本文主要是介绍大数据毕业设计之前端02:架构布局和aside的设计,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
上一篇主要讲了我学习前端的一个经历,以及为什么选择BuildAdmin作为深入前端学习的原因.同事也大致聊了一下学习前端需要使用哪些技术栈。
本篇文章来拆解一下BuildAdmin的前端代码结构,和布局实现的细节。
前端代码结构
必须先了解项目的结构,才能明确每个功能模块的代码在哪写。BuildAdmin前端目录如下,我只对一级目录进行了粗略的标注,详细的可以去官网看。

在本地需要使用vue-cli脚手架来构建项目,在构建时会有很多选项,包括使用的vue版本和各种插件。
npm install -g @vue/cli
vue create buildadmin
创建之后,基本的目录结构就出来了,后续就可以在各个功能目录添加子目录和模块。
环境安装
在创建好项目之后,还需要安装一些额外的依赖,例如sass、bable等。

1. 安装sass
npm i sass sass-loader
2. 安装babel
babel的主要功能那是将ES语法转换成浏览器识别的js
npm install --save-dev @babel/core @babel/cli @babel/preset-env @babel/node @babel/polyfill
3. 安装babel,使用可选链?.
在BuildAdmin中,有很多时候都会出现 ?.,这便是防止出现空指针异常的可选链写法,原则就是:有就用,没有就不用。
假设一个对象obj,没有name属性。如果obj.name则会报空指针错误,如果使用obj?.name则输出的是obj。
npm install --save-dev @babel/plugin-proposal-optional-chaining4. 关闭lint
lint会检查编码中格式的错误,我个人不是很喜欢,所以我会在vue.config.js中关掉。
const { defineConfig } = require('@vue/cli-service')
