本文主要是介绍Ubuntu20.04使用cephadm部署ceph集群,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- Requirements
- 环境
- 安装Cephadm
- 部署Ceph单机集群
- 引导(bootstrap)建立新集群
- 管理OSD
- 列出可用的OSD设备
- 部署OSD
- 删除OSD
- 管理主机
- 列出主机信息
- 添加主机到集群
- 从集群中删除主机
- 部署Ceph集群
Cephadm通过在单个主机上创建一个Ceph单机集群,然后向集群中添加主机以扩展集群,进而部署其他服务。
VMware安装Ubuntu20.04并使用Xshell连接虚拟机:https://blog.csdn.net/gengduc/article/details/134889416
Requirements
-
Python3
-
Systemd
-
Podman或Docker
apt install docker.io # 安装docker systemctl status docker.service ## 查看服务运行状态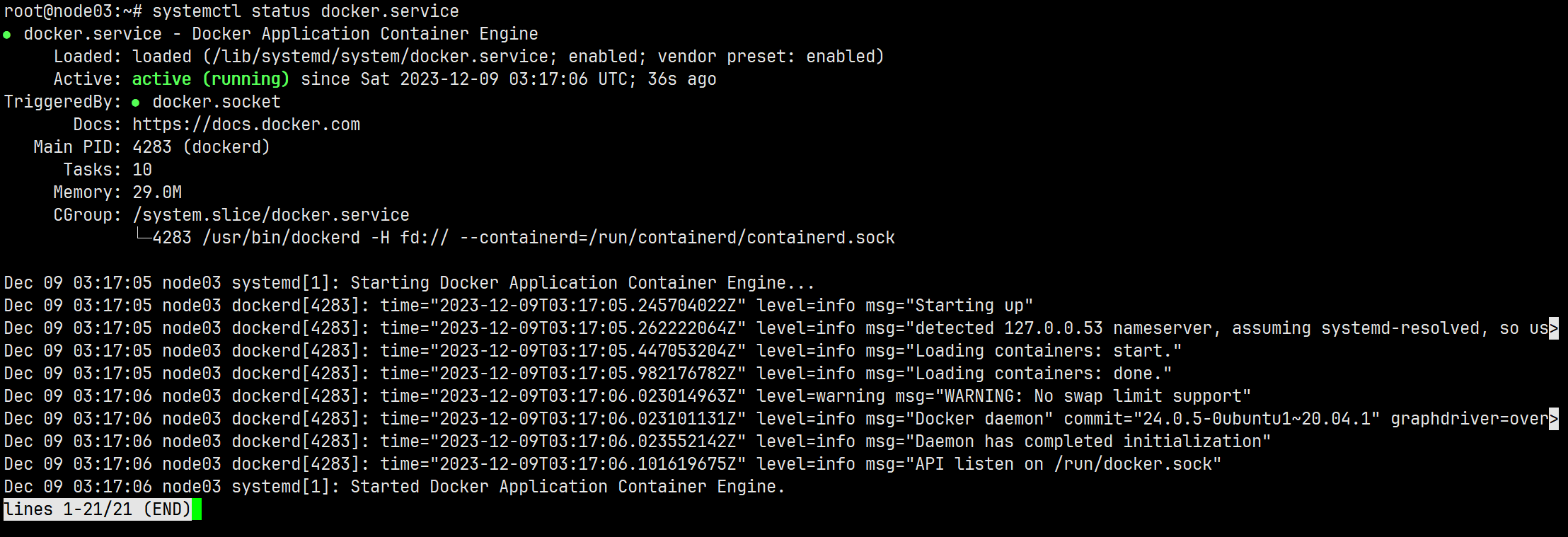
-
时间同步chrony或NTP
apt install chrony systemctl status chronyd.service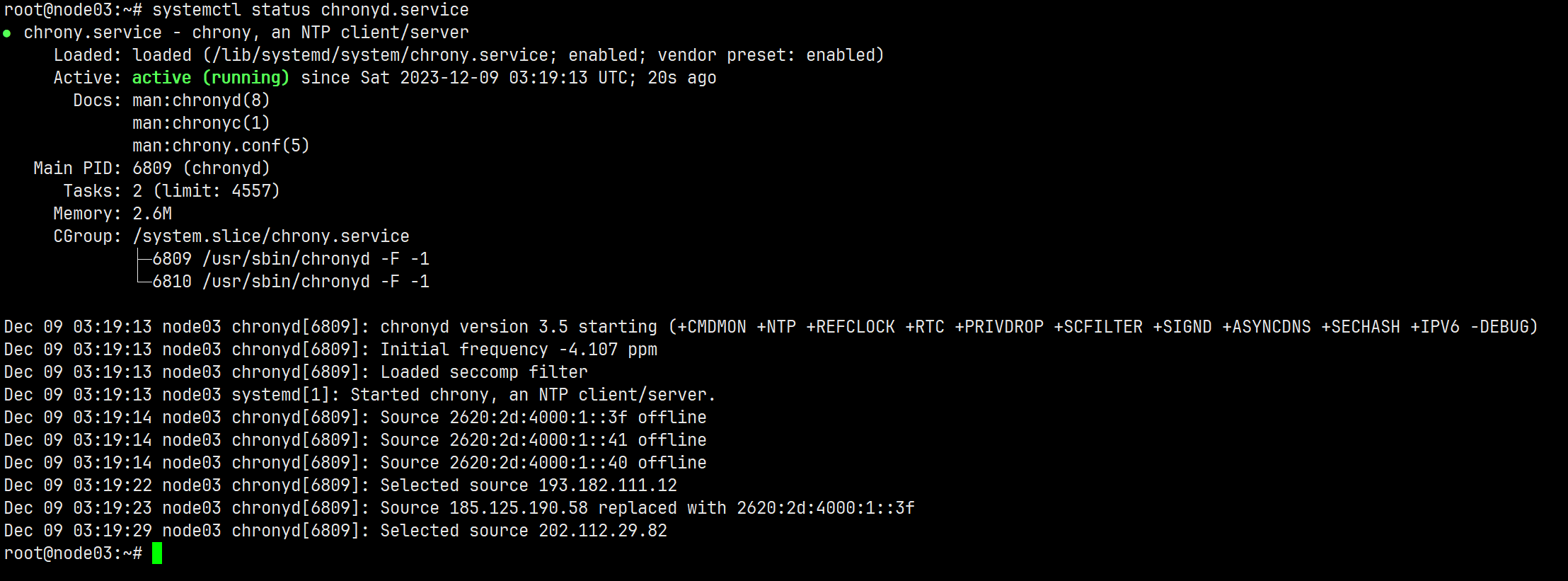
-
LVM2
环境
| 主机名hostname | 硬盘设备 | ip地址 | Ceph服务 |
|---|---|---|---|
| node01 | 一块系统盘/dev/sda、三块用于安装OSD的数据盘/dev/sdb、/dev/sdc、/dev/sdd | 192.168.64.128 | mon×1、mgr×1、osd×3 |
| node02 | 一块系统盘/dev/sda、三块用于安装OSD的数据盘/dev/sdb、/dev/sdc、/dev/sdd | 192.168.64.129 | mon×1、mgr×1、osd×3 |
| node03 | 一块系统盘/dev/sda、三块用于安装OSD的数据盘/dev/sdb、/dev/sdc、/dev/sdd | 192.168.64.130 | mon×1、mgr×1、osd×3 |
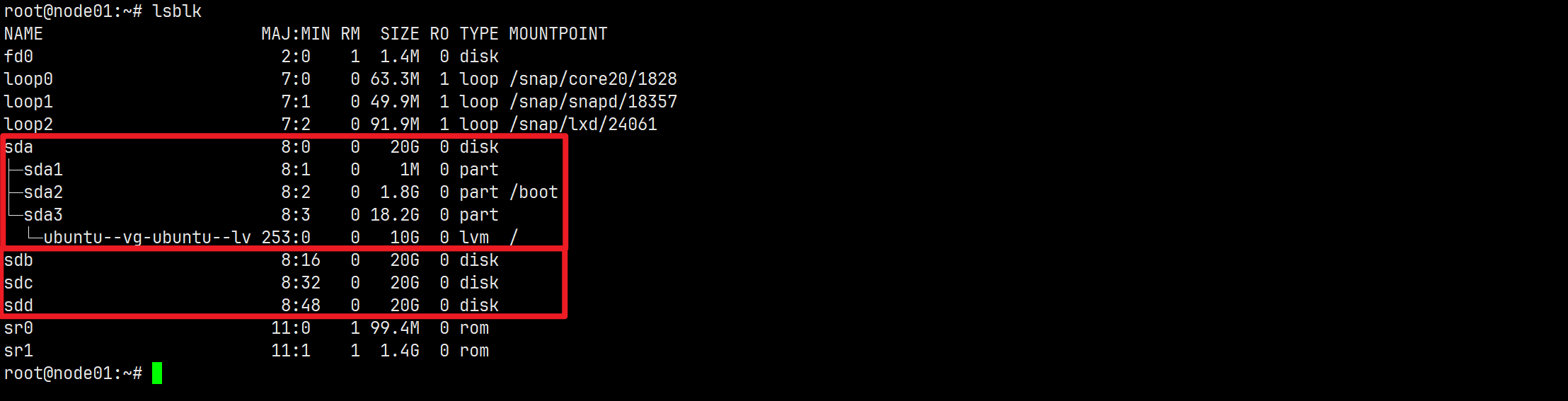
我们将通过cephadm部署Ceph集群,在node01上先部署Ceph单机集群,然后添加node02和node03主机扩展至三台设备集群。
安装Cephadm
【node01执行】
apt install cephadm # 安装cephadm工具whereis cephadm # 检查安装情况
# 输出如下内容
root@node01:~# whereis cephadm
cephadm: /usr/sbin/cephadm
部署Ceph单机集群
引导(bootstrap)建立新集群
Cephadm部署Ceph的方式成为==bootstrap(引导)==。创建新Ceph集群的第一步是在Ceph集群的第一台主机上运行cephadm bootstrap命令。在Ceph集群的第一台主机上运行cephadm bootstrap命令的行为会创建Ceph集群的第一个“监视守护进程”,并且该监视守护进程需要IP地址。您必须将Ceph集群node01的IP地址传递给ceph bootstrap。
cephadm bootstrap --mon-ip <node01的ip地址>
# 例如
cephadm bootstrap --mon-ip 192.168.64.128
root@node01:~# cephadm bootstrap --mon-ip 192.168.64.128
Creating directory /etc/ceph for ceph.conf # 创建配置文件目录
Verifying podman|docker is present... # docker/podman存在
Verifying lvm2 is present... # lvm2存在
Verifying time synchronization is in place... # 时间同步
Unit systemd-timesyncd.service is enabled and running # 时间同步启用并正在运行
Repeating the final host check...
podman|docker (/usr/bin/docker) is present # docker存在
systemctl is present
lvcreate is present
