本文主要是介绍搜索推荐技术-爱奇艺搜索引擎技术,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、爱奇艺的搜索引擎框架示意图
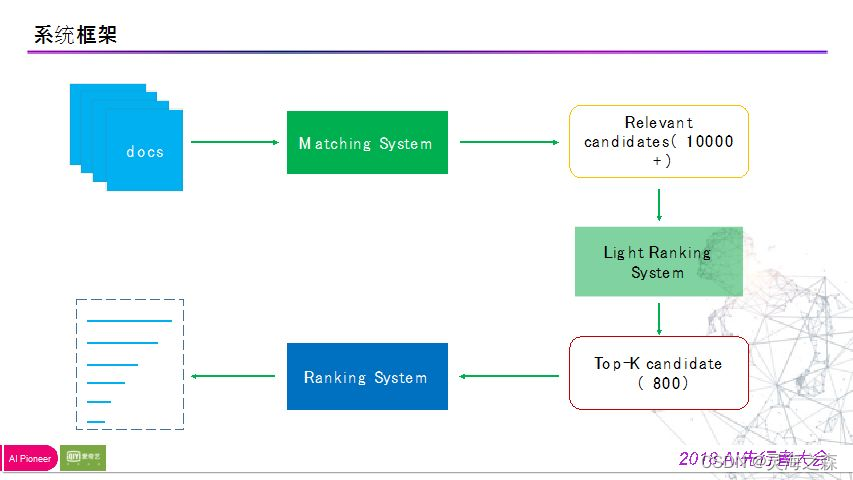 即通过召回系统,即基于文本匹配的matching system,得到大量视频资源的候选集,经过粗排和精排,最后返回给用户。重点在于召回模块和排序模块。
即通过召回系统,即基于文本匹配的matching system,得到大量视频资源的候选集,经过粗排和精排,最后返回给用户。重点在于召回模块和排序模块。
二、召回模块
召回模块比较重要的是基础相关性,类比于传统的切词倒排索引;还有基于深度学习模型的索引,类比于向量索引。
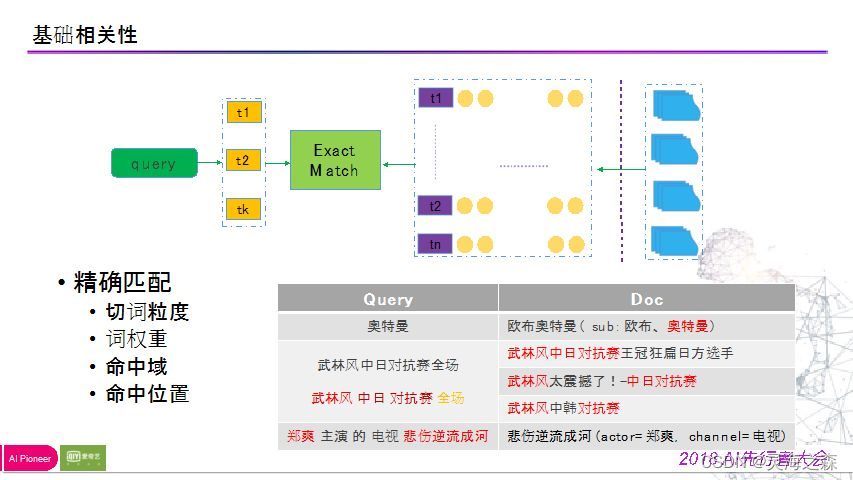
1.基础相关性
通过对用户的query进行切词,将右边的视频资源的文本描述信息构建构建倒排索引,此过程为精确匹配过程,词匹配则倒排索引拉回归并,然后返回用户。
需要注意的是切词粒度和词的权重问题。不同的词的粒度会影响你是否可以通过倒排索引召回内容;词权重会影响你在相关性计算的时候的最终得分。
