}
实现方法:
类图如下:

实现原理跟动态顶点缓冲区有些相似,Buffer使用std::vector作为向GPU端输入的数据,将CPU端的数据通过自己计算offset的方式存储到vector中,自己做16位对齐。
1.Layout和LayoutElement 树形结构常量缓冲区数据格式
然而,必须先创建Layout才能创建Buffer,Layout是LayoutElement的容器,分为RawLayout和CookedLayout。RawLayout只用来创建常量缓冲区的格式,当使用RawLayout创建完Buffer时,RawLayout里的格式根节点会被转存到资源管理器LayoutCodex里并返回CookedLayout,CookedLayout和RawLayout类似只是CookedLayout表示已经固定不能再修改。
LayoutElement即不同的存储的数据元素,Float,Matrix和Bool。同时,LayoutElement还用来标记数据的组织关系,有两种组织关系,结构体(Struct)和数组(Array)。一个常量缓冲区里的数据类型组织关系是逻辑上的树形结构,物理上用vector存储。举个例子:
对于一个刚创建的RawLayout,其保存的数据只有树的根节点LayoutElement,固定是个Struct,同时,每个LayoutElement都可能保存一个ExtraData,用来保存实际的数据类型,Struct型的LayoutElement保存的是StructData,Array型的LayoutElement保存的是ArrayData。
struct ExtraData{struct Struct : public LayoutElement::ExtraDataBase{// vector of std::pair to store all LayoutElement in order of key and value by array instead of map because the improvement of map isnt obviousstd::vector<std::pair<std::string, LayoutElement>> layoutElements;};struct Array : public LayoutElement::ExtraDataBase{// optional as initialized because its actuall type need to be set after being addedstd::optional<LayoutElement> layoutElement;// the length of arraysize_t size;};};struct ExtraDataBase{virtual ~ExtraDataBase() = default;};

这个树里的数据类型是可以嵌套的,比如Struct里再套一个Struct。
如果你看明白了的话,会发现这里存储的只有“数据类型”,而没有数据的值。
对,因为到目前为止,从实际代码的角度来讲,我们只完成了打星号的前两步
Dcb::RawLayout lay;*
lay.Add<Dcb::Bool>("normalMapEnabled");*auto buf = Dcb::Buffer(std::move(lay));
buf["normalMapEnabled"] = true;bindablePtrs.push_back(std::make_shared<CachingPixelConstantBufferEX>(gfx, buf, 1u));
下一步,就是根据格式创建常量缓冲区,并计算offset
2.LayoutCodex 输入格式的资源管理
代码非常少,也很容易理解
class LayoutCodex{public:static Dcb::CookedLayout Resolve(Dcb::RawLayout&& layout) noxnd;private:static LayoutCodex& Get_() noexcept;std::unordered_map<std::string, std::shared_ptr<Dcb::LayoutElement>> map;};
CookedLayout LayoutCodex::Resolve(Dcb::RawLayout&& layout) noxnd{auto sig = layout.GetSignature();auto& map = Get_().map;const auto i = map.find(sig);// idential layout already existsif (i != map.end()){// input layout is expected to be cleared after Resolve// so just throw away the layout treelayout.ClearRoot();return { i->second };}// otherwise add layout root element to mapauto result = map.insert({ std::move(sig),layout.DeliverRoot() });// return layout with additional reference to rootreturn { result.first->second };}LayoutCodex& LayoutCodex::Get_() noexcept{static LayoutCodex codex;return codex;}
麻烦的地方是如何计算每个格式的索引。
计算索引是一个递归的过程,以下图为例。
调用根节点Struct的GetSignature,判断得知当前LayoutElement是个Struct,那么就循环调用根节点pExtraData中所有存储元素的GetSignature,那就是Float的+Float2+Array,判断到Array时得知其类型为Array,就调用Bool的GetSignature。非Array非Struct的直接返回预先定义好的索引片段。
由此可知,当Struct中套Struct或其他复杂情况下,这种递归的调用同样有效。
std::string LayoutElement::GetSignature() const noxnd{switch (type){
#define X(el) case el: return Map<el>::code;LEAF_ELEMENT_TYPES
#undef Xcase Struct:return GetSignatureForStruct();case Array:return GetSignatureForArray();default:assert("Bad type in signature generation" && false);return "???";}}
代码里巧用了宏的知识。
// master list of leaf types that generates enum elements and various switches etc.