Unit systemd-timesyncd.service is enabled and running
Host looks OK # 主机状态OK
Cluster fsid: 3c6aed32-9644-11ee-b2df-17e04a57112a # 集群fsid,是集群的唯一标识
Verifying IP 192.168.64.128 port 3300 ... # 验证主机端口
Verifying IP 192.168.64.128 port 6789 ...
Mon IP 192.168.64.128 is in CIDR network 192.168.64.0/24 # mon IP地址,及所在网段
Pulling container image quay.io/ceph/ceph:v15... # 拉去ceph镜像
Extracting ceph user uid/gid from container image...
Creating initial keys...
Creating initial monmap...
Creating mon...
Waiting for mon to start... # 等待mon启动
Waiting for mon...
mon is available
Assimilating anything we can from ceph.conf...
Generating new minimal ceph.conf... # 生成集群的最小配置
Restarting the monitor...
Setting mon public_network...
Creating mgr...
Verifying port 9283 ...
Wrote keyring to /etc/ceph/ceph.client.admin.keyring # 生成密钥环
Wrote config to /etc/ceph/ceph.conf # 写入配置
Waiting for mgr to start... # 等待mgr启动
Waiting for mgr...
mgr not available, waiting (1/10)...
mgr not available, waiting (2/10)...
mgr not available, waiting (3/10)...
mgr not available, waiting (4/10)...
mgr not available, waiting (5/10)...
mgr not available, waiting (6/10)...
mgr is available
Enabling cephadm module...
Waiting for the mgr to restart...
Waiting for Mgr epoch 5...
Mgr epoch 5 is available
Setting orchestrator backend to cephadm...
Generating ssh key...
Wrote public SSH key to to /etc/ceph/ceph.pub # 写入SSH密钥到ceph.pub
Adding key to root@localhost's authorized_keys...
Adding host node01...
Deploying mon service with default placement...
Deploying mgr service with default placement...
Deploying crash service with default placement...
Enabling mgr prometheus module...
Deploying prometheus service with default placement...
Deploying grafana service with default placement...
Deploying node-exporter service with default placement...
Deploying alertmanager service with default placement...
Enabling the dashboard module...
Waiting for the mgr to restart...
Waiting for Mgr epoch 13...
Mgr epoch 13 is available
Generating a dashboard self-signed certificate...
Creating initial admin user...
Fetching dashboard port number...