module.exports = defineConfig({transpileDependencies: true,lintOnSave: false
})
任何一个vue项目都是从main.ts开始,按照层级开始编写各个组件。而App.vue中作为第一个节点,引入整体的布局组件。
架构布局
BuildAdmin作为一个管理平台,首先要完成布局部分。我们先看BuildAdmin的布局:
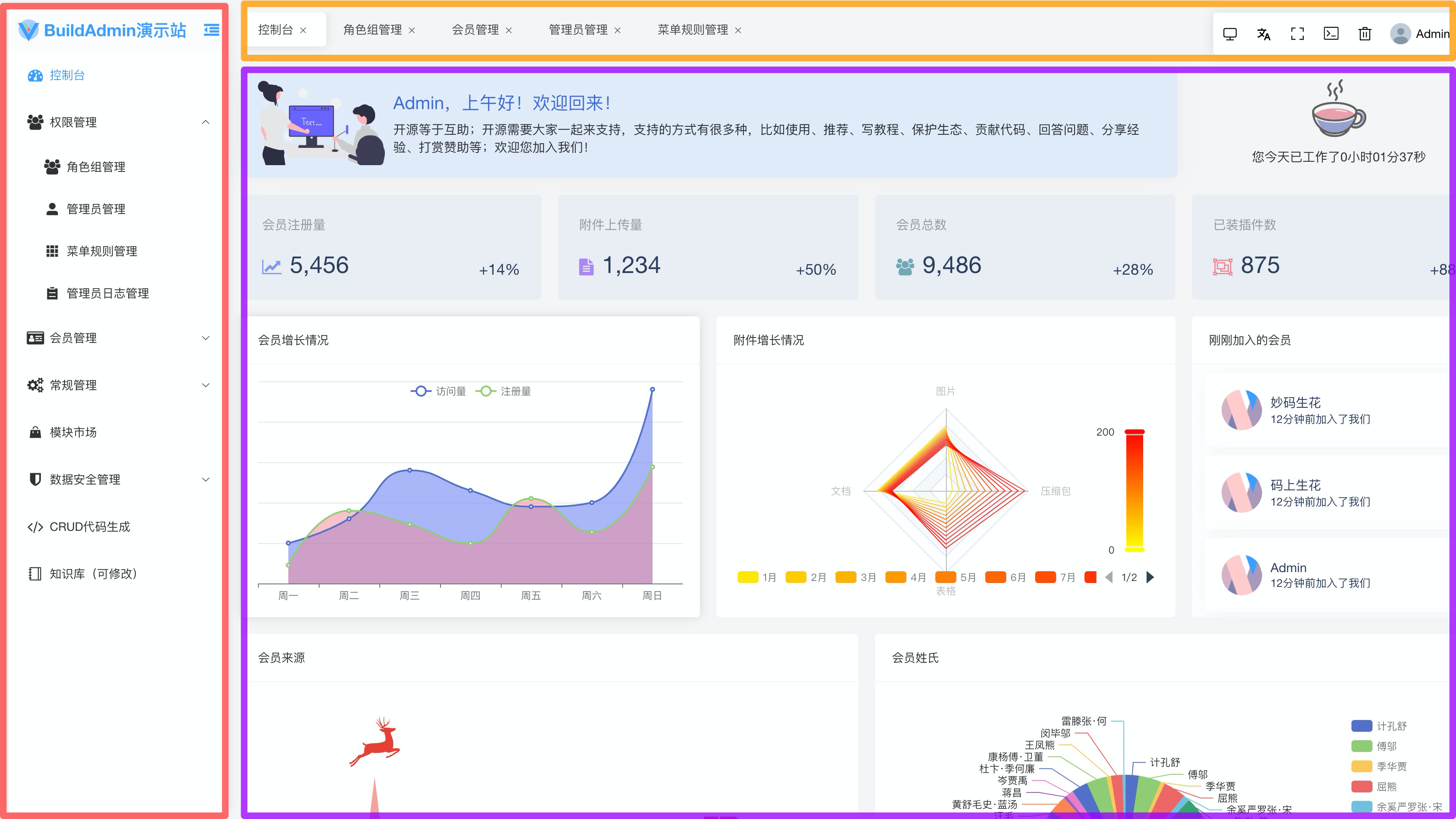
可以看到BuildAdmin的整体布局是由:菜单边栏aside、导航header和中心区域main组成的。即ElementPlus中的aside、header、main布局。

这就是官网的代码。
布局实现
从App.vue作为根节点,开始绑定组件。
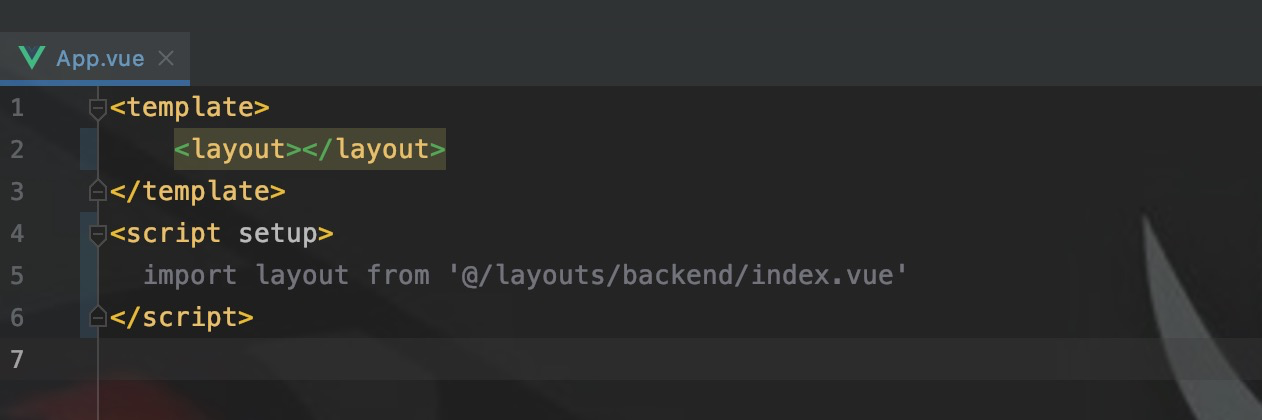
<layout>就是定义的整个布局。
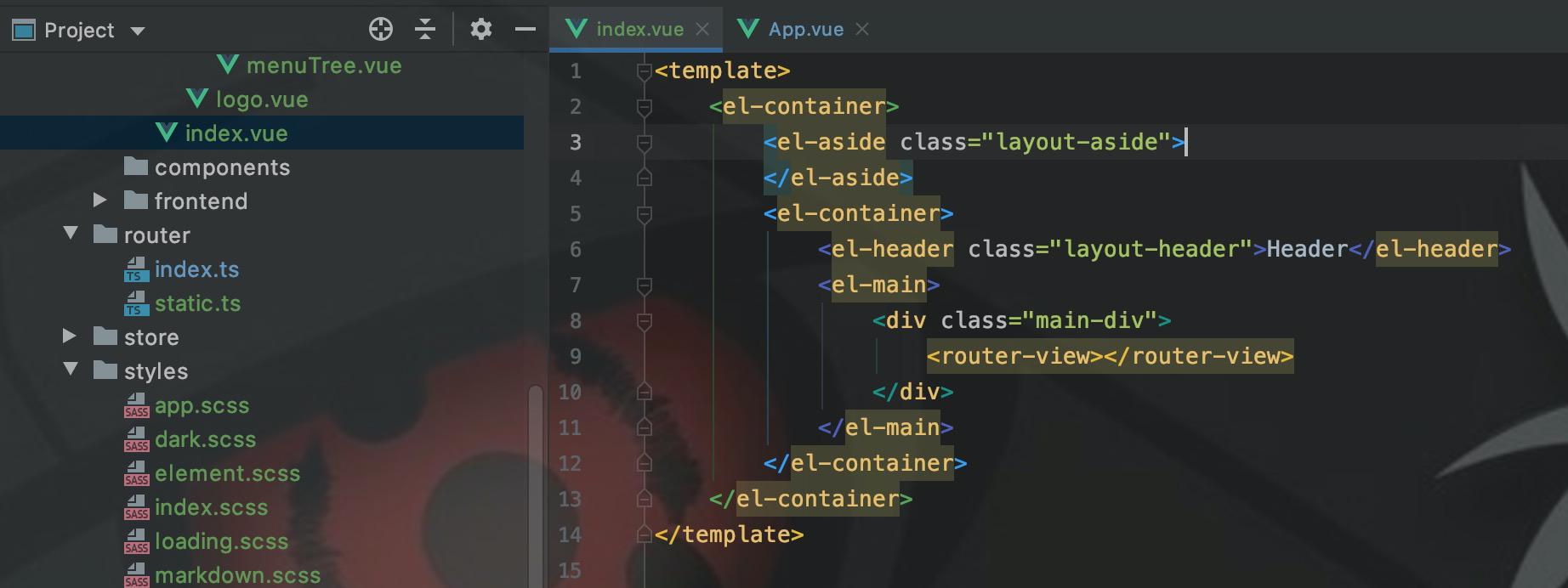
上面是我从Element的官网copy的布局代码。BuildAdmin在实现布局时,将aside、header、main都拆分成了单独的组件,如下图所示:

后面我也拆分了的布局代码,将aside、header和main拆分成了三个组件,这样便于阅读、定义css和实现js逻辑等。。

要注意的事,拆分成三个组件之后,在css中需要添加一个flex-direction属性,在拆分之间是没有的。答案在官网中给出来了:如果<el-container>里如果有el-header元素,则会默认为垂直排列。
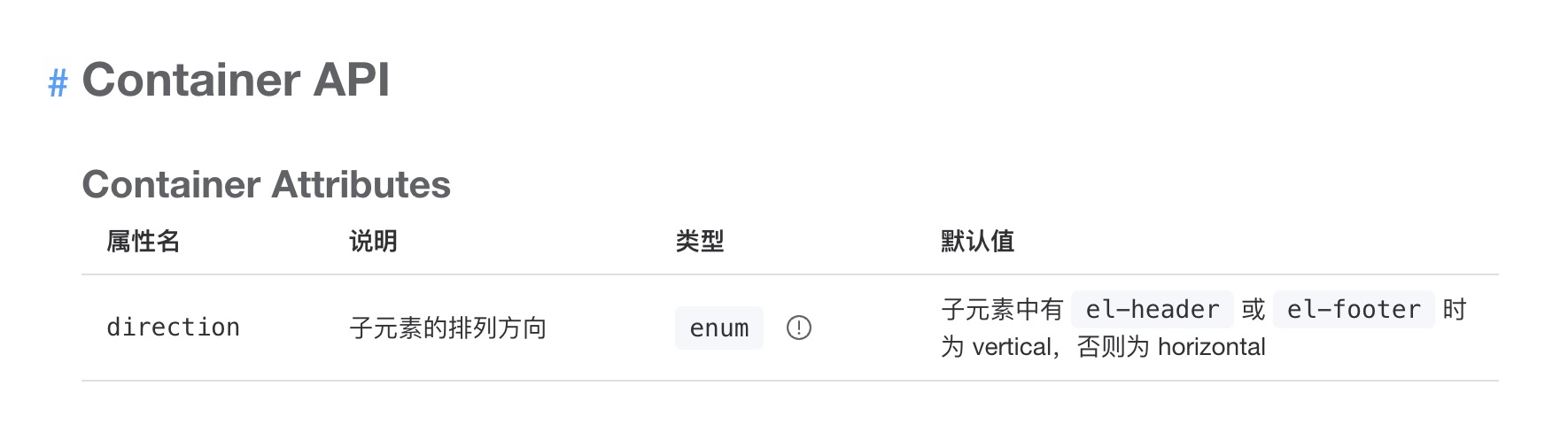
后面的拆分,el-header被封装成Header组件了。el-container里面就没有el-header元素了,所以就变成水平分布,这样header就在main的就布局在同一水平线上了,而非上下排列。为了保证上下排列,则必须将此属性设置为column。
实现思路
在将页面拆分成三个部分之后,就需要定义css渲染,来确定各个部分的区域大小和样式。header主要用来渲染面包屑标签,所以暂时先不定义这一块的样式。之后会根据导航标签大小和页面布局调整高和宽,即height和width。