#define LEAF_ELEMENT_TYPES \X( Float ) \X( Float2 ) \X( Float3 ) \X( Float4 ) \X( Matrix ) \X( Bool )
下面如果需要用到上面的类型,可以直接宏定义X(input)的内容,缺点是断点没法看。
3.Buffer和ElementRef 基于offset和vector的常量缓冲区
Buffer
LayoutElement除了存一个ExtraData外,还存有offset,用来标记每个数据在vector中的位置。
当使用创建好的输入格式RawLayout创建Buffer时,首先需要将RawLayout的根节点LayoutElement传入Buffer的构造函数中,首先判断LayoutCodex里是否已经存在这个格式,若无则根据LayoutElement根节点创建一个CookedLayout,并调用Finalize()函数。
Finalize()是计算offset的关键。
每个Float的size是4个char,Bool也是4个(非c++的bool),对于每个LayoutElement计算其起始的offset,如果碰到Float-Float2-Float2这种无法24位对齐的情况,则主动将最后的Float2往后延后4位,变成物理上的6个Float。Array类型的单个元素大小*数量。
大体上是这样,但是代码里用了大量的递归,把我绕晕了,不过感觉自己写的话应该不会太难吧。。。
Finalize()之后根据计算出来的offset来初始化vector的大小,接着就可以往里面存数据了。
ElementRef
buf["specularColor"] = dx::XMFLOAT2{ 0.75f,0.75f };
重载[],=和&运算符,赋值时,遍历格式树得到名字为"specularColor"的LayoutElement,根据其保存的offset,通过公式pBytes + offset + resolve得到pBytes起始的位置。pBytes是vector数据缓冲区,offset是Array下标的offset(Struct为0),resolve是改LayoutElement起始的offset,其原理跟动态顶点缓冲区一样。
最后将数据缓冲区提交给GPU即可。
四. MultiPass和渲染队列框架
从这里开始就是渲染器(引擎)里的Meat部分。
MultiPass的好处在高斯模糊描边的博客里写过了。
应用场景举例:
用几何扩大的方法实现物体描边效果,1正常渲染,2设置模版缓冲区,3根据模版和扩大的几何再次渲染。由上面的步骤可知,这是要在一个Drawable里写三个渲染方法。假设在代码中写法:box.Draw1().Draw2().Draw3(),但是如果要实现的效果特别多的话,恐怕自己要崩溃。
相反,实现了MultiPass之后,在渲染整个场景树时,可以先调用所有物体的Pass1,之后再调Pass2,没有的就跳过,大大方便了渲染次序的管理。
但是问题来了,如果有n个Pass,就要递归整个场景树,这很不好,不如一次递归的同时将可能的渲染命令保存到不同的队列中,有n个Pass就对应N个队列。这样就不需要再考虑场景树的渲染次序,只
需要按照渲染队列调用即可。
1.基于数组存储的资源管理模式
 由图可知,需要几个类
由图可知,需要几个类
| 类名 | 描述 |
|---|---|
| Drawable | 保存多个Technique,以及几个不会变动的Bindable资源 |
| Technique | 比如正常渲染\轮廓描边,保存多个Step,这个Technique可以不用,但是用的话读起来更方便 |
| Step | 描述某个渲染的不同步骤,比如对于轮廓描边需要设置模版和实色着色两个Step,保存每个Step单独需要的Bindable,Step描述具体到某一次Draw的Bindable设置 |
| Job | 包含一个Step和对应的Drawable,用于实际的调用一次DrawCall,在Drawable初始化后的Submit()函数中,会遍历每个Technique的所有Step索引,并封装成Job,保存到对应的Pass队列中 |
| Pass | 用数组的形式保存所有Step的索引,有几种用途的Step就需要几个Pass。比如正常渲染1,设置模版2,实色描边3 |
| FrameCommander | 保存多个Pass队列,并在Execute函数中调用每个Pass的渲染入口函数 |
那么问题来了,场景树里的物体Mesh、Node和Model怎么定义呢?