Ceph Dashboard is now available at: # Ceph Dashboard可用URL: https://node01:8443/User: adminPassword: qdnqrh6owzYou can access the Ceph CLI with:sudo /usr/sbin/cephadm shell --fsid 3c6aed32-9644-11ee-b2df-17e04a57112a -c /etc/ceph/ceph.conf -k /etc/ceph/ceph.client.admin.keyringPlease consider enabling telemetry to help improve Ceph:ceph telemetry onFor more information see:https://docs.ceph.com/docs/master/mgr/telemetry/Bootstrap complete. # 引导创建集群完成- 在node01上为新集群创建mon和mgr守护程序。
- 为Ceph集群生成新的SSH密钥,并将其添加到root用户的
/root/.ssh/authorized_keys文件中。 - 将公钥的副本写入
/etc/ceph/ceph.pub。 - 将最小配置文件写入
/etc/ceph/ceph.conf。与集群通信需要此文件。 - 写入
client.admin管理(特权!)密钥/etc/ceph/ceph.client.admin.keyring - 将
_admin标签添加到node01引导主机。默认情况下,任何带有此标签的主机都将(也)获得/etc/ceph/ceph.conf和/etc/ceph/ceph.client.admin.keyring的副本。
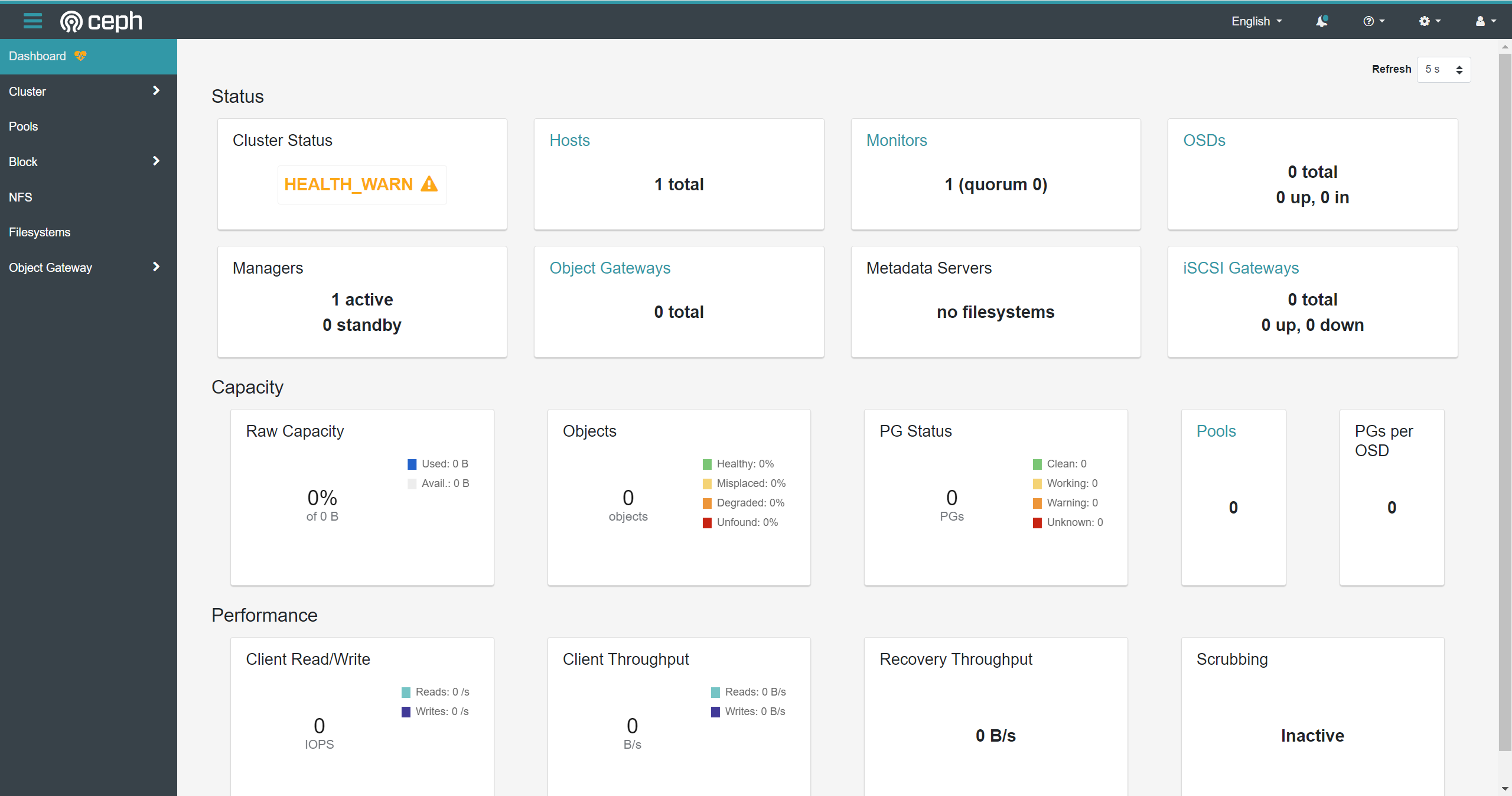
验证:查看集群状态
cephadm类似与进入docker容器的docker exec命令
