本文主要是介绍mysql 主从搭建、django实现读写分离、django中多redis缓存、django中使用连接池、pycharm远程linux开发,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1 mysql 主从搭建
2 django实现读写分离
3 django中多redis缓存
4 django中使用连接池
5 pycharm远程linux开发
1 mysql 主从搭建
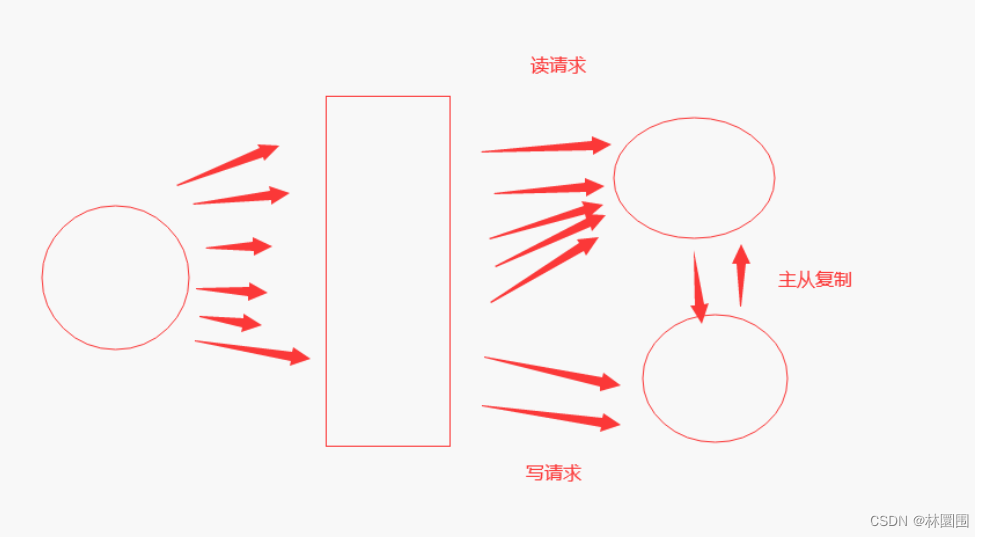
# 之前做过redis的主从,很简单# mysql 稍微复杂一些, 搭建mysql主从的目的是?-读写分离-单个实例并发量低,提高并发量-只在主库写,读数据都去从库# 原理
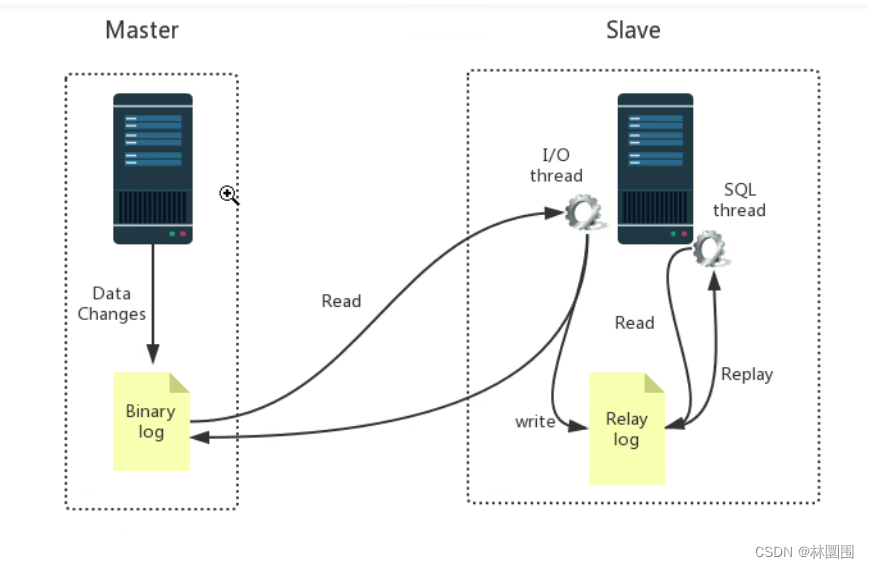
MySQL服务器之间的主从同步是基于二进制日志机制(binlog),主服务器使用二进制日志来(binlog)记录数据库的变动情况,从服务器通过读取和执行该日志文件来保持和主服务器的数据一致# mysql 主从原理
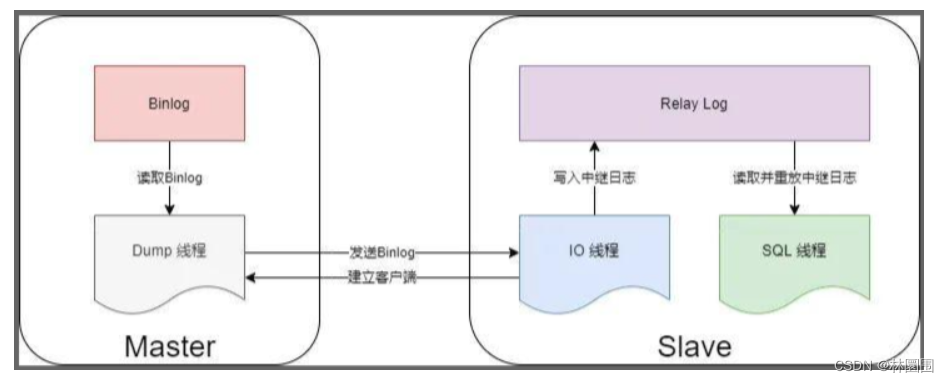
步骤一:主库db的更新事件(update、insert、delete)被写到binlog
步骤二:从库发起连接,连接到主库
步骤三:此时主库创建一个binlog dump thread线程,把binlog的内容发送到从库
步骤四:从库启动之后,创建一个I/O线程,读取主库传过来的binlog内容并写入到relay log.