2.改进的场景树
之前设计的动态常量缓冲区可以在这里使用,写个Material类作为中间变量的传递,作为原来的ParseMesh()的替代品。将aiScene的aiMaterial作为参数传入Material的构造函数,在其中定义该模型的Technique和其中的每个Step,每个Step定义的步骤就是添加Bindable。在Mesh的构造函数中传入Material并从中提取需要的数据
除了Technique中要包含的Bindable外,还需要保存顶点缓冲区和索引缓冲区。
索引缓冲区最简单,这个跳过,主要是顶点缓冲区麻烦点。
Technique的部分,代码应该是比较直观了,就是稍微长了点,不过也比之前的代码短多了。
Material::Material(Graphics& gfx, const aiMaterial& material, const std::filesystem::path& path) noxnd:
modelPath(path.string())
{using namespace Bind;const auto rootPath = path.parent_path().string() + "\\";{aiString tempName;material.Get(AI_MATKEY_NAME, tempName);name = tempName.C_Str();}// phong technique{Technique phong{ "Phong" };Step step(0);std::string shaderCode = "Phong";aiString texFileName;// common (pre)vtxLayout.Append(Dvtx::VertexLayout::Position3D);vtxLayout.Append(Dvtx::VertexLayout::Normal);Dcb::RawLayout pscLayout;bool hasTexture = false;bool hasGlossAlpha = false;// diffuse{bool hasAlpha = false;if (material.GetTexture(aiTextureType_DIFFUSE, 0, &texFileName) == aiReturn_SUCCESS){hasTexture = true;shaderCode += "Dif";vtxLayout.Append(Dvtx::VertexLayout::Texture2D);auto tex = Texture::Resolve(gfx, rootPath + texFileName.C_Str());if (tex->HasAlpha()){hasAlpha = true;shaderCode += "Msk";}step.AddBindable(std::move(tex));}else{pscLayout.Add<Dcb::Float3>("materialColor");}step.AddBindable(Rasterizer::Resolve(gfx, hasAlpha));}// specular{if (material.GetTexture(aiTextureType_SPECULAR, 0, &texFileName) == aiReturn_SUCCESS){hasTexture = true;shaderCode += "Spc";vtxLayout.Append(Dvtx::VertexLayout::Texture2D);auto tex = Texture::Resolve(gfx, rootPath + texFileName.C_Str(), 1);hasGlossAlpha = tex->HasAlpha();step.AddBindable(std::move(tex));pscLayout.Add<Dcb::Bool>("useGlossAlpha");pscLayout.Add<Dcb::Bool>("useSpecularMap");}pscLayout.Add<Dcb::Float3>("specularColor");pscLayout.Add<Dcb::Float>("specularWeight");pscLayout.Add<Dcb::Float>("specularGloss");}// normal{if (material.GetTexture(aiTextureType_NORMALS, 0, &texFileName) == aiReturn_SUCCESS){hasTexture = true;shaderCode += "Nrm";vtxLayout.Append(Dvtx::VertexLayout::Texture2D);vtxLayout.Append(Dvtx::VertexLayout::Tangent);vtxLayout.Append(Dvtx::VertexLayout::Bitangent);step.AddBindable(Texture::Resolve(gfx, rootPath + texFileName.C_Str(), 