本文主要是介绍如何成为 Apache Spark 的 Contributor?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
改了 N 次,和 Apache Spark 开源社区的大佬沟通了2 个星期,我的 Pull Request 终于被接受了!!!

感兴趣的小伙伴可以访问下面的链接来感受一下开源社区的魅力,大佬们真的都很热情,对我的 PR 提了很多宝贵的意见!
[SPARK-35907][CORE] Instead of File#mkdirs, Files#createDirectories is expected. by Shockang · Pull Request #33101 · apache/spark
正文
下面对我这次提交 PR 并被接纳的过程做一个总结,如果也有对开源社区感兴趣并且想成为 Apache Spark Contributor 的小伙伴们读了下面的文章能帮助你少走很多弯路~
成为 Apache Spark Contributor 最基本的要求:
- 比较扎实的 Java 和 Scala 编程功底(不懂 Scala 特别是一些高级语法的用法,你基本看不懂 Apache Spark 的源码,Scala 的学习曲线比较陡峭,不会 Java 想学懂 Scala 也不太可能,Apache Spark 的源码中也有一部分是由 Java 编写的)
- 还 OK 的英语水平(我的英语也不是很好,但是我起码能看得出谷歌翻译出的英语好不好~( ̄▽ ̄~)(~ ̄▽ ̄)~ 这个也挺重要的,因为很多注释得你自己来写,你起码得确保注释没啥问题,不会被老外笑)
- 对于 Apache Spark 比较熟悉, Apache Spark 的一些基本概念你得了如指掌(比如下面提到的 Worker 你得知道是啥?有什么作用?)
- 一个 github 账号和一个 JIRA 账号加上不错的网络(吐槽一句,github 家庭访问太坑了,经常访问不到)
下面是 Apache Spark 的编程语言组成:

fork
fork 到你自己的 github 仓库后记得 clone 到本地进行开发
Github Actions
需要开启GitHub Actions工作流程进行测试。
这样在每一次 git push 后 Github 都会启动自动化测试你提交的代码,这个也必须要开启的,社区的规定。
Apache Spark利用GitHub Actions实现持续集成和广泛的自动化。
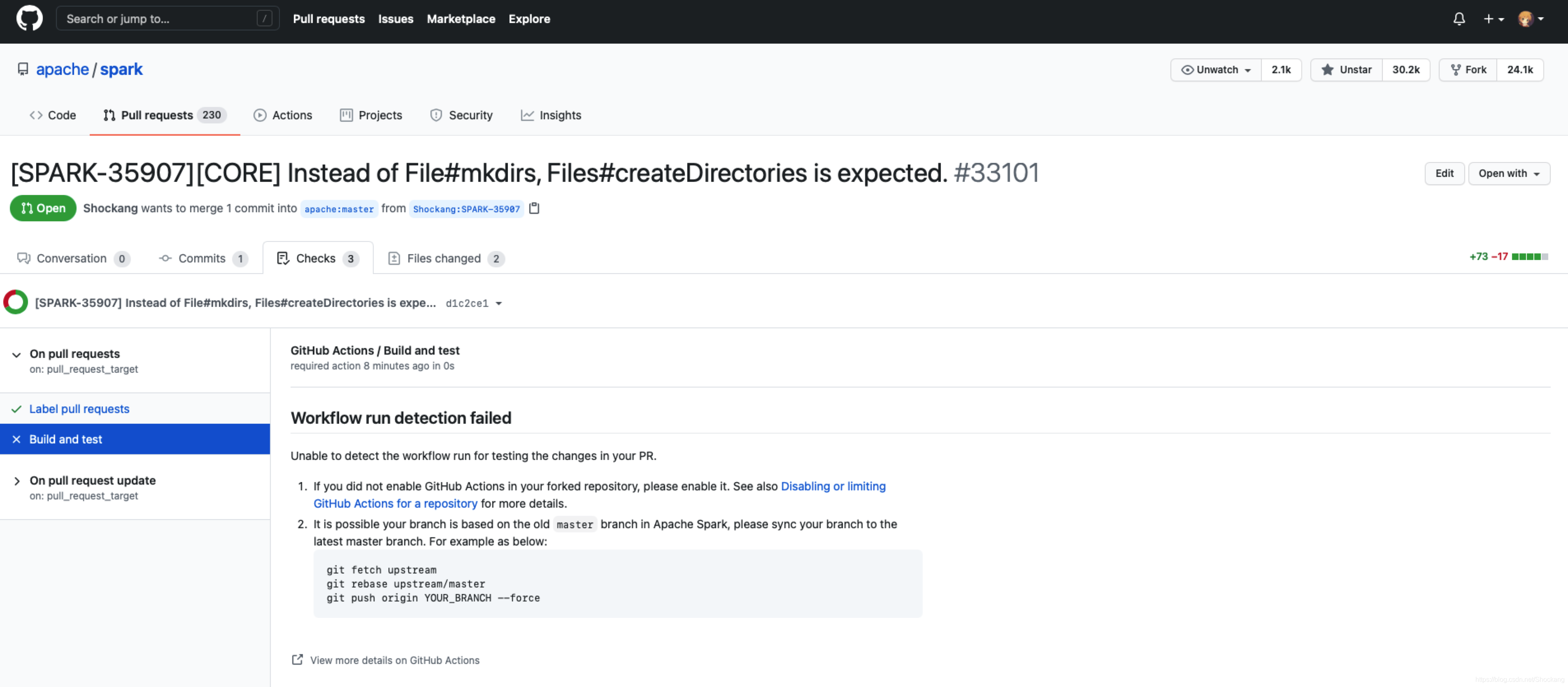
下面是一个反例:
我第一次提交 PR 时就没有开启 GitHub Actions ,结果报错了
Workflow run detection failed
Unable to detect the workflow run for testing the changes in your PR.
代码准备
首先,最重要的是要找到可以修改代码的地方。
先说下我是怎么找到在哪里修改 Apache Spark 的代码的
我之前一直在阅读 Apache Spark 的源码,在我读到 Worker 启动的代码时(这是属于 Spark Core 里面的代码)