main主要展示各个菜单路由切换后的页面,只要确定height和width即可,这个可以后面实现完路由再调整。所以根据开发需要,可以先实现aside的样式。
aside渲染
aside.vue中此时只有一个<el-aside>元素,此时我们需要定义它的css样式。
1. css
在style中定义css时,指定sass为css预处理器。

v-bind是vue3中的新用法。其中的menuWidth参数是pinia定义的状态变量,为260px。这里为什么要使用v-bind,而不是直接写260呢?因为aside的宽度是变化的,因为后面菜单折叠需要动态修改宽度,所以这里不能写死。
而且因为菜单栏要放在aside中,且宽度一致,所以直接使用一个变量方便同步控制。那至于为什么定义成260,接着往下看。
那么,css中这些var里面的–开头的变量是哪里来的啊? 这些其实就是el和自定义全局变量,在控制台都可以查看到。
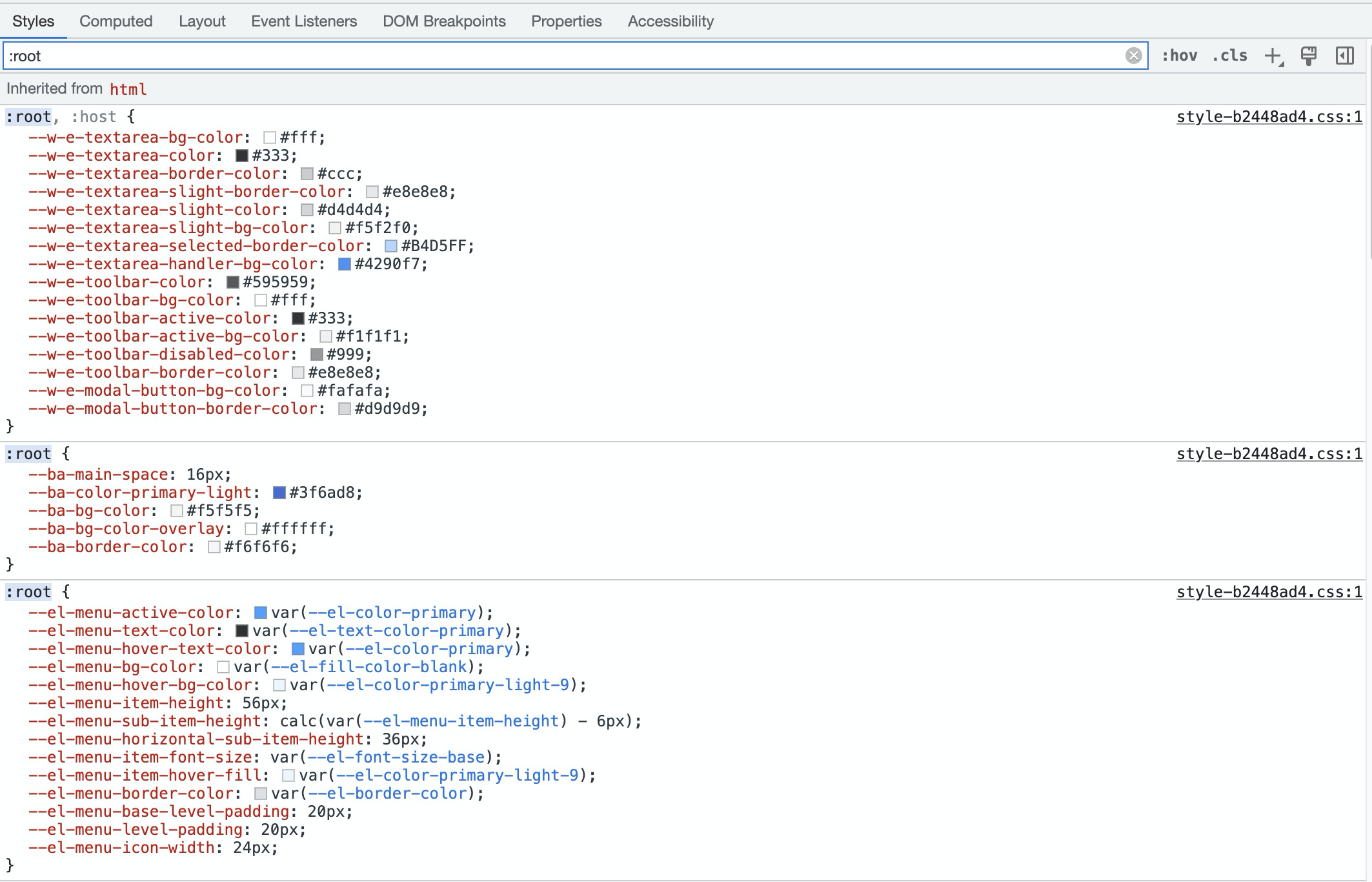
其中–ba开头的,是BuildAdmin在var.scss中自定义的全局变量。
