本文主要是介绍geolife笔记:整理处理单条轨迹,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
以 数据集笔记 geolife (操作篇)_geolife数据集-CSDN博客 轨迹为例
1 读取数据
import pandas as pd
data = pd.read_csv('Geolife Trajectories 1.3/Data//000/Trajectory/20081023025304.plt',header=None, skiprows=6,names=['Latitude', 'Longitude', 'Not_Important1', 'Altitude', 'Not_Important2', 'Date', 'Time'])
data=data[['Latitude', 'Longitude', 'Altitude', 'Date', 'Time']]
data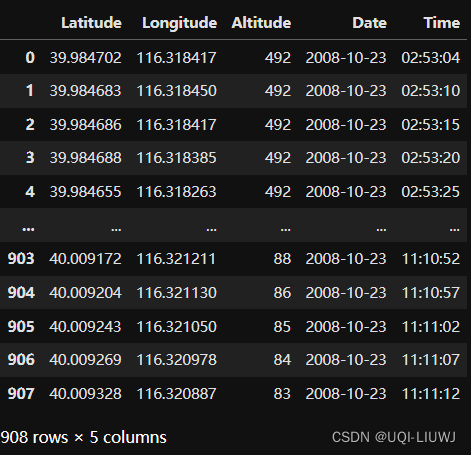
2 Date和Time 合并
data['Datetime'] = pd.to_datetime(data['Date'] + ' ' + data['Time'])
# to_datetime将这一列转换成时间
data=data[['Latitude', 'Longitude', 'Altitude', 'Datetime']]
data
3 只保留在北京城区的数据点
3.1 定义经纬度最值
import folium
BEIJING = [39.9, 116.41]
# central beijing coords, for map centres
B1 = 39.8,116.2
# bbox limits for beijing extent
B2 = 40.0 ,116.5
m=folium.Map(location=BEIJING,start_zoom=14)
folium.Marker(B1).add_to(m)
folium.Marker(B2).add_to(m)