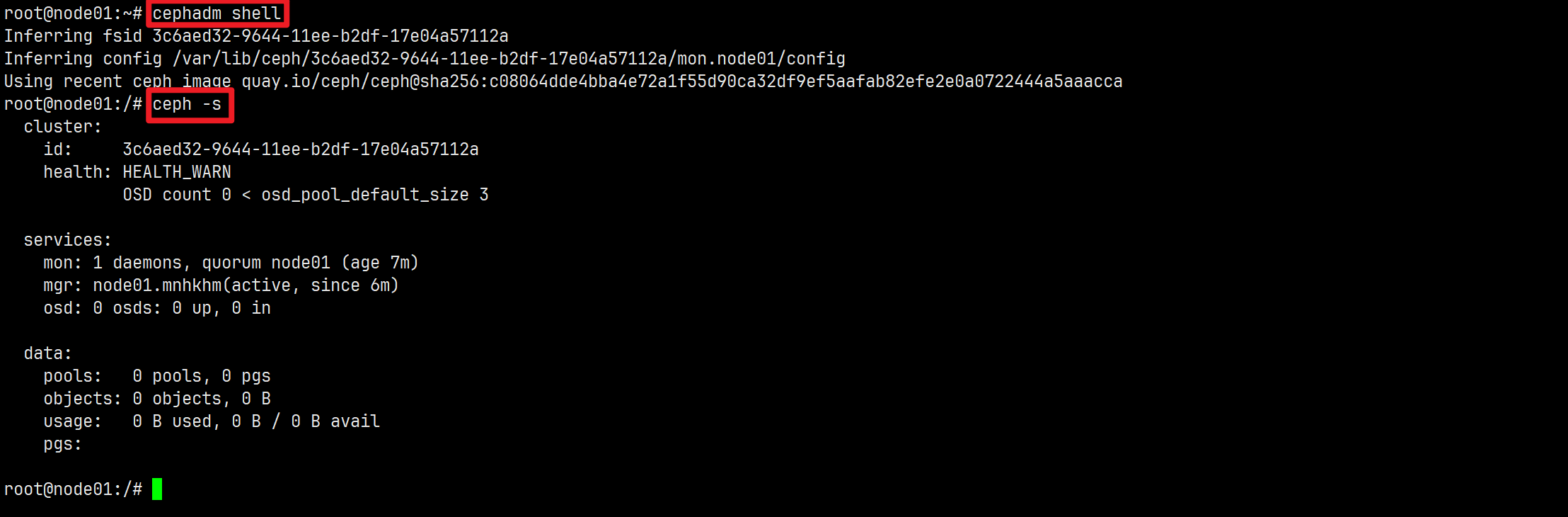
Ceph DashBoard访问地址:https://192.168.64.128:8443。
没有配置本地主机的DNS解析,不要直接使用主机名node01访问)。
管理OSD
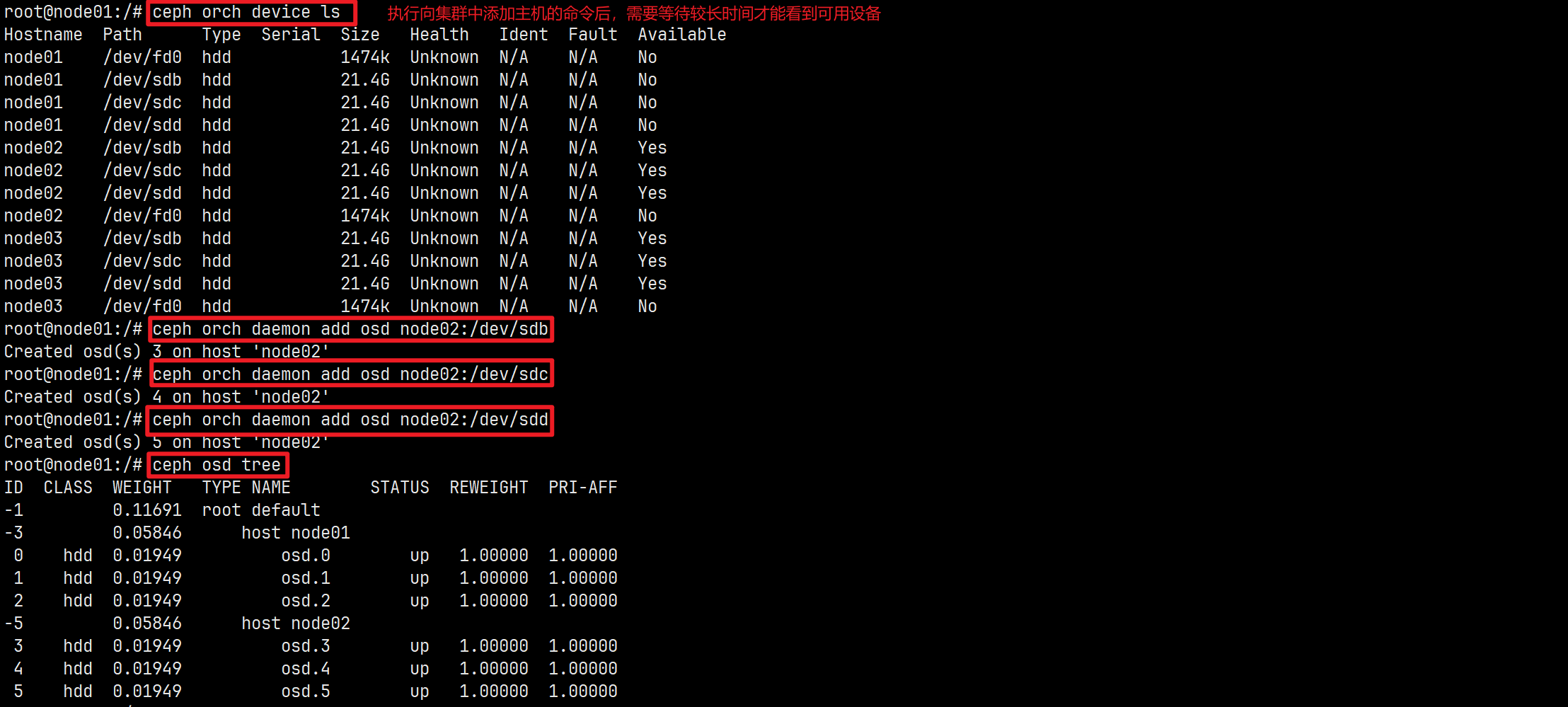
列出可用的OSD设备
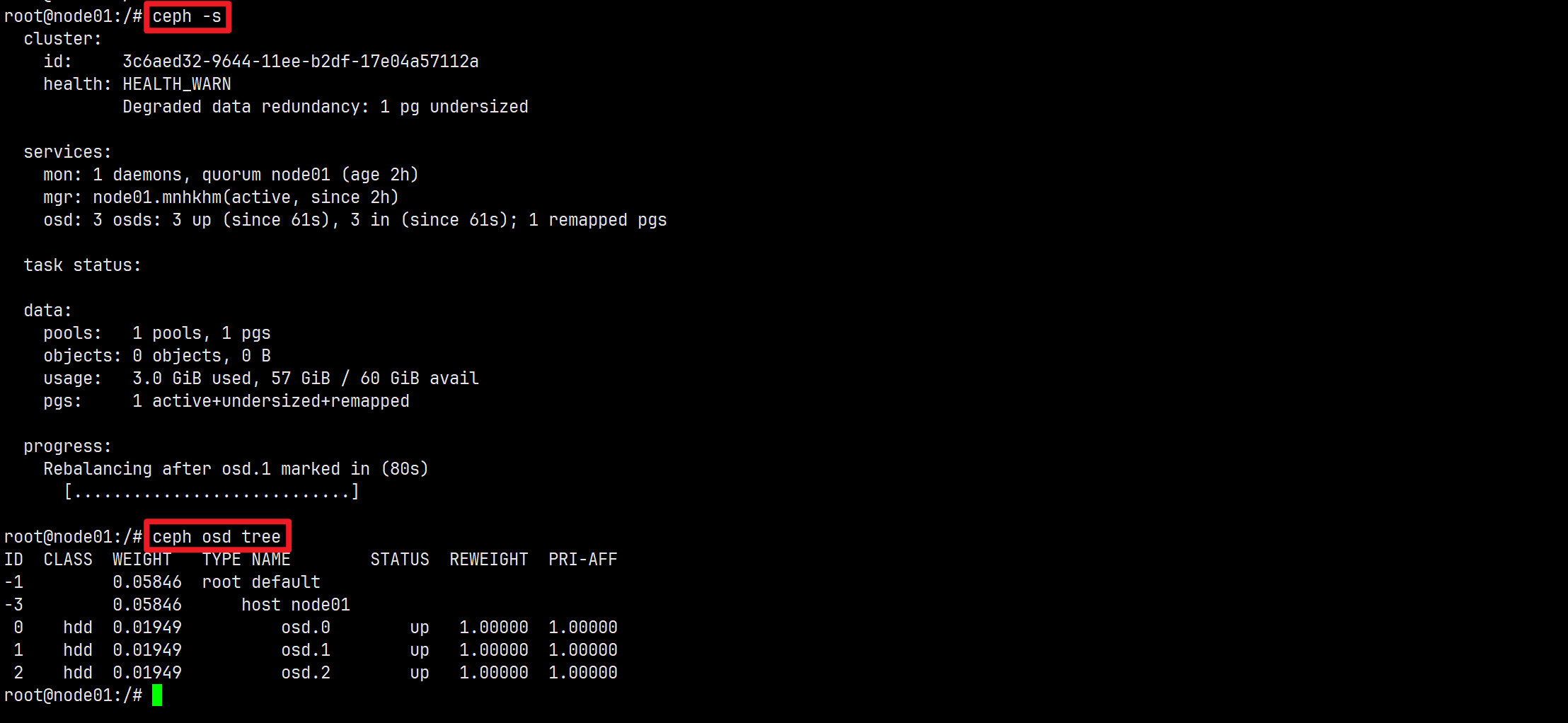
# 查看设备列表,显示可用作OSD的设备
ceph orch device ls [--hostname=...] [--wide] [--refresh]

部署OSD
# 创建新的OSD
ceph orch daemon add osd <host>:<device-path> [--verbose]
root@node01:/# ceph orch daemon add osd node01:/dev/sdb