/*** Create a directory given the abstract pathname* @return true, if the directory is successfully created; otherwise, return false.*/def createDirectory(dir: File): Boolean = {try {// This sporadically fails - not sure why ... !dir.exists() && !dir.mkdirs()// So attempting to create and then check if directory was created or not.dir.mkdirs()if ( !dir.exists() || !dir.isDirectory) {logError(s"Failed to create directory " + dir)}dir.isDirectory} catch {case e: Exception =>logError(s"Failed to create directory " + dir, e)false}}
代码节选自 org.apache.spark.util.Utils 类
Worker启动的时候会调用上面的工具类方法创建工作目录。
我注意到注释里面的这句话
This sporadically fails - not sure why ...
我觉得 Apache Spark 作为顶级的开源项目,源码里面不应该出现这样不严谨的话,
File.mkdirs() 这个方法作为 Java 程序员应该都比较熟悉,这是用来创建目录的,即使父目录不存在也没有关系。
这个方法可能会创建失败,在创建失败的时候会返回 false(虽然此时父目录可能已经创建了) ,造成失败的原因有:
- 权限问题(这是最常见的)
- IO 异常(这和操作系统相关)
- 文件已经存在了
按照我的本意,我第一次提交 PR 只想改一改注释(我是按照 注释 -> 优化代码 -> 修复 bug -> 需求开发 这样的路子走的,这也是大部分新人 Contributor 的发展路线 )
我正准备把上面的失败原因按照英文加入到源码里面进行提交,这时候我想起了 JDK7 中新增了一个工具类 java.nio.file.Files,里面有一个方法 Files.createDirectories()
以前我在写IO工具类的时候还特地研究了一哈 ⊙▽⊙
这个方法完全可以替代 File.mkdirs()。
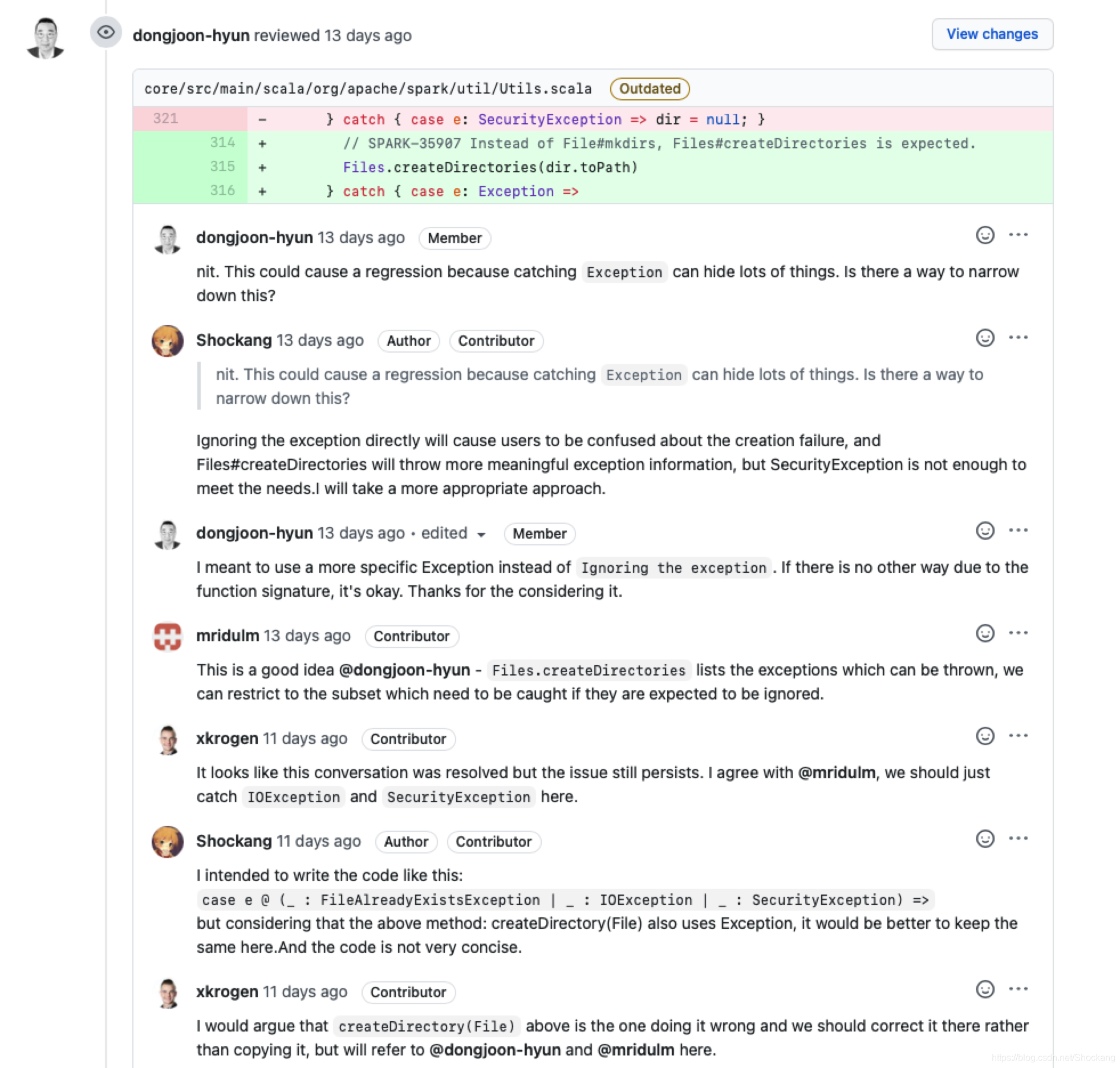
我接着仔细的研究了一下 Files.createDirectories() 的源码,我发现这个方法相比 File.mkdirs() ,在异常处理方面更加的有优势,File.mkdirs() 创建失败了只会返回 false,就算出异常了也只会抛出SecurityException。而 Files.createDirectories() 的异常处理机制更加的友好,权限问题抛出SecurityException,操作系统有问题抛出IOException,文件已经存在抛出FileAlreadyExistsException(这也是IOException的子类)
Files.createDirectories() 异常处理机制可以说完爆 File.mkdirs() ,碰巧的是, not sure why 对于 Files.createDirectories() 来说根本就不会存在,它在抛出的异常里面会明确的表示出到底是什么原因导致的创建失败。
