本文主要是介绍pta模拟题(C语言7-26 整除光棍、7-27 稳赢、7-28 查验身份证、7-29 出生年、7-30 点赞),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
7-26 整除光棍
这里所谓的“光棍”,并不是指单身汪啦~ 说的是全部由1组成的数字,比如1、11、111、1111等。传说任何一个光棍都能被一个不以5结尾的奇数整除。比如,111111就可以被13整除。 现在,你的程序要读入一个整数
x,这个整数一定是奇数并且不以5结尾。然后,经过计算,输出两个数字:第一个数字s,表示x乘以s是一个光棍,第二个数字n是这个光棍的位数。这样的解当然不是唯一的,题目要求你输出最小的解。提示:一个显然的办法是逐渐增加光棍的位数,直到可以整除
x为止。但难点在于,s可能是个非常大的数 —— 比如,程序输入31,那么就输出3584229390681和15,因为31乘以3584229390681的结果是111111111111111,一共15个1。输入格式:
输入在一行中给出一个不以5结尾的正奇数
x(<1000)。输出格式:
在一行中输出相应的最小的
s和n,其间以1个空格分隔。输入样例:
31输出样例:
3584229390681 15
#include<stdio.h> int main() {int x = 0;scanf("%d",&x);int s = 0;int n = 0;while(s<x){s=s*10+1;n++;}while(1){printf("%d",s/x);s=s%x;if(s==0)break;s=s*10+1;n++;}printf(" %d",n);return 0; }
7-27 稳赢
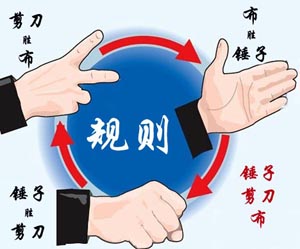
大家应该都会玩“锤子剪刀布”的游戏:两人同时给出手势,胜负规则如图所示:
现要求你编写一个稳赢不输的程序,根据对方的出招,给出对应的赢招。但是!为了不让对方输得太惨,你需要每隔K次就让一个平局。
输入格式:
输入首先在第一行给出正整数K(≤10),即平局间隔的次数。随后每行给出对方的一次出招:
ChuiZi代表“锤子”、JianDao代表“剪刀”、Bu代表“布”。End代表输入结束,这一行不要作为出招处理。输出格式:
对每一个输入的出招,按要求输出稳赢或平局的招式。每招占一行。
输入样例:
2 ChuiZi JianDao Bu JianDao Bu ChuiZi ChuiZi End输出样例:
Bu ChuiZi Bu ChuiZi JianDao ChuiZi Bu
#include<stdio.h> #include <string.h> int main() {int k ,ret = 0;scanf("%d",&k);char s[10]={0};while(scanf("%s",s)){if(strcmp(s,"End")==0)break;if(ret == k){puts(s);ret = 0;}else{if(strcmp(s,"ChuiZi")==0)printf("Bu\n");else if(strcmp(s,"JianDao")==0)printf("ChuiZi\n");elseprintf("JianDao\n");ret++;}}return 0; }
7-28 查验身份证
一个合法的身份证号码由17位地区、日期编号和顺序编号加1位校验码组成。校验码的计算规则如下:
首先对前17位数字加权求和,权重分配为:{7,9,10,5,8,4,2,1,6,3,7,9,10,5,8,4,2};然后将计算的和对11取模得到值
Z;最后按照以下关系对应Z值与校验码M的值:Z:0 1 2 3 4 5 6 7 8 9 10 M:1 0 X 9 8 7 6 5 4 3 2现在给定一些身份证号码,请你验证校验码的有效性,并输出有问题的号码。
输入格式:
输入第一行给出正整数N(≤100)是输入的身份证号码的个数。随后N行,每行给出1个18位身份证号码。
输出格式:
按照输入的顺序每行输出1个有问题的身份证号码。这里并不检验前17位是否合理,只检查前17位是否全为数字且最后1位校验码计算准确。如果所有号码都正常,则输出
All passed。输入样例1:
4 320124198808240056 12010X198901011234 110108196711301866 37070419881216001X输出样例1:
12010X198901011234 110108196711301866 37070419881216001X输入样例2:
2 320124198808240056 110108196711301862输出样例2:
All passed