Created osd(s) 0 on host 'node01'
root@node01:/# ceph orch daemon add osd node01:/dev/sdc
Created osd(s) 1 on host 'node01'
root@node01:/# ceph orch daemon add osd node01:/dev/sdd
Created osd(s) 2 on host 'node01'
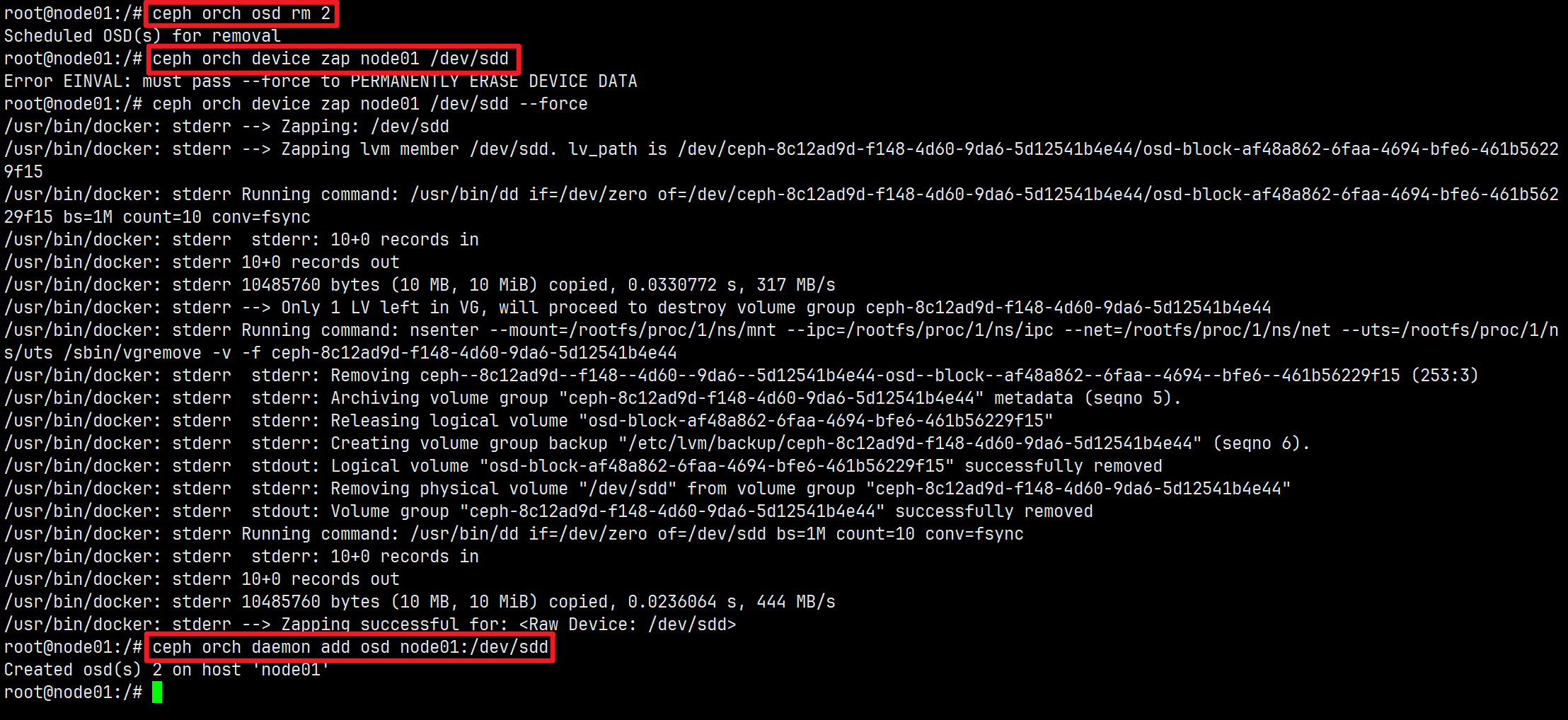
删除OSD
ceph orch osd rm <osd_id(s)> [--replace] [--force] # 删除OSD
ceph orch device zap <hostname> <path> # 擦除设备(清除设备)
管理主机
列出主机信息
ceph orch host ls [--format yaml] [--host-pattern <name>] [--label <label>] [--host-status <status>] [--detail]