我意识到这是个不错的修改点,我接着搜索了 Apache Spark 的源码,源码里面有不少的 File.mkdirs()
所以我就决定提交 PR 了,代码如下所示
/*** Create a directory given the abstract pathname* @return true, if the directory is successfully created; otherwise, return false.*/def createDirectory(dir: File): Boolean = {try {// SPARK-35907: The check was required by File.mkdirs() because it could sporadically// fail silently. After switching to Files.createDirectories(), ideally, there should// no longer be silent fails. But the check is kept for the safety concern. We can// remove the check when we're sure that Files.createDirectories() would never fail silently.Files.createDirectories(dir.toPath)if ( !dir.exists() || !dir.isDirectory) {logError(s"Failed to create directory " + dir)}dir.isDirectory} catch {case e: Exception =>logError(s"Failed to create directory " + dir, e)false}}
这是和社区大佬沟通后的最终版本,只节选了一部分和上面的代码对应起来方便大家理解
push
注意 push 之后要时刻关注 GitHub Actions 里面的测试用例是不是运行成功了(我就碰到几次明明没错结果测试用例跑失败了,要多重试)
JIRA
在 github 提交 PR 之前,一定要在 Apache Spark 的 JIRA 上面提交一个 issue
Apache Spark 的 JIRA 访问网址

提交格式可以参考我的issue:
SPARK-35907 Instead of File#mkdirs, Files#createDirectories is expected
提交 PR

注意这里要切换成你提交的代码分支,最好使用 JIRA 上面的 issue 号
PR 格式要求
下面的格式在提交 PR 后会自动显示在输入框里面,这里起到一个解释说明的作用
[SPARK-xxxxx 即上面关联的 JIRA 的 issue][涉及到的模块比如 CORE ] 标题### What changes were proposed in this pull request?这次 PR 中期望带来哪些改变?就是说明一下哪些地方的代码改动了。### Why are the changes needed?为什么需要这些改变?第一次提交 PR 的最好想一个比较好的理由可以说服 commiter 把你的代码合入 master。### Does this PR introduce _any_ user-facing change?这次 PR 是否有面向用户层面的改动?注意是任何面向用户层面的改动都得写 Yes,并且要写出哪些改动是面向用户的。### How was this patch tested?这个 patch 是怎样测试的?这个很重要,第一次提交 PR 要想成功一定要写非常完善的测试用例。下面是我提交的 PR,可以结合上面一起来理解
