本文主要是介绍存储成本降71%,怪兽充电历史库迁移OceanBase,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

怪兽充电作为共享充电宝第一股,业务增长迅速,以至于业务架构不停地增加组件。在验证 OceanBase 可以简化架构并带来更大的业务价值后,首次尝试在历史库中使用 OceanBase 替代 MySQL,存储成本降低 71%。本文为怪兽充电运维架构部王霖对本次数据升级的经验总结、思考。

2017 年,“共享经济”成为年度热词,彼时共享单车 ofo 正红极一时,共享充电宝也正在市场扩散。就在这一年,怪兽充电成立,并后来者居上于 2021 年在纳斯达克上市。早在三年前怪兽充电的累计注册用户超 2 亿,到今年第二季度,注册用户数已经到了 3.625 亿,日均单量达 190 万笔。
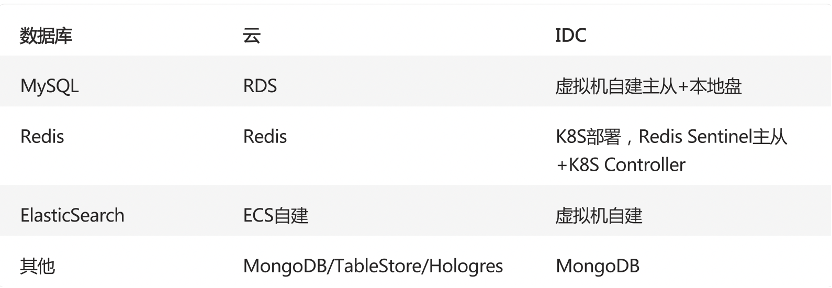
持续涌入的用户带来了业务的快速增长,业务系统架构逐渐变得复杂。目前采用的是混合云架构,由于系统中微服务和数据组件较多,因此我们开发了维护云+IDC、覆盖基础设施/中间件/微服务的 DevOps 平台 Hydra 进行统一维护管理。下表是目前我们用到的数据库。

在我看来,使用新技术通常有两种路径,一种是当前技术无法满足需求进而寻求解决方案,另一种是新技术能够提供更高的效率,带来更大的价值。
而我们属于后者,之所以会替换现有数据库方案,源于 OceanBase 的技术分享。当我们听完产品特性和技术方案的介绍后,认为 OceanBase 是对怪兽充电现有架构和业务比较有利的工具,但也存在一些疑虑。
其一,面向 C 端用户的业务尤其是关键业务,在数据库选型时需要更加严苛的考虑,避免切换数据库带来的任何潜在风险;
其二,对于 IDC 中的用户而言使用开源产品是更合适的,但以过往使用开源产品的经验来说,来自社区的支持力度较小;
其三,我们对 OceanBase 的底层语言 C++ 不是很熟悉,担心上手门槛较高。
在深入了解 OceanBase 产品及社区后,上述疑虑都打消了。OceanBase 有很活跃的用户答疑群、社区论坛,能够及时解答用户提出的问题。此外,社区会举办丰富的线上、线下交流活动,对于开源用户的支持力度让我们对 OceanBase 建立了信心,所以我们决定试试。
在 IDC 中部署 OceanBase 后,我们对比了 OceanBase 与 MySQL 的使用效果,对怪兽充电的业务情况而言,OceanBase 的优势主要有以下两方面。
第一,可扩展性强。OceanBase 既可以垂直扩容,也可以水平扩容,扩缩容快速、透明、方便,而 MySQL 水平扩容的方式是分库分表,维护成本相对更高。
第二,节省存储资源损耗。此前部署 MySQL 时,我们制定了统一的物理机标准,采购相同标准的 CPU 和内存,在此基础上做虚拟化及资源的分配。为此我们还自研了一个调度系统,目的是跟不同的 CPU 内存和磁盘的比例做调配,尽量减少资源损耗。由于 IDC 的容量并不大,导致存储碎片化严重:比如创建的某个数据库存储用量比较大源,而 CPU 内存占用却很少,这时候虽然物理机上 CPU、内存使用率低但因为磁盘空间已被占用而无法分配新的数据库实例,造成极大的资源浪费。我们对单数据库 OceanBase 和 MySQL 的数据占用:
如果部署单实例,数据占用对比是 1:6.8;如果部署 OceanBase 三副本,MySQL 做主从的话,数据占用对比为 1:4.6。可见,OceanBase 在存储方面的优势显著,可以显著降低我们 IDC 的存储用量。
此外,在我们测试性能时,发现了 OceanBase 的另一个特点。在低并发情况下,OceanBase 4.0 版本的性能比 MySQL 5.7 低 ,而在高并发环境下,OceanBase 4.0 表现的性能优于 MySQL 5.7。
综合上述测试情况和优劣势分析,我们部署了OceanBase 4.0,接下来介绍当前应用情况。