添加主机到集群
将新主机添加到集群,两个步骤:
-
在新主机的root用户的
authorized_keys文件中安装群集的公共SSH密钥:ssh-copy-id -f -i /etc/ceph/ceph.pub root@*<new-host>*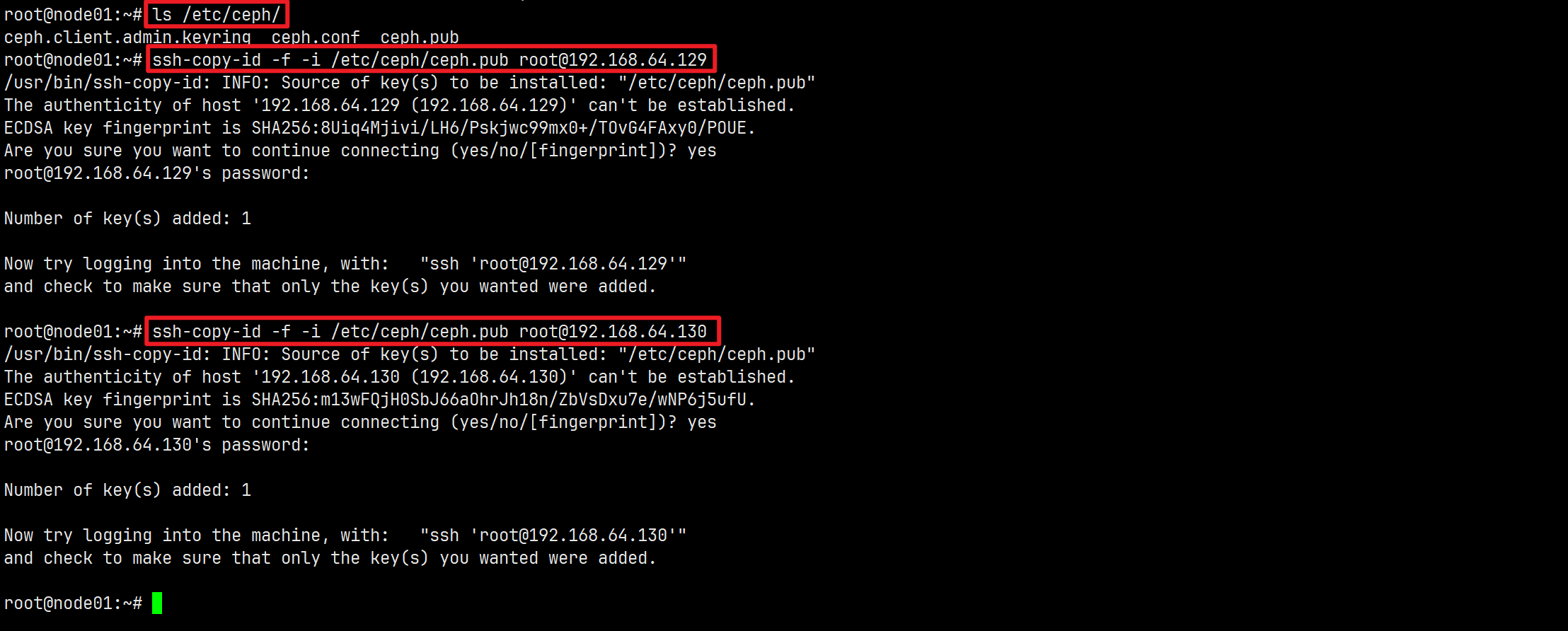
-
告诉Ceph集群新主机是集群的新节点:
ceph orch host add *<newhost>* [*<ip>*] [*<label1> ...*]
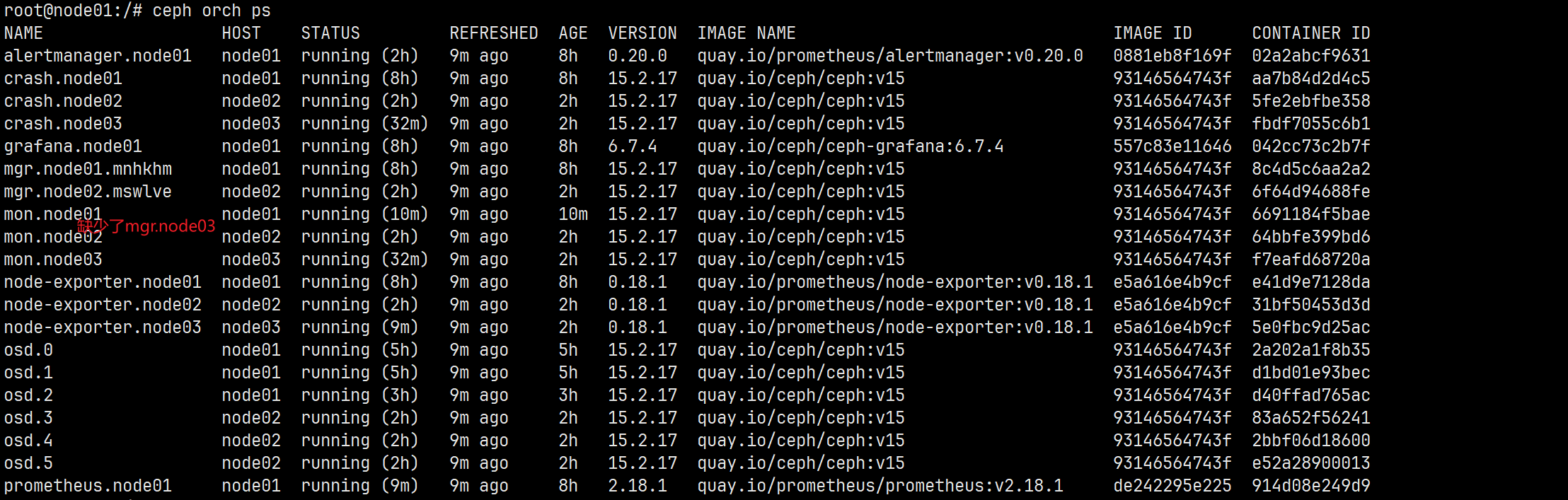
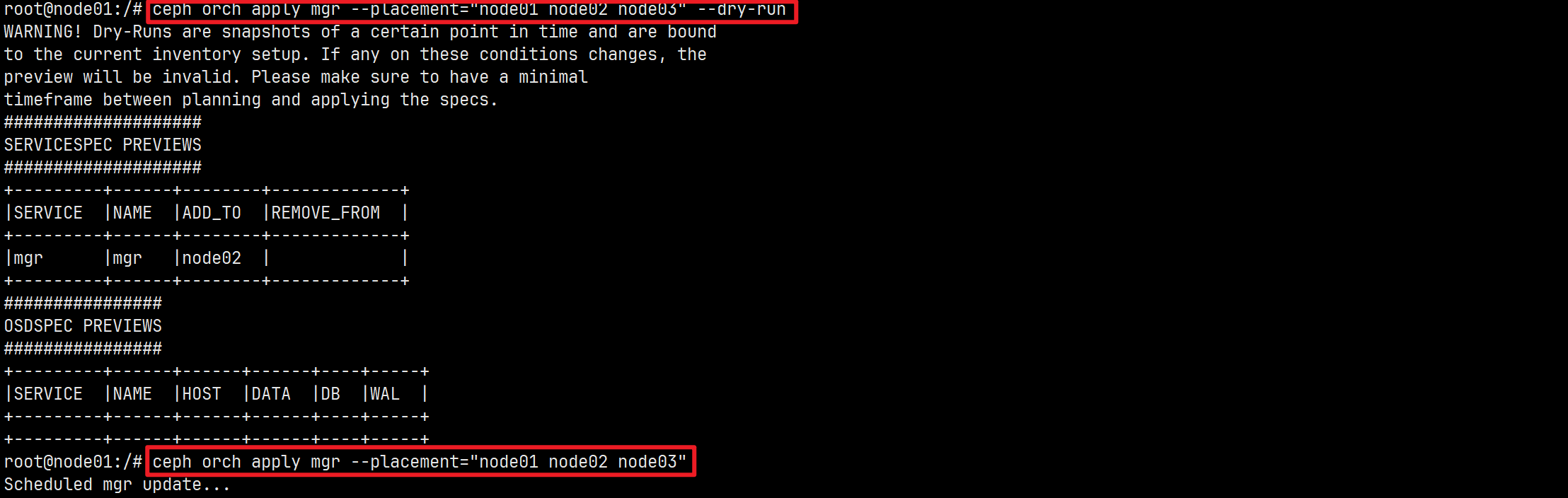
这里在将node03添加进集群的时候,node03节点的mgr服务没有部署成功。重新放置部署。
从集群中删除主机
从主机中删除守护进程后,才可以安全的删除主机。