2));pscLayout.Add<Dcb::Bool>("useNormalMap");pscLayout.Add<Dcb::Float>("normalMapWeight");}}// common (post){step.AddBindable(std::make_shared<TransformCbuf>(gfx, 0u));step.AddBindable(Blender::Resolve(gfx, false));auto pvs = VertexShader::Resolve(gfx, shaderCode + "_VS.cso");auto pvsbc = pvs->GetBytecode();step.AddBindable(std::move(pvs));step.AddBindable(PixelShader::Resolve(gfx, shaderCode + "_PS.cso"));step.AddBindable(InputLayout::Resolve(gfx, vtxLayout, pvsbc));if (hasTexture){step.AddBindable(Bind::Sampler::Resolve(gfx));}// PS material params (cbuf)Dcb::Buffer buf{ std::move(pscLayout) };if (auto r = buf["materialColor"]; r.Exists()){aiColor3D color = { 0.45f,0.45f,0.85f };material.Get(AI_MATKEY_COLOR_DIFFUSE, color);r = reinterpret_cast<DirectX::XMFLOAT3&>(color);}buf["useGlossAlpha"].SetIfExists(hasGlossAlpha);buf["useSpecularMap"].SetIfExists(true);if (auto r = buf["specularColor"]; r.Exists()){aiColor3D color = { 0.18f,0.18f,0.18f };material.Get(AI_MATKEY_COLOR_SPECULAR, color);r = reinterpret_cast<DirectX::XMFLOAT3&>(color);}buf["specularWeight"].SetIfExists(1.0f);if (auto r = buf["specularGloss"]; r.Exists()){float gloss = 8.0f;material.Get(AI_MATKEY_SHININESS, gloss);r = gloss;}buf["useNormalMap"].SetIfExists(true);buf["normalMapWeight"].SetIfExists(1.0f);step.AddBindable(std::make_unique<Bind::CachingPixelConstantBufferEx>(gfx, std::move(buf), 1u));}phong.AddStep(std::move(step));techniques.push_back(std::move(phong));}// outline technique{Technique outline("Outline", false);{Step mask(1);auto pvs = VertexShader::Resolve(gfx, "Solid_VS.cso");auto pvsbc = pvs->GetBytecode();mask.AddBindable(std::move(pvs));// TODO: better sub-layout generation tech for future consideration maybemask.AddBindable(InputLayout::Resolve(gfx, vtxLayout, pvsbc));mask.AddBindable(std::make_shared<TransformCbuf>(gfx));// TODO: might need to specify rasterizer when doubled-sided models start being usedoutline.AddStep(std::move(mask));}{Step draw(2);// these can be pass-constant (tricky due to layout issues)auto pvs = VertexShader::Resolve(gfx, "Offset_VS.cso");auto pvsbc = pvs->GetBytecode();draw.AddBindable(std::move(pvs));// this can be pass-constantdraw.AddBindable(PixelShader::Resolve(gfx, "Solid_PS.cso"));{Dcb::RawLayout lay;lay.Add<Dcb::Float3>("materialColor");auto buf = Dcb::Buffer(std::move(lay));buf["materialColor"] = DirectX::XMFLOAT3{ 1.0f,0.4f,0.4f };draw.AddBindable(std::make_shared<Bind::CachingPixelConstantBufferEx>(gfx, buf, 1u));}{Dcb::RawLayout lay;lay.Add<Dcb::Float>("offset");auto buf = Dcb::Buffer(std::move(lay));buf["offset"] = 0.1f;draw.AddBindable(std::make_shared<Bind::CachingVertexConstantBufferEx>(gfx, buf, 1u));}// TODO: better sub-layout generation tech for future consideration maybedraw.AddBindable(InputLayout::Resolve(gfx, vtxLayout, pvsbc));draw.AddBindable(std::make_shared<TransformCbuf>(gfx));// TODO: might need to specify rasterizer when doubled-sided models start being usedoutline.AddStep(std::move(draw));}techniques.push_back(std::move(outline));}
}
有三个需要注意的地方
- 着色器名字shaderCode,这个原理跟第二章类似
- 动态常量缓冲区的应用,这个前面讲过了
- 顶点缓冲区格式的定义vtxLayout
以前动态顶点缓冲区的写法是逐个组合的判断物体可能包含的顶点信息,逐个定义顶点缓冲区并传入数据。
if (hasDiffuseMap && hasNormalMap && hasSpecularMap){Dvtx::VertexBuffer vbuf(std::move(VertexLayout{}.Append(VertexLayout::Position3D).Append(VertexLayout::Normal).Append(VertexLayout::Tangent).Append(VertexLayout::Bitangent).Append(VertexLayout::Texture2D)));for (unsigned int i = 0; i < mesh.mNumVertices; i++){vbuf.EmplaceBack(dx::XMFLOAT3(mesh.mVertices[i].x * scale, mesh.mVertices[i].y * scale, mesh.mVertices[i].z * scale),*reinterpret_cast<dx::XMFLOAT3*>(&mesh.mNormals[i]),*reinterpret_cast<dx::XMFLOAT3*>(&mesh.mTangents[i]),*reinterpret_cast<dx::XMFLOAT3*>(&mesh.mBitangents[i]),*reinterpret_cast<dx::XMFLOAT2*>(&mesh.mTextureCoords[0][i]));}}
现在,顶点缓冲区格式vtxLayout定义成Material的一个字段,通过MakeVertexBindable()函数传递给Mesh。
Drawable::Drawable(Graphics& gfx, const Material& mat, const aiMesh& mesh, float scale) noexcept
{pVertices = mat.MakeVertexBindable(gfx, mesh, scale);pIndices = mat.MakeIndexBindable(gfx, mesh);pTopology = Bind::Topology::Resolve(gfx);for (auto& t : mat.GetTechniques()){AddTechnique(std::move(t));}
}
跟以前的区别就是:以前是先通过各种if的组合唯一的确定所有顶点格式,然后用代码直接传入if对应的数据。现在是先通过零碎的if判断每一个单独的数据格式是否存在,最后通过动态组合起来的格式来动态地从aiMesh中提取数据。
源代码这里绕的厉害,用了模版套宏套模版,可读性极差。。。如果自己写的话,我宁愿循环遍历存在的格式,然后一个个if去从aiMesh中取数据。。。
3.遍历场景树,动态修改想要的信息
比如我想修改某个物体的轮廓颜色,需要找到并读取和修改该物体的Technique。
夸张的讲,比如这个:
复习一下第二章所描述的Scene Graph,Mesh存网格,Node保存部分Mesh的指针,Node之间位树形结构,Model保存所有Mesh组成的数组和Node树的根节点。
目前来说,所有的入口和资源都在Model类中。
假如我想访问"眼睛",并修改"眼睛"的某个常量缓冲区属性,有两种办法
1.1在Model里添加搜索函数,返回“哥布林”这个Node引用