怪兽充电的订单业务主要是充电宝,其特点是客单价较低、单量大,下图是订单业务使用的数据库情况。
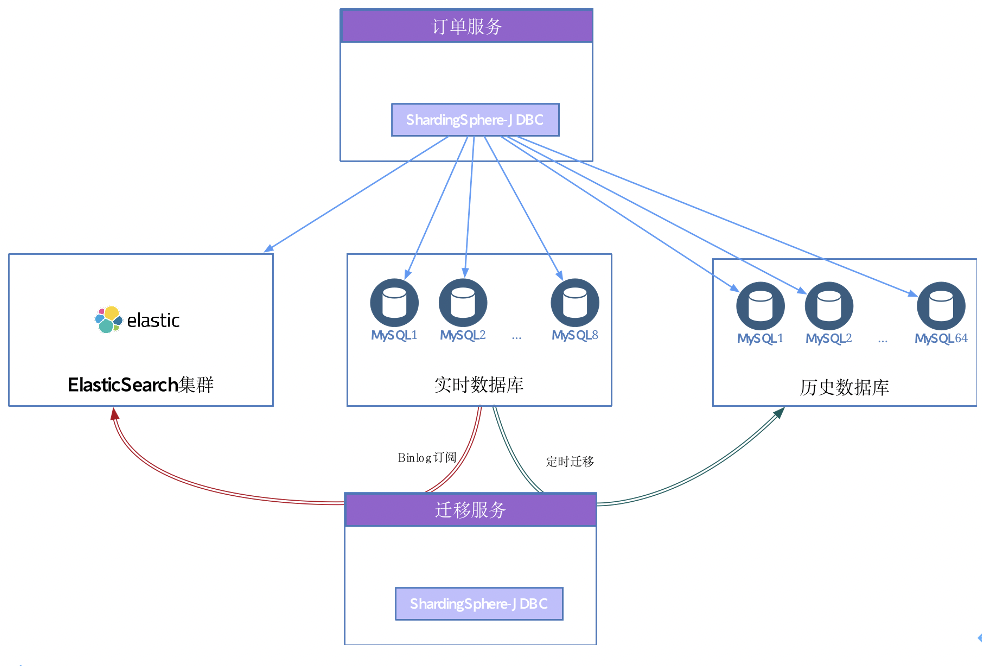
从图中可以看到,订单业务涉及的数据库包含三部分。
-
实时数据库支持用户下单,涉及高并发场景。为了提升高并发能力,我们按照用户分了 8 个库,并使用 ShardingSphere JDBC 接入迁移服务。
-
ElasticSearch 集群是为满足后台多字段的联合查询需求。在业务数据量不断扩大的情况下,后台查询若是用实时库查询,其索引无法覆盖所有的查询场景,由此引入 ElasticSearch 集群。迁移服务也写入 ElasticSearch 集群,通过 Binlog 订阅实时数据库的数据。
-
历史数据库在使用 MySQL 时采用分库分表方案,它的特点就是更新的需求很少。每天会有一个实时的任务,去把实时数据库中的历史数据定时写入历史数据库。历史库的数据量较大,从 8 个库分到 64 个库(schema),放到 8 个实例中,总体数据量约 9.6TB,单库中最大的表数据超过 2 亿行。
基于订单业务的数据库情况,我们决定第一步将历史数据库迁移至 OceanBase,降低存储成本与运维成本。原因是:其一,历史库的数据量级庞大,OceanBase 的优势之一就是降存储成本;其二,从 MySQL 的 64 个库到 OceanBase 单库,运维与维护成本会极大降低;其三,历史库读写场景较少,涉及少量精确的查询,且不影响用户下单,迁移的风险较小。