[SPARK-35907][CORE] Instead of File#mkdirs, Files#createDirectories is expected### What changes were proposed in this pull request?The code of method: createDirectory in class: org.apache.spark.util.Utils is modified.### Why are the changes needed?To solve the problem of ambiguous exception handling in traditional IO creating directories.What's more, there shouldn't be an improper comment in Spark's source code.### Does this PR introduce _any_ user-facing change?YesThe modified method would be called to create the working directory when Worker starts.The modified method would be called to create local directories for storing block data when the class: DiskBlockManager instantiates.The modified method would be called to create a temporary directory inside the given parent directory in several classes.### How was this patch tested?I have provided test cases as much as possible.
沟通
重要性 MAX
基本上和上面的写代码同等级重要,代码虽然写出来了,你得说服 Committer 把你的代码合入 master,不然你代码写再多都没用!
一定要和社区的各位大佬多沟通,可能会有多个 Contributor 对你的提交有一些建议,一定要回复他们。当然 Committer 的建议是优先级 MAX 的,因为只有他们才有把你的代码合入master 的权限。
这里就体现出英语好的重要性了,就不会和我一样还要借助谷歌翻译(百度翻译)来沟通,每一次翻译后都得改一改
┭┮﹏┭┮
成功合入 master
最优美的文字 o( ̄︶ ̄)o

总结
代码很重要,测试很重要,沟通很重要
这篇关于如何成为 Apache Spark 的 Contributor?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