m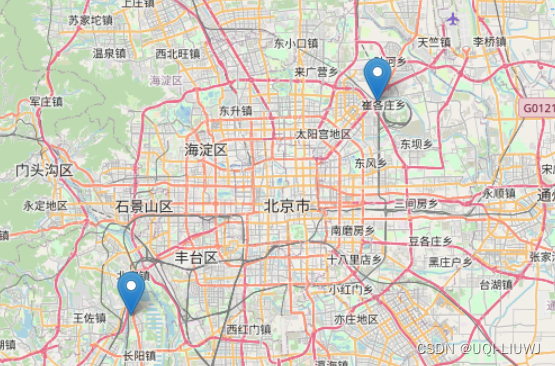
3.2 进行地理位置筛选
data=data[(data['Latitude']>B1[0]) & (data['Latitude']<B2[0]) & (data['Longitude']>B1[1]) & (data['Longitude']<B2[1])]
data
3.3 将time gap修改至5秒,保留每个5秒记录的第一条
data['Datetime_5s']=data['Datetime'].dt.floor('5s')
data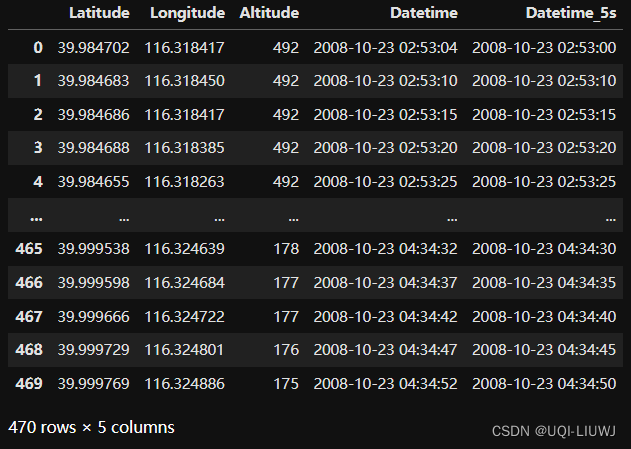
data=data.drop_duplicates(subset=['Datetime_5s'],keep='first')
data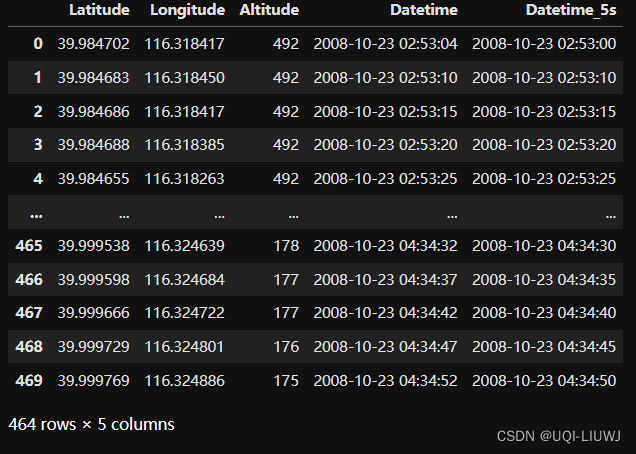
4 去除停止点
data['is_moving'] = (data['Latitude'] != data['Latitude'].shift()) | (data['Longitude'] != data['Longitude'].shift())
#判断用户有没有移动:当前位置和上一位置是否相同data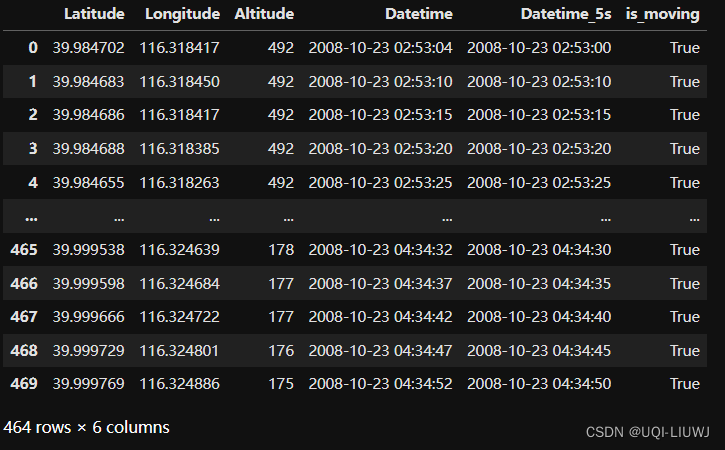
data=data[data['is_moving']==True]
data=data[['Latitude','Longitude','Datetime_5s']]
data 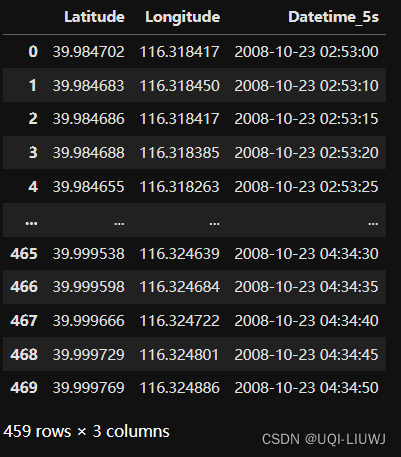
5 将10分钟内没有记录的轨迹切分成两条轨迹
5.1 计算 time gap
data['time_diff']=data['Datetime_5s'].diff()
data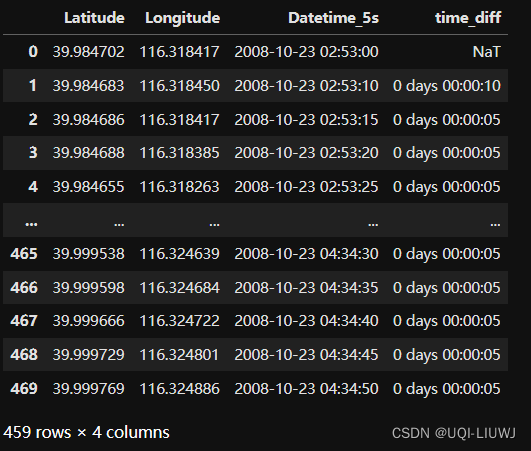
5.2 切分轨迹
data['split_id']=0
#split_id 将表示这是当前id 切分的第几段
data