第一步,我们在 IDC 部署 OceanBase 集群。OBCluster 分了三个 zone 和三个server,分别部署在三组机架中;单主机规格为 40 核 128G,考虑到日常读写量和存储成本,我们仅仅在日志盘上使用了 SSD,数据盘使用的是机械硬盘。由于 OBProxy 是无状态服务,因此通过 Helm 被部署在 K8S 集群里。
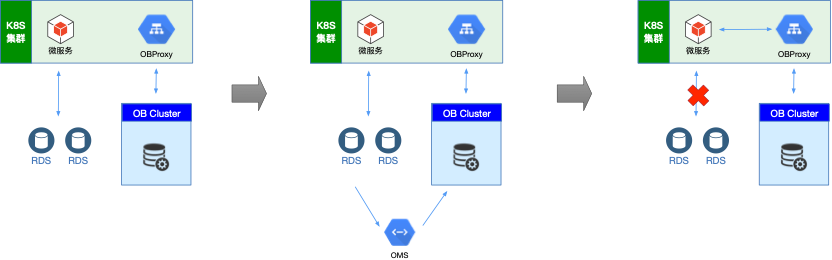
第二步,使用 OMS 同步数据。首先我们使用 OMS 同步 64 个数据库到 OceanBase,这里面存在一个多库汇聚到一个库的问题,那么,我们需要建 64 个数据同步对象吗?其实不用,OMS 的配置迁移对象的匹配规则能力,使分库分表的数据源迁移到 OceanBase 变得非常简单高效,对于我们 8 个数据库实例共 64 个库,建 8 个同步对象就行了,通过简单的配置可以实现每个实例上多个库的数据汇聚同一个 OceanBase 库。
为了确认 OceanBase 的稳定性,我们服务会保持一段时间的双写,等验证完会完全切换到 OceanBase 上。
接入 OceanBase 后,我们的存储成本节约了 71%,总的存储量从原来的 9.62TB*2(9.62 为单 MySQL 实例,考虑主从高可用部署所以乘以 2)到现在的 5.6 TB(三副本的总存储量),短期之内我们不用再考虑数据库扩容的问题了。
另外,我们在迁移过程中也遇到一些问题,可供大家参考。
第一,OBServer 与 Dell Raid 高速缓存兼容性问题:Dell Raid 卡高速缓存配置中,写策略为默认“回写”,改为“直写“后恢复;
a. 有租户 clog 满,扩容之后也会一直上涨;
b. 租户无法正常合并;
c. OBServer 启动日志中有大量关键字为"ret=\-4070"的 WARN 报错,有个关键信息"failed to fetch and submit single log",就是合并时无法读取日志,已经可以定位到 OBServer 合并场景中,有 I/O 操作不成功;
d. 后续定位到 Dell 阵列卡高速缓存配置中,写策略为默认的“回写”时,会引发单测复现问题,改为“直写“后恢复,相关问题也已经反馈 Dell。
第二,机械盘部署问题:在 OceanBase 实例上做压测时,因为磁盘性能不佳,导致日志流同步出现落后,进一步触发副本 rebuild。OceanBase 社区表示后续会优化一下对机械盘的兼容性。

目前订单业务的历史数据库迁移已完成,正式用于生产环境。经测试验证,在查询场景下 OceanBase 同样有着优秀的性能表现。接下来我们考虑将查询场景也迁移至 OceanBase,包括服务后台查询和报表查询。
-
服务后台查询:服务后台查询和上文提到的订单后台查询类似,用 MySQL 做相关的 OLTP 的操作,数据通过 Binglog 订阅同步写入Elasticsearch,整体成本较高,包括 MySQL 和 Elasticsearch 存储的重叠、中间链路数据同步服务的支撑等。因此,后续计划通过 OceanBase 替代 MySQL + Elasticsearch 的架构。
-
报表查询:报表查询当前的现状是,数据存储在 MySQL,遇到一些数据聚合量比较大的 SQL 查询时非常慢,影响系统稳定性。因为涉及一些 OLAP 的场景,考虑到 OceanBase 会比 MySQL 更合适,接下来会部署 OceanBase 对应的规格,并做流量回放比对验证。
在使用 OceanBase 的过程中,也让我们对其产生了一些功能上的期望,主要包括以下四点。
第一,期望 OMS 支持 MySQL 到 Rocket MQ 的数据迁移。在 IDC 侧,数据迁移的场景包括两部分。一部分是 MySQL 到 MySQL 的数据同步使用某其他国产数据库开源的 DM 工具,包括全量同步和增量同步;另一部分是从 MySQL 到 Rocket MQ 的数据同步使用 canal。我们调研了OceanBase 的 OMS,虽然使用体验不错,但发现社区版不支持数据从 MySQL 同步到 Rocket MQ。因此,我们希望能否将 OMS 开源,以共建的方式补全功能。这样一来,我们就可以将整体的迁移框架统一到 OMS 中。
第二,监控告警,以方便接入开源的监控告警体系。我们希望相关的组件能够提供 metrics 指标,以便接入我们内部的监控告警,同时提供一些 Grafana 面板,提供建议的告警表达式。
第三,问题排查更加智能化。当前,我们依赖 OCP 中比较完善监控指标和专家知识,而我们希望这部分变成自动化工具,包括自动分析、自动提供解决方案或工具等。
第四,开源或开放流量回放工具。
这篇关于存储成本降71%,怪兽充电历史库迁移OceanBase的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