1.2在Node里添加参数的访问修改函数,暴露给外部函数
2.编写一个类Probe类,传入根节点,并递归的向下传递给每一个Node,每到一个Node就访问Node内所包含的Transform和每一个Bindable。
Transform修改起来比较省事,写个Transform字典缓存每个修改后的矩阵,以Node的id为索引。但是需要从已乘完的矩阵中反向提取欧拉角,参考文章。
访问每个Bindable稍微麻烦点,每个Technique和Step都要过一遍,在需要修改的Bindable里重写对应的Accept()方法,分别执行想要的代码。
第二个办法稍微省事
可以尝试写个Probe类,让它能在场景树中的所有元素中传递一遍。(ModelProbe的作用)先遍历所有Node,如果遍历到的Node正是鼠标点击的那一个,就从这个Node入手,(TechniqueProbe的作用)遍历它所有的Step的Bindable,然后执行修改。
五.后处理
之前的笔记有写,基本就是RenderTarget的活用
六.Render Graph
重点中的重点!我写这篇笔记的目的就是想写这个东西
之前的渲染流程都是单线型的,代码也是写死的,流程大概就是用FrameCommander保存并定义好每个Pass的渲染顺序,然后每帧向FrameCommander提交模型类,其中模型类内定义好了每个pass的任务。
然而问题来了,真正要渲染的时候,如果我们想完全取消描边渲染是不可能的,想在runtime中加入其它的pass也是不可能的,因为程序都是在编译时确定的。因此,可以引入渲染图的概念,将每个pass之间的关系切开分成一个一个的渲染流程,并用一个图来连接每个Pass以及其输入和输出。
1.渲染图的理念和组成
以最简单的RenderGraph为例,即只渲染一个方块的流程图。
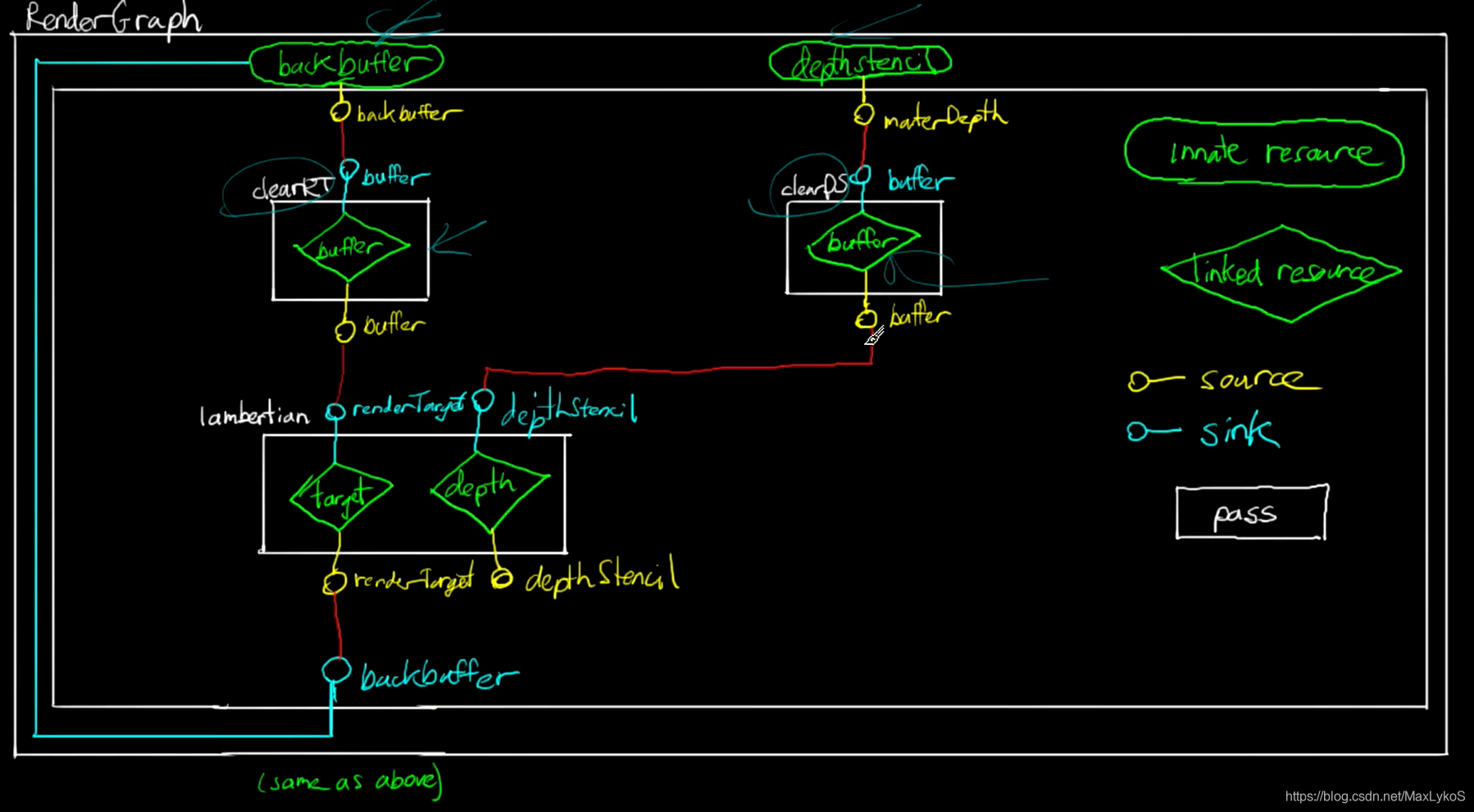
这里就要引入Sink和Source的概念,即一个有向边的起点(sink)和终点(source),分别代表一个Pass的输入和输出,可以有多个sink和source,对于上图中clearRT而言,backbuffer是预先定义好的外部资源并且其sink就是自己并且是globalSink也就是全局sink,clearRT这个pass在定义的时候要实现声明一个sink和source(可以都叫buffer),最后再renderGraph里写程序将clearRT这个Pass的sink与globalSource-backbuffer连接,lambertianPass的sink与clearRT的source-buffer连接,就相当于每帧开始前获取全局RenderTarget,然后清除后交给lambertianPass来处理,其他的以此类推。
1.1 Sink&Source
Sink
其实Sink的组成非常简单,那就是包含三个字符串和一个或多个模版buffer。
不过考虑到其中buffer所指向的对象都是支持多态的子类,因此用模版保存,调用时用std::dynamic_pointer_cast{T}动态转换。

Source
Source类的组成跟Sink类似,Source和Sink就是负责资源传递的过程,区别不是特别大,这里就不贴了。
工作原理
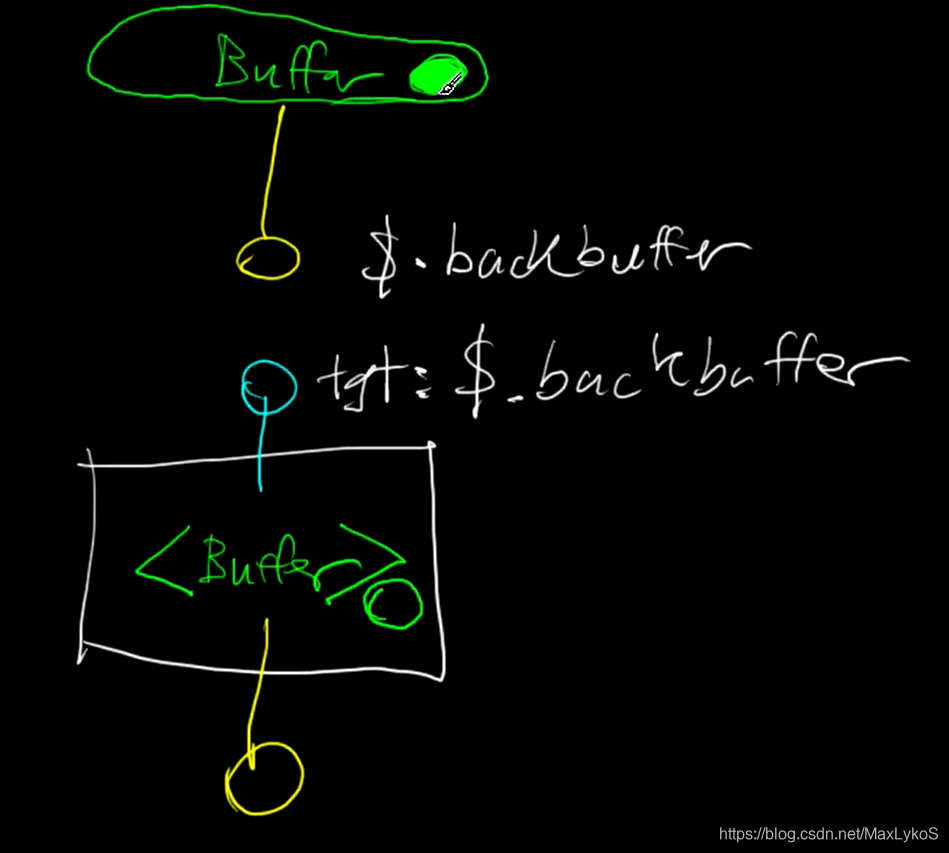
资源分为两种,global和非global,前者保存在RenderGraph中,也就是渲染图最上方2个黄点和最下方一个蓝点,后者定义于每个Pass中,在RenderGraph中通过代码定义连接方式。
上方的buffer可能是RenderGraph里预先定义的外部资源,也可能是上一个Pass,但不管怎么说,这个buffer里存着一个shared_ptr类型的BufferResource,连接渲染图的时候,Pass里的一个或多个Buffer是空的,需要通过Sink&Source从渲染图连接的Buffer中获取资源引用,两者连接的方式是字符串匹配。
最上方Buffer的Source的名字是backbuffer,$表示这个Buffer为Global资源,也就是在RenderGraph里定义的外部资源。下面蓝色的Sink标注的target是&.Backbuffer,也就是最上方黄色的Source,这个Source会搜索全部外部资源的Source然后找到目标Source,执行Bind函数,也就是将Source里的buffer执行std::move()移动到Sink里,而这个Sink自然也是在Pass里注册的,因此自然就相当于Pass里的buffer连接到了外部资源Buffer。这一切都是通过LinkSinks函数调用。