mask=data['time_diff']>pd.Timedelta(minutes=10)
# 时间间隔大于10分钟的位置,记录一下
data.loc[mask,'split_id']=1
#这些位置的split_id记为1
data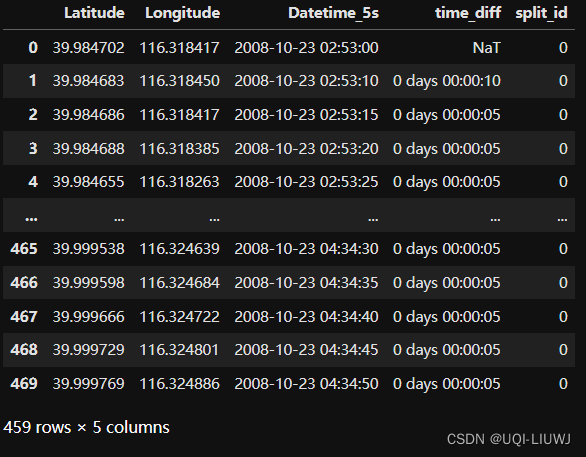
data['split_id']=data['split_id'].cumsum()
#出现过1的位置,到下一次出现1之前,split_id是一样的——比前一段多1
data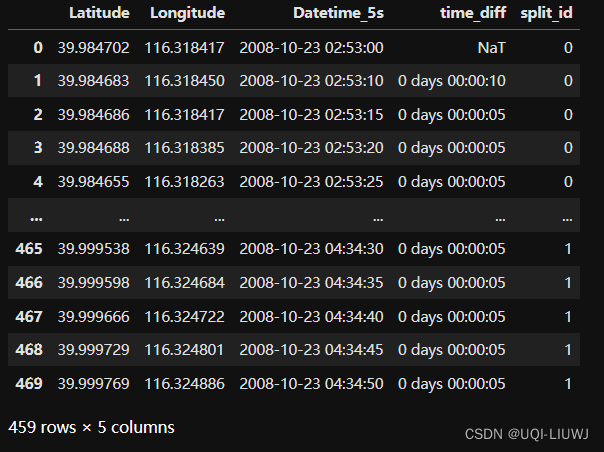
5.3 得到id
num=0
data['id']=str(num)
data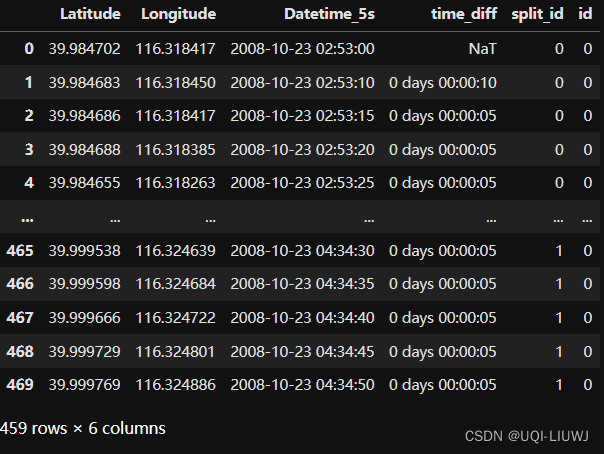
data['id']=data['id']+'_'+data['split_id'].astype(str)
data
6 计算每一条轨迹的长度,筛选短的,截断长的
6.1 计算相邻位置的经纬度差距
lat_lon_diff = data.groupby('id',group_keys=False).apply(lambda group: group[['Latitude', 'Longitude']].diff())lat_lon_diff
6.2 计算haversine距离的函数
def haversine_distance(lat1, lon1, lat2, lon2):R = 6371 # Earth radius in kilometersdlat = np.radians(lat2 - lat1)dlon = np.radians(lon2 - lon1)a = np.sin(dlat/2) * np.sin(dlat/2) + np.cos(np.radians(lat1)) * np.cos(np.radians(lat2)) * np.sin(dlon/2) * np.sin(dlon/2)c = 2 * np.arctan2(np.sqrt(a), np.sqrt(1-a))return R * c6.3 计算同一轨迹相邻位置的距离