ceph orch host rm <host> # 从集群中删除主机

部署Ceph集群
按照上面的方法部署三台设备的Ceph集群,步骤如下:
- 使用cephadm bootstrap引导部署Ceph单机集群
- 在引导主机node01上部署OSD
- 向集群中添加主机node02、node03
- 分别在node02和node03上部署OSD
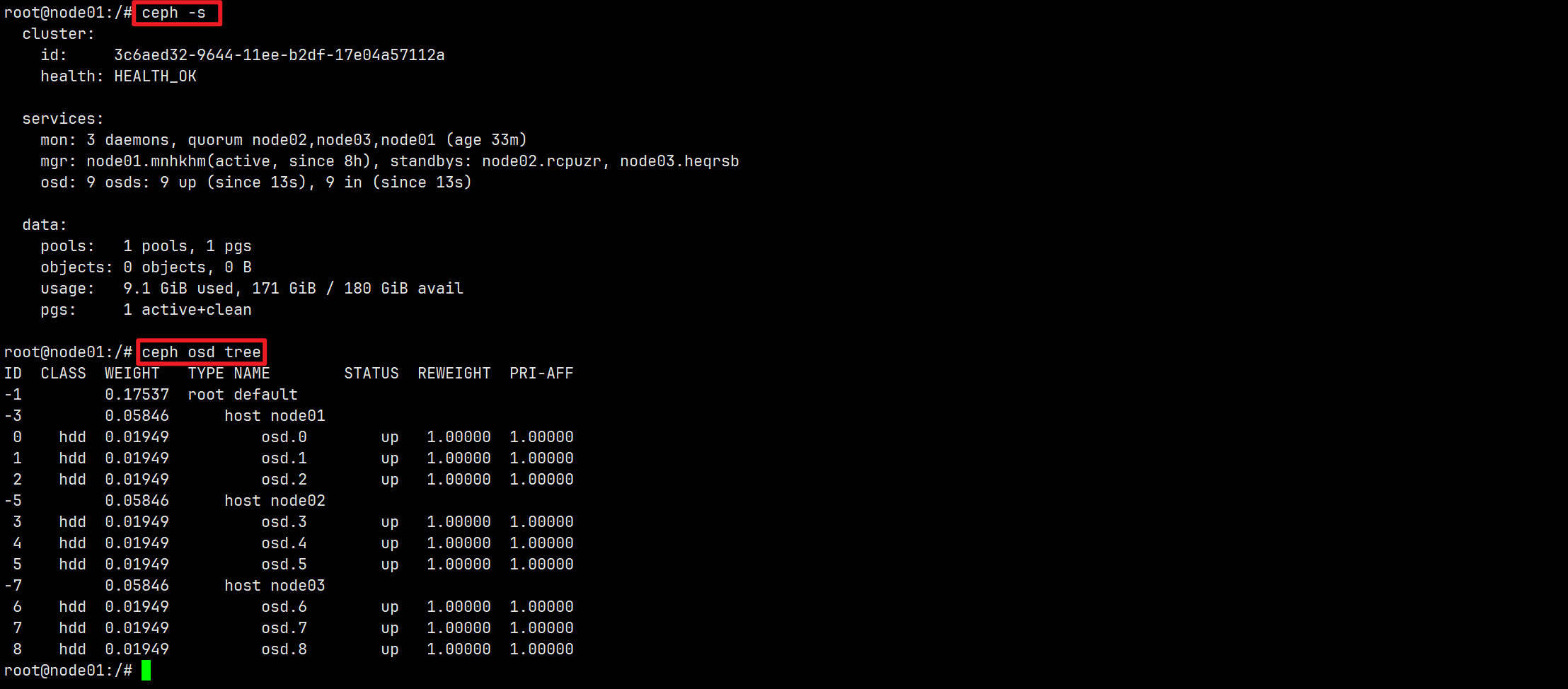
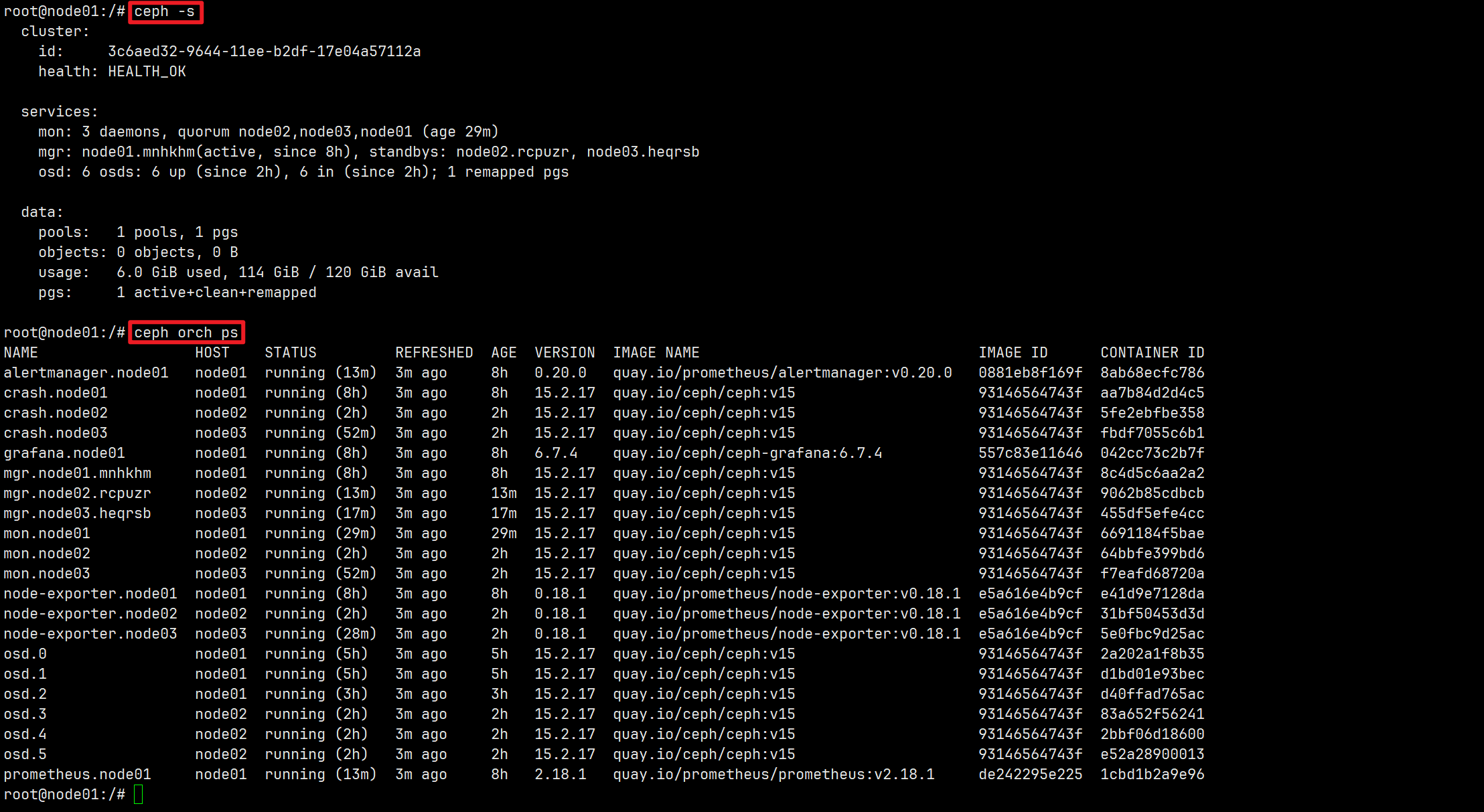
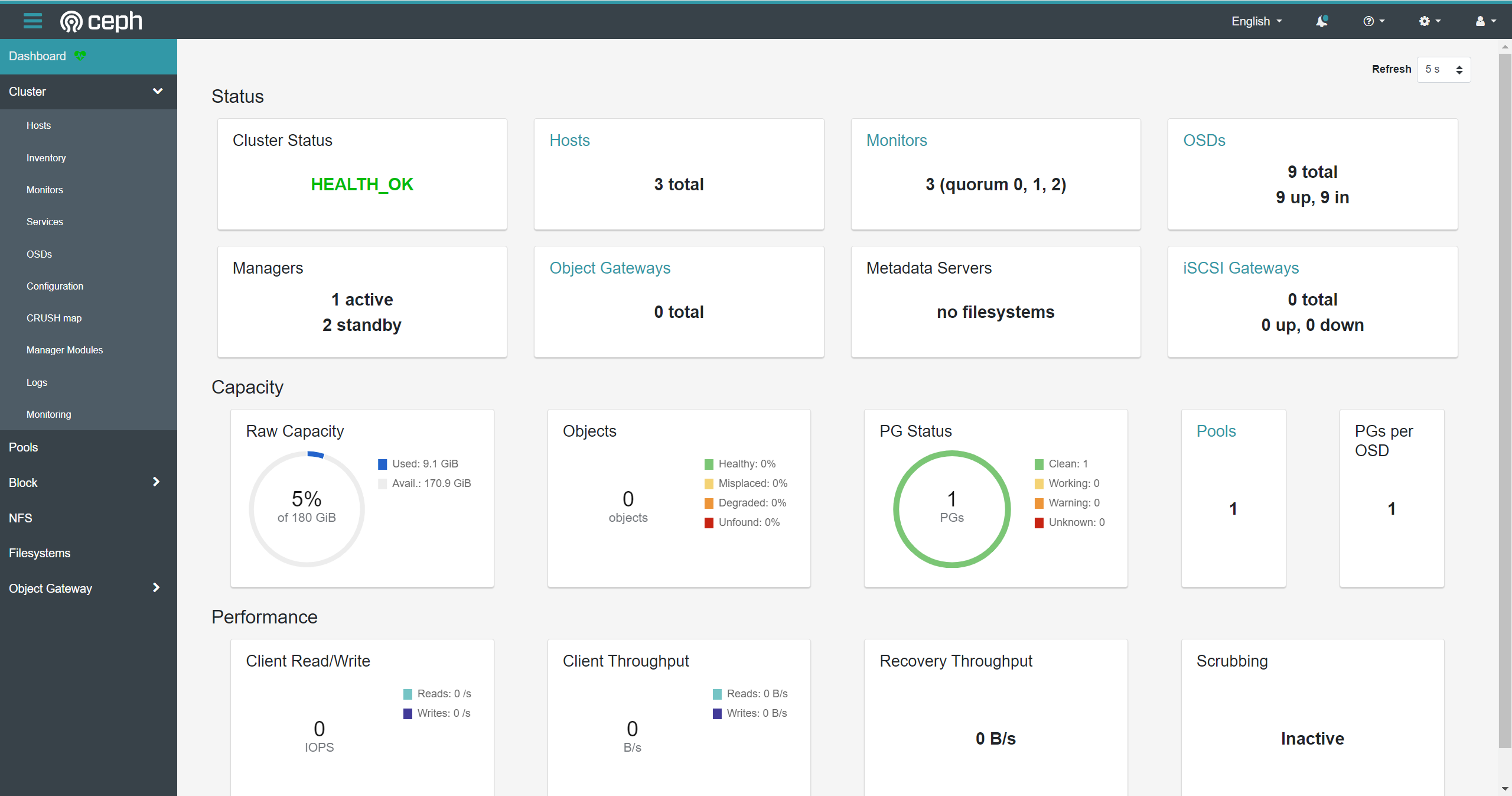
至此,三台设备的集群部署完成!通过Ceph Dashboard查看集群信息。
这篇关于Ubuntu20.04使用cephadm部署ceph集群的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