2. 开发技巧
如果不知道组件的css在哪里定义的,就可以在控制台查看。
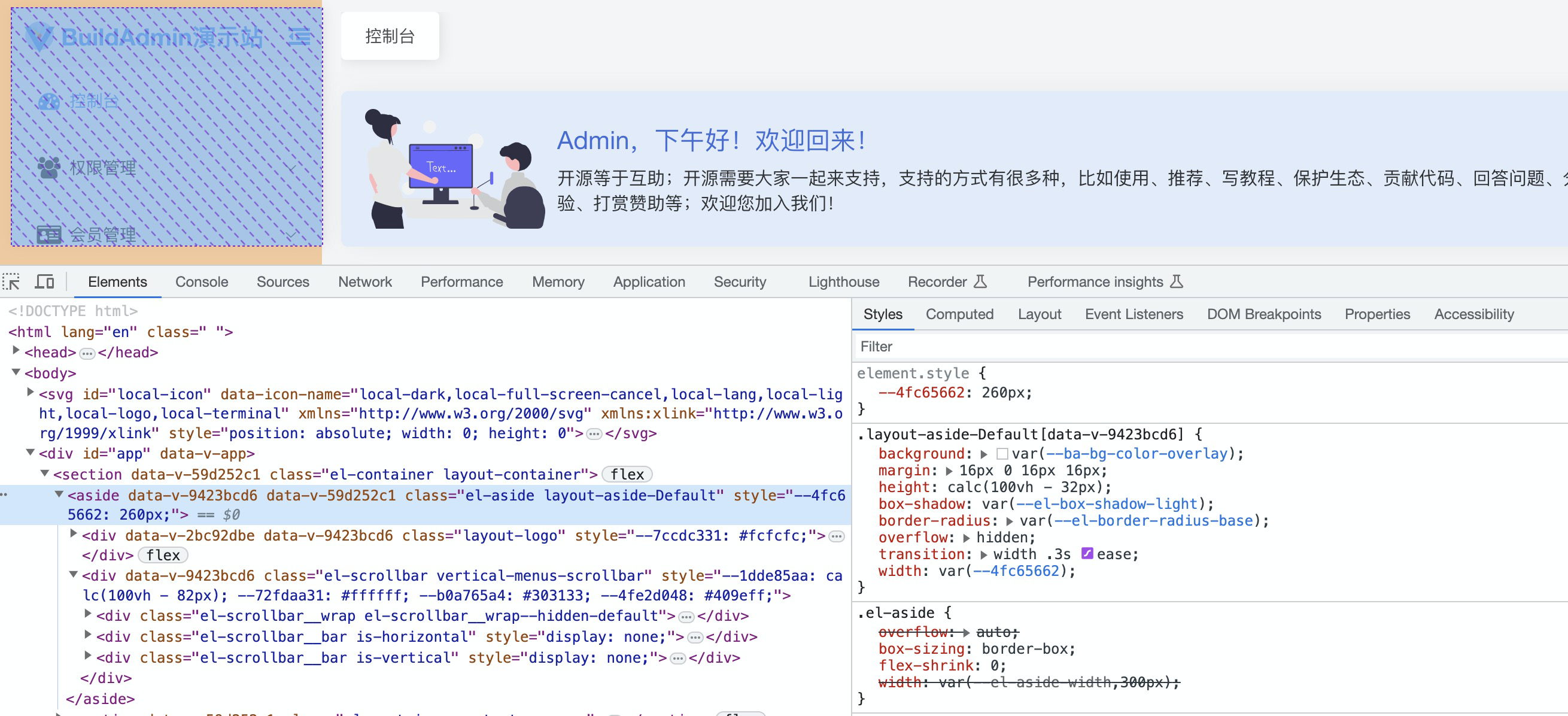
可以看到aside的样式:margin上下都是16px,所以上下共有32px。32px + height = 100%,所以aside的height就是100vh-32px?同时,也可以看到width是260px。
3. 渲染效果
至此aside就渲染好了。

虽然现在看起来也没什么变化,但是添加完logo和菜单之后,就会大有不同。
结语
第二篇开篇主要讲了项目的创建和环境变量的安装。后面阐述了边栏aside的设计思路,以及对css的定义和解读。只涉及了基本的vue和ElementUI的使用。
同时,本篇文章提及的控制台查看属性的技巧,下一篇主要讲的菜单渲染,将会涉及vue-router等技术。

这篇关于大数据毕业设计之前端02:架构布局和aside的设计的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