import numpy as npdistance = lat_lon_diff.apply(lambda row: haversine_distance(row['Latitude'], row['Longitude'], 0, 0), axis=1)
data['distance']=distance
data
6.4 计算同一id的累积距离
data['accum_dis']=data.groupby('id')['distance'].cumsum()data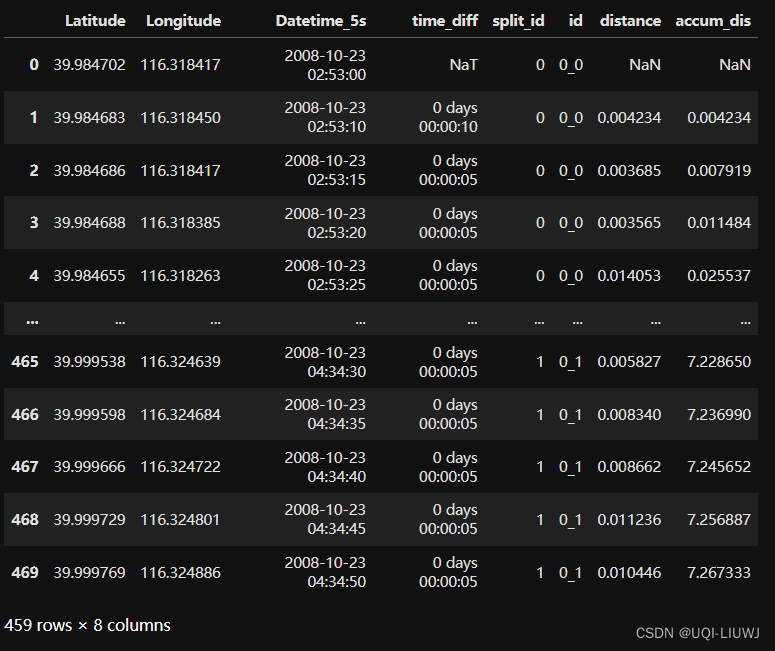
6.5 得到每一个id的轨迹距离
iid=data.groupby('id')['accum_dis'].max()iid=iid.reset_index(name='dis')
iid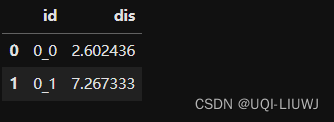
6.6 筛选长度大于1km的
iid=iid[iid['dis']>=1]
data=data[data['id'].isin(iid['id'])]
data
6.7 将长度长于10km的轨迹拆分成两条,并去掉拆分后长度小于1km的
data['split_traj_id']=data['accum_dis']//10
data['split_traj_id']=data['split_traj_id'].fillna(0)
data['split_traj_id']=data['split_traj_id'].astype(int).astype(str)
data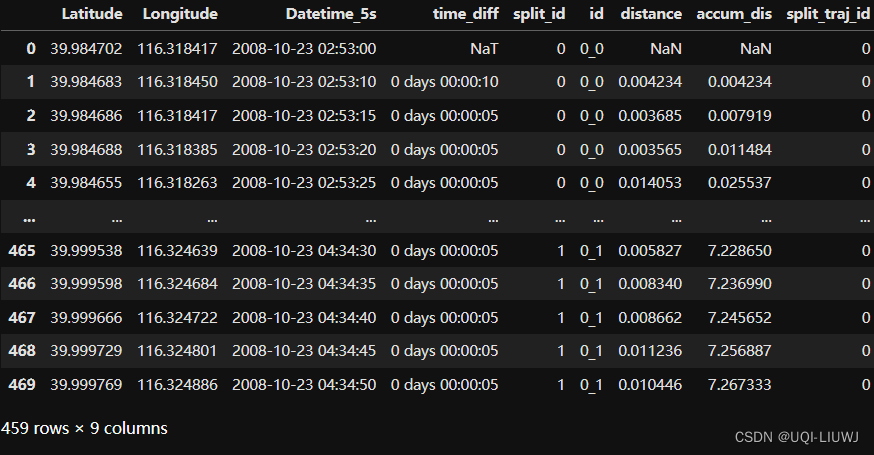
data['id']=data['id']+'_'+data['split_traj_id']
data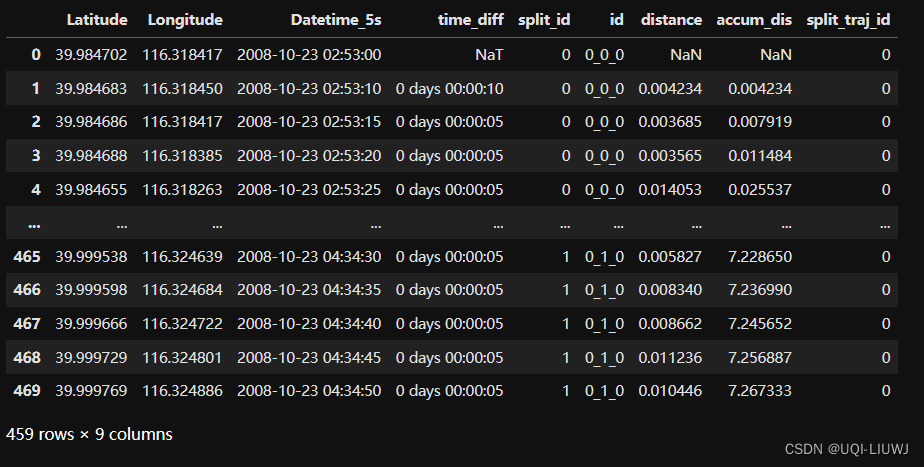
去除切分后长度小于1km的:
iid=data.groupby('id')['accum_dis'].max()