void RenderGraph::LinkSinks(Pass& pass){for (auto& si : pass.GetSinks()){const auto& inputSourcePassName = si->GetPassName();// check check whether target source is globalif (inputSourcePassName == "$"){bool bound = false;for (auto& source : globalSources){if (source->GetName() == si->GetOutputName()){si->Bind(*source);bound = true;break;}}if (!bound){std::ostringstream oss;oss << "Output named [" << si->GetOutputName() << "] not found in globals";throw RGC_EXCEPTION(oss.str());}}else // find source from within existing passes{for (auto& existingPass : passes){if (existingPass->GetName() == inputSourcePassName){auto& source = existingPass->GetSource(si->GetOutputName());si->Bind(source);break;}}}}}
需要注意的是,这里有三种Sink和两种Source。
| Sink子类 | 描述 |
|---|---|
| DirectBufferSink | 保存一个BufferResource索引 |
| ContainerBindableSink | 保存一个Bindable数组的索引和一个下标(int) |
| DirectBindableSink | 保存一个Bindable索引 |
| Source子类 | 描述 |
|---|---|
| DirectBufferSource | 保存一个BufferResource索引 |
| DirectBindableSource | 保存一个Bindable索引 |
BufferResource和Bindable的区别?
事实上,RenderTarget和DepthStencil继承了Bindable和BufferResource,因为这两个都是作为渲染的画布,渲染的顺序是会影响到画布的呈现效果,而Bindable不会,因此将两者区分开。
ContainerBindable的作用
对于BindablePass而言,内部定义的Bindable需要保存在Pass的vector数组中,而众所周知vector的内存是可以重新动态申请的,当超出capacity还要push的时候,vector会重新多申请一半的内存并将之前的内存复制过去,所以之前如果有索引保存了数组中的某个地址,现在会失效。可以测试如下代码。
auto v = std::vector<std::shared_ptr<int>>(1);v[0] = std::make_shared<int>(10);std::shared_ptr<int>& v0_ref = v[0]; std::shared_ptr<int> v0 = v[0];std::cout << *v0 << std::endl; // 10std::cout << *v0_ref << std::endl; // 10for (int i = 0; i < 10; i++)v.emplace_back();*v[0] = 100;std::cout << *v0 << std::endl; // 100std::cout << *v0_ref << std::endl; // cannot display bcs of address invalidation
因此,对于保存数组中的某个指针的索引,ContainerBindable的做法是保存该数组的引用和该指针的下标。具体的调用在AddBindSink()。
1.2 Pass
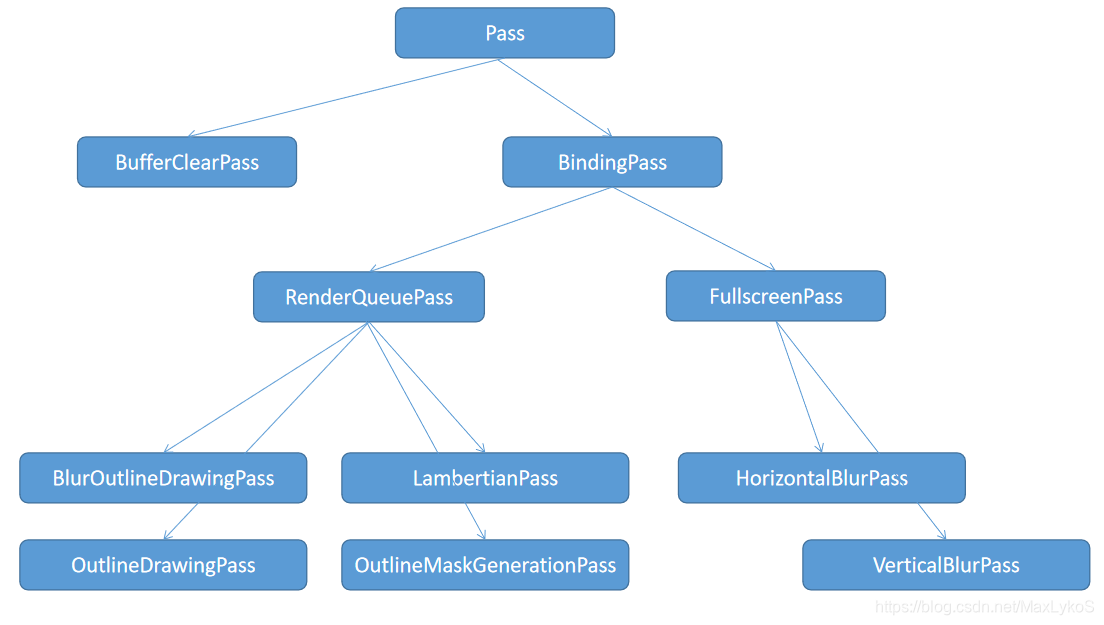
每个Pass的构造函数里定义了需要的Sink和Source,以及一些需要单独用到的Bindable,基本就是比着渲染图和把之前的FrameCommander拆开抄了一遍。
1.3 RenderGraph

再RenderGraph中的构造函数中创建2个globalSource和1个globalSInk。上图所有逻辑关系于BlurOutlineRenderGraph中定义。
pass->SetSinkLinkage(“buffer”, “$.backbuffer”); 表示将该pass的sink"buffer"指向globalSource"backbuffer"。SetSinkLinkage函数只会将sink的目标pass和source记录下来。后面的AppendPass前面说过了,他会将该pass之前用字符串标定的资源搜索并保存索引,然后将pass保存到RenderGraph的vector《Pass》中。
SetSinkTarget()作用一样。
最后Finalize()是确保所有Sink全部完成绑定的一个检查步骤。