步骤五:还会创建一个SQL线程,从relay log里面读取内容,从Exec_Master_Log_Pos位置开始执行读取到的更新事件,将更新内容写入到slave的db.# 搭建步骤 :准备两台机器 (mysql的docker镜像模拟两台机器)-主库:10.0.0.101 33307-从库:10.0.0.101 33306# 第一步:拉取mysql5.7的镜像# 第二步:创建文件夹,文件(目录映射)mkdir /home/mysqlmkdir /home/mysql/conf.dmkdir /home/mysql/data/touch /home/mysql/my.cnfmkdir /home/mysql1mkdir /home/mysql1/conf.dmkdir /home/mysql1/data/touch /home/mysql1/my.cnf# 第三步(重要):编写mysql配置文件(主,从)#### 主的配置####[mysqld]user=mysqlcharacter-set-server=utf8default_authentication_plugin=mysql_native_passwordsecure_file_priv=/var/lib/mysqlexpire_logs_days=7sql_mode=STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTIONmax_connections=1000server-id=100log-bin=mysql-bin[client]default-character-set=utf8[mysql]default-character-set=utf8#### 从库的配置#####[mysqld]user=mysqlcharacter-set-server=utf8default_authentication_plugin=mysql_native_passwordsecure_file_priv=/var/lib/mysqlexpire_logs_days=7sql_mode=STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTIONmax_connections=1000server-id=101 log-bin=mysql-slave-bin relay_log=edu-mysql-relay-bin [client]default-character-set=utf8[mysql]default-character-set=utf8#第三步:启动mysql容器,并做端口和目录映射docker run -di -v /home/mysql/data/:/var/lib/mysql -v /home/mysql/conf.d:/etc/mysql/conf.d -v /home/mysql/my.cnf:/etc/mysql/my.cnf -p 33307:3306 --name mysql-master -e MYSQL_ROOT_PASSWORD=123456 mysql:5.7docker run -di -v /home/mysql1/data/:/var/lib/mysql -v /home/mysql1/conf.d:/etc/mysql/conf.d -v /home/mysql1/my.cnf:/etc/mysql/my.cnf -p 33306:3306 --name mysql-slave -e MYSQL_ROOT_PASSWORD=123456 mysql:5.7#第四步:连接主库mysql -uroot -P33307 -h 10.0.0.101 -p#在主库创建用户并授权##创建test用户create user 'test'@'%' identified by '123';##授权用户grant all privileges on *.* to 'test'@'%' ;###刷新权限flush privileges;#查看主服务器状态(显示如下图)show master status; # 第五步:连接从库mysql -uroot -P33306 -h 10.0.0.102 -p#配置详解'''change master to master_host='MySQL主服务器IP地址', master_user='之前在MySQL主服务器上面创建的用户名', master_password='之前创建的密码', master_log_file='MySQL主服务器状态中的二进制文件名', master_log_pos='MySQL主服务器状态中的position值';'''
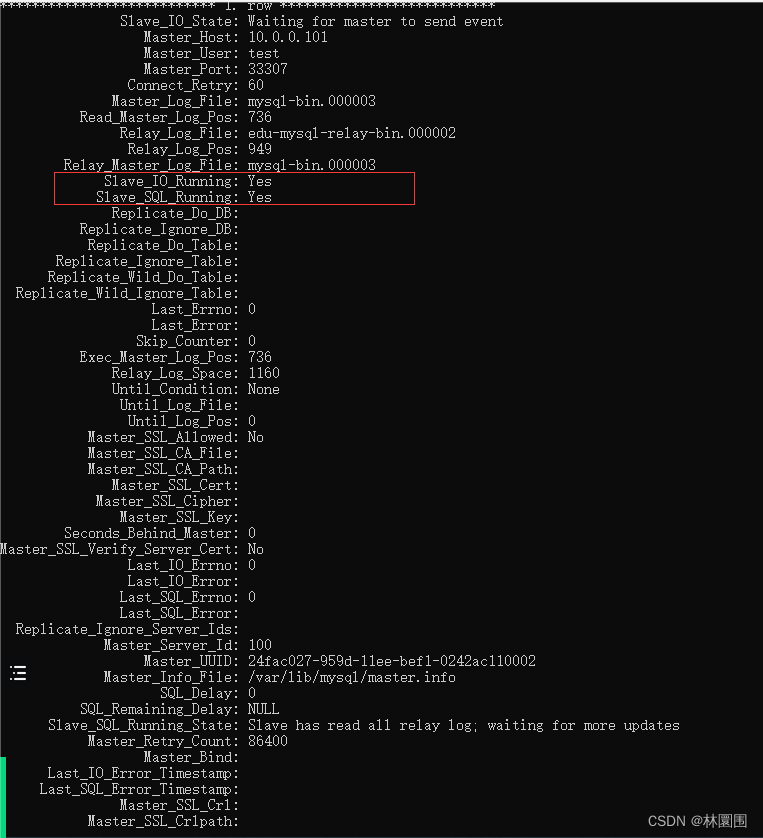
change master to master_host='10.0.0.101',master_port=33307,master_user='test',master_password='123',master_log_file='mysql-bin.000003',master_log_pos=0;#启用从库start slave;#查看从库状态(如下图)show slave status\G;# 第六版:在主库创建库,创建表,插入数据,看从库

2 django实现读写分离
# 第一步:配置文件配置多数据库
DATABASES = {'default': {'ENGINE': 'django.db.backends.sqlite3','NAME': BASE_DIR / 'db.sqlite3',},'db1': {'ENGINE': 'django.db.backends.sqlite3','NAME': BASE_DIR / 'db1.sqlite3',}
}# 迁移表时,可以指定迁到哪个库中
migrate --database=配置文件中数据库配置的名字 # 不写默认迁移到default# 第二步:手动读写分离
Book.objects.using('db1').create(name='西游记')# 第三步,自动读写分离
写一个py文件,db_router.py,写一个类:
class DBRouter(object):def db_for_read(self, model, **hints):# 多个从库 ['db1','db2','db3']return 'db1'def db_for_write(self, model, **hints):return 'default'# 第三步:配置文件配置