#include<stdio.h> #include<string.h> int main() {int n =0;scanf("%d",&n);char id[n][19];char cpy[100][19];int weight[] = {7, 9, 10, 5, 8, 4, 2, 1, 6, 3, 7, 9, 10, 5, 8, 4, 2};char M[]={'1', '0', 'X', '9', '8', '7', '6', '5', '4', '3', '2'};int ret = 0;for(int i = 0 ; i < n ; ++i){scanf("%s",id[i]);int sum = 0;int flag = 1;for(int j = 0 ; j < 17 ; ++j){if(id[i][j]<'0'||id[i][j]>'9'){flag = 0;break;}sum += (id[i][j]-'0') * weight[j];}int Z = sum % 11;if(id[i][17] != M[Z]){flag =0;}if(flag == 0){strcpy(cpy[ret++],id[i]);}}if(ret == 0){printf("All passed\n");}else{for(int i =0;i<ret ;++i){printf("%s\n",cpy[i]);}}return 0; }
7-29 出生年
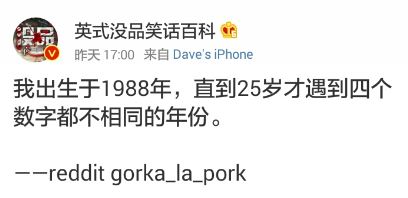
以上是新浪微博中一奇葩贴:“我出生于1988年,直到25岁才遇到4个数字都不相同的年份。”也就是说,直到2013年才达到“4个数字都不相同”的要求。本题请你根据要求,自动填充“我出生于
y年,直到x岁才遇到n个数字都不相同的年份”这句话。输入格式:
输入在一行中给出出生年份
y和目标年份中不同数字的个数n,其中y在[1, 3000]之间,n可以是2、或3、或4。注意不足4位的年份要在前面补零,例如公元1年被认为是0001年,有2个不同的数字0和1。输出格式:
根据输入,输出
x和能达到要求的年份。数字间以1个空格分隔,行首尾不得有多余空格。年份要按4位输出。注意:所谓“n个数字都不相同”是指不同的数字正好是n个。如“2013”被视为满足“4位数字都不同”的条件,但不被视为满足2位或3位数字不同的条件。输入样例1:
1988 4输出样例1:
25 2013输入样例2:
1 2输出样例2:
0 0001
#include<stdio.h> #include<math.h> int a[10]; int main() {int y,n;scanf("%d %d",&y,&n);int l=y;while(1){int c=l;for(int i=1;i<=4;i++){a[c%10]++;c/=10;}int cnt=0;for(int i=0;i<=9;i++)if(a[i]!=0)cnt++;if(cnt==n)break; l++;for(int i=0;i<=9;i++)a[i]=0;}printf("%d %04d",l-y,l); }
7-30 点赞
微博上有个“点赞”功能,你可以为你喜欢的博文点个赞表示支持。每篇博文都有一些刻画其特性的标签,而你点赞的博文的类型,也间接刻画了你的特性。本题就要求你写个程序,通过统计一个人点赞的纪录,分析这个人的特性。
输入格式:
输入在第一行给出一个正整数N(≤1000),是该用户点赞的博文数量。随后N行,每行给出一篇被其点赞的博文的特性描述,格式为“K F1⋯FK”,其中1≤K≤10,Fi(i=1,⋯,K)是特性标签的编号,我们将所有特性标签从1到1000编号。数字间以空格分隔。
输出格式:
统计所有被点赞的博文中最常出现的那个特性标签,在一行中输出它的编号和出现次数,数字间隔1个空格。如果有并列,则输出编号最大的那个。
输入样例:
4 3 889 233 2 5 100 3 233 2 73 4 3 73 889 2 2 233 123输出样例:
233 3
#include <stdio.h>int main( ) {int n = 0; int i = 0; int x = 0; int j = 0; int num = 0;int shuzi = 0;int a = 0;int y[1001] = {0};scanf("%d\n",&n);for(i = 0;i<n;i++){scanf("%d\n",&x);for(j = 0;j < x;j++){scanf("%d",&num);y[num]++;}}for(i = 1;i<=1000;i++){if(a <= y[i]){a = y[i];shuzi = i;}}printf("%d %d\n",shuzi,a);return 0; }/* #include <stdio.h> int main(){int n, i, j, k, num;int max = 0, maxpos = 1000;int arr[1001] = {0};scanf("%d", &n);for (i=0; i<n; i++){scanf("%d", &k);for (j=0; j<k; j++){scanf("%d", &num);arr[num]++;}}for (i=1000; i>0; i--){if (arr[i] > max){max = arr[i];maxpos = i;}}printf("%d %d", maxpos, max);return 0; } */
这篇关于pta模拟题(C语言7-26 整除光棍、7-27 稳赢、7-28 查验身份证、7-29 出生年、7-30 点赞)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