{auto pass = std::make_unique<BufferClearPass>("clearRT");pass->SetSinkLinkage("buffer", "$.backbuffer"); AppendPass(std::move(pass));}{auto pass = std::make_unique<BufferClearPass>("clearDS");pass->SetSinkLinkage("buffer", "$.masterDepth");AppendPass(std::move(pass));}{auto pass = std::make_unique<LambertianPass>(gfx, "lambertian");pass->SetSinkLinkage("renderTarget", "clearRT.buffer");pass->SetSinkLinkage("depthStencil", "clearDS.buffer");AppendPass(std::move(pass));}{auto pass = std::make_unique<OutlineMaskGenerationPass>(gfx, "outlineMask");pass->SetSinkLinkage("depthStencil", "lambertian.depthStencil");AppendPass(std::move(pass));}// setup blur constant buffers{{Dcb::RawLayout l;l.Add<Dcb::Integer>("nTaps");l.Add<Dcb::Array>("coefficients");l["coefficients"].Set<Dcb::Float>(maxRadius * 2 + 1);Dcb::Buffer buf{ std::move(l) };blurKernel = std::make_shared<Bind::CachingPixelConstantBufferEx>(gfx, buf, 0);SetKernelGauss(radius, sigma);AddGlobalSource(DirectBindableSource<Bind::CachingPixelConstantBufferEx>::Make("blurKernel", blurKernel));}{Dcb::RawLayout l;l.Add<Dcb::Bool>("isHorizontal");Dcb::Buffer buf{ std::move(l) };blurDirection = std::make_shared<Bind::CachingPixelConstantBufferEx>(gfx, buf, 1);AddGlobalSource(DirectBindableSource<Bind::CachingPixelConstantBufferEx>::Make("blurDirection", blurDirection));}}{auto pass = std::make_unique<BlurOutlineDrawingPass>(gfx, "outlineDraw", gfx.GetWidth(), gfx.GetHeight());AppendPass(std::move(pass));}{auto pass = std::make_unique<HorizontalBlurPass>("horizontal", gfx, gfx.GetWidth(), gfx.GetHeight());pass->SetSinkLinkage("scratchIn", "outlineDraw.scratchOut");pass->SetSinkLinkage("kernel", "$.blurKernel");pass->SetSinkLinkage("direction", "$.blurDirection");AppendPass(std::move(pass));}{auto pass = std::make_unique<VerticalBlurPass>("vertical", gfx);pass->SetSinkLinkage("renderTarget", "lambertian.renderTarget");pass->SetSinkLinkage("depthStencil", "outlineMask.depthStencil");pass->SetSinkLinkage("scratchIn", "horizontal.scratchOut");pass->SetSinkLinkage("kernel", "$.blurKernel");pass->SetSinkLinkage("direction", "$.blurDirection");AppendPass(std::move(pass));}SetSinkTarget("backbuffer", "vertical.renderTarget");Finalize();
2. Job系统的变化
那么问题来了,这里连接的都是rendertarget和depthstencil这两个扮演画布的角色和后处理用的一些辅助变量,那么饰演颜料的要渲染的物体在哪里定义并如何与渲染图交互呢?
对于每个step来说,之前step是保存在Pass数组中的,而对于现在的系统,Step定义的时候需要传入要绑定的Pass字符串名字,然后Link时(只执行一次)搜索出该Pass并保存一个索引到Step中,渲染时调用该Pass索引传入自己。
这篇关于DirectX11学习笔记十三 进阶的程序框架的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