DATABASE_ROUTERS = ['mysql_master_demo.db_router.DBRouter', ]# 以后自动读写分离# DBRouter1 自动读写分离2 一主多从,读可以做负载3 可以做分库3 django中多redis缓存
# 配置文件
CACHES = {"default": {"BACKEND": "django_redis.cache.RedisCache","LOCATION": "redis://127.0.0.1:6379/0","OPTIONS": {"CLIENT_CLASS": "django_redis.client.DefaultClient","CONNECTION_POOL_KWARGS": {"max_connections": 100}}},"slave": {"BACKEND": "django_redis.cache.RedisCache","LOCATION": "redis://127.0.0.1:6379/1","OPTIONS": {"CLIENT_CLASS": "django_redis.client.DefaultClient","CONNECTION_POOL_KWARGS": {"max_connections": 100}}}
}from django.core.cache import caches
caches['slave'].set('age',19)
print(caches['default'].get('name'))
4 django中使用连接池
# 下载:django-db-connection-pool# 1 配置文件中配置
DATABASES = {'default': {'ENGINE': 'dj_db_conn_pool.backends.mysql','NAME': 'cnblogs','HOST': '10.0.0.101','PORT': 33307,'PASSWORD': '123456','USER': 'root','POOL_OPTIONS': {'POOL_SIZE': 2,'MAX_OVERFLOW': 2}}
}# 查看mysql有多少连接数
show status like 'Threads%';
5 pycharm远程linux开发

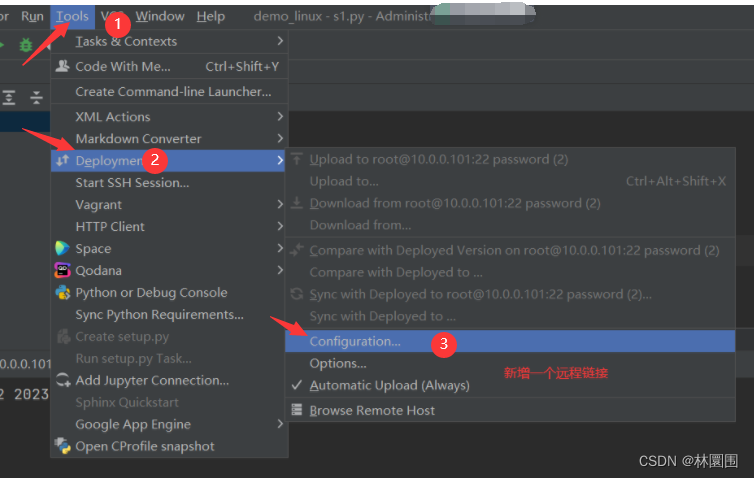
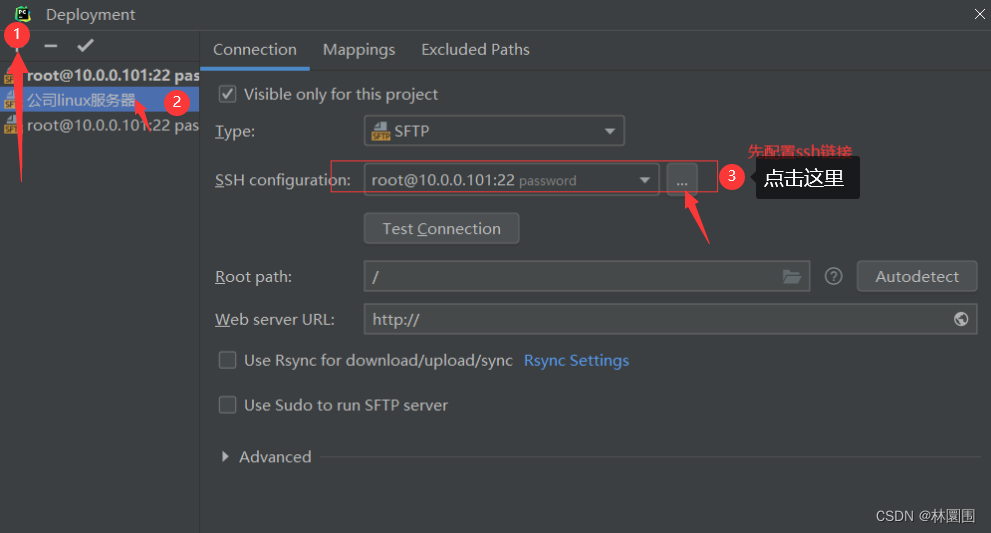
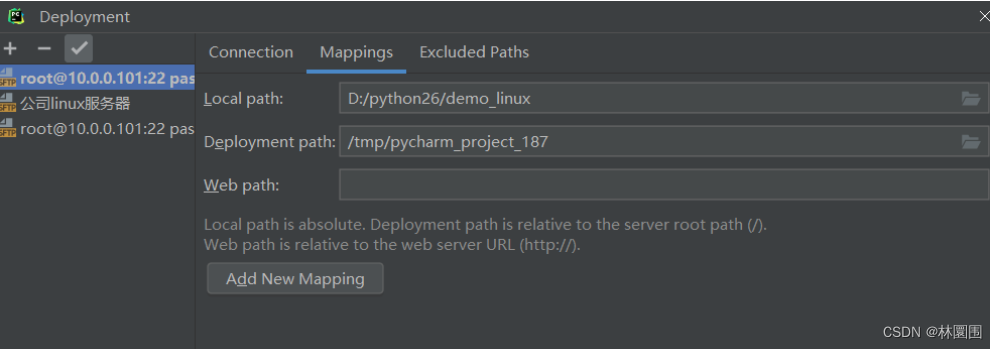
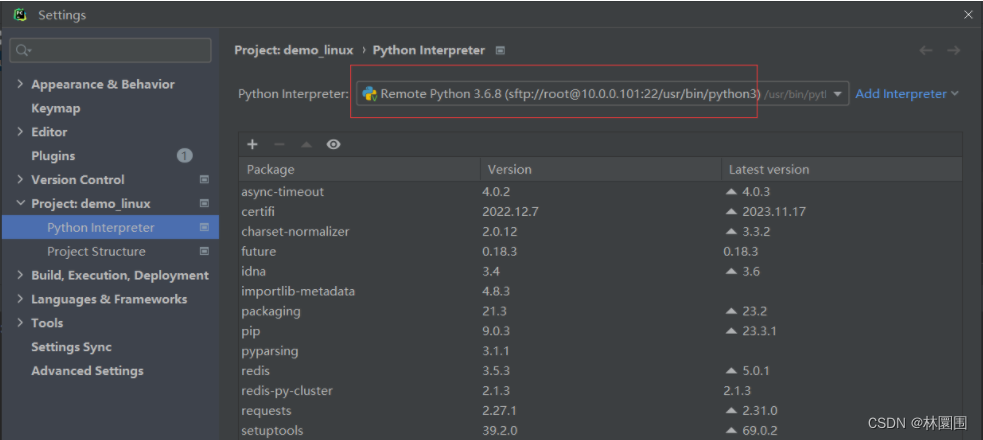
这篇关于mysql 主从搭建、django实现读写分离、django中多redis缓存、django中使用连接池、pycharm远程linux开发的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