iid=iid.reset_index(name='distance')
iid 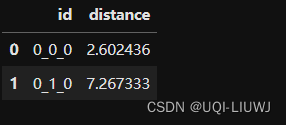
iid=iid[iid['distance']>1]
data=data[data['id'].isin(iid['id'])]
data
7 剔除记录数量小于10条的轨迹
iid=data.groupby('id').size()
iid=iid.reset_index(name='count')
iid=iid[iid['count']>=10]
iid
data=data[data['id'].isin(iid['id'])]
8 去除“staypoint”
这里的staypoint 意为 最值经纬度对应的距离小于1km
latlon=pd.DataFrame()
latlon['max_lat']=data.groupby('id')['Latitude'].max()
latlon['min_lat']=data.groupby('id')['Latitude'].min()
latlon['max_lon']=data.groupby('id')['Longitude'].max()
latlon['min_lon']=data.groupby('id')['Longitude'].min()
latlon['max_dis']=latlon.apply(lambda row: haversine_distance(row['max_lat'],row['max_lon'],row['min_lat'],row['min_lon']),axis=1)latlon=latlon[latlon['max_dis']>=1]
latlon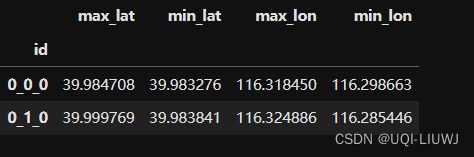
data=data[data['id'].isin(latlon.index)]
data
这篇关于geolife笔记:整理处理单条轨迹的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