基础相关性解决不了的问题,被归为四类:词汇的同义多义问题、语言表达差异、输入错误兼容、泛语义召回。
2.基于深度学习模型
在搜索场景下,用一些nlp工具,能够把词表示成低维的向量,该向量可以表示词与词之间的相关性,在网络里面加入rnn,cnn等机制,把网络做的足够复杂,以提取更加有效的匹配的特征。

组合起来,就形成了最终的召回模块
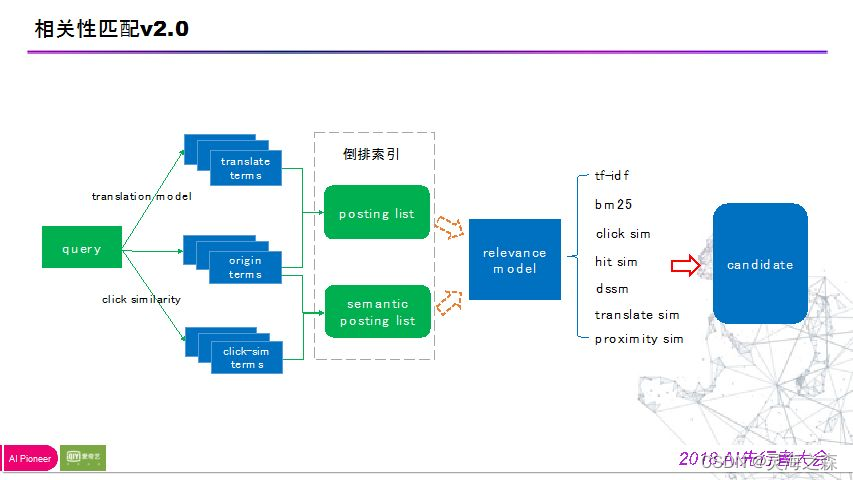
三、排序模块
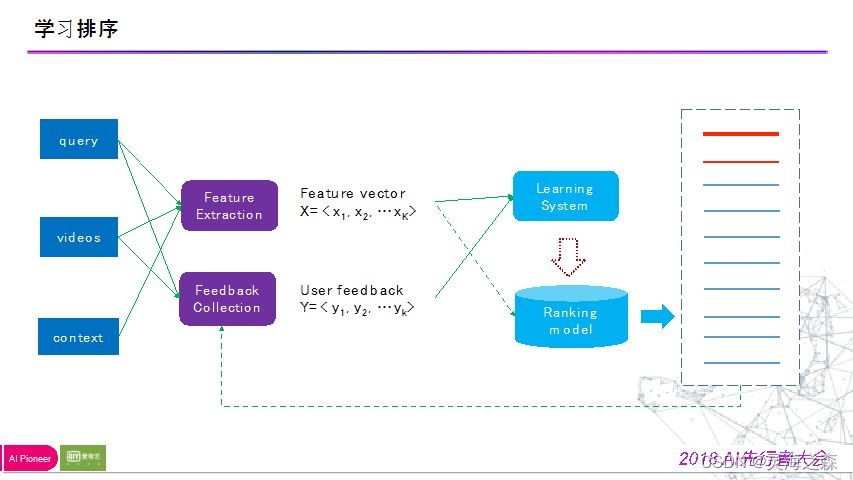
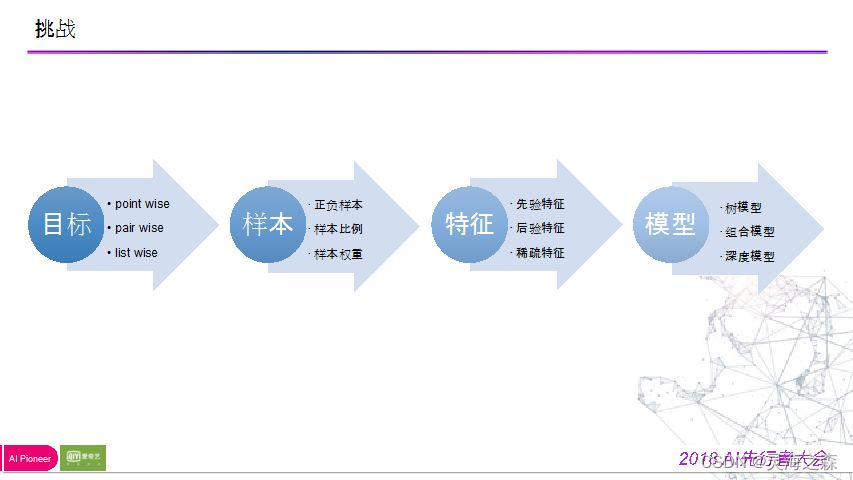
1.目标
选择的是list wise方法。我们采用的优化指标是ndcg,这在搜索引擎中是应用的非常广泛的评价指标。它包含两个参数:
r(i)代表第i个结果的相关性,
i代表i个结果的排序位置。
直观理解:i越小,r(i)越大,ndcg越大,越靠前的结果约相关,这个指标就越高。
2.样本
用户的点击行为,点击并不代表喜欢,点击后的行为也需要考虑进来。

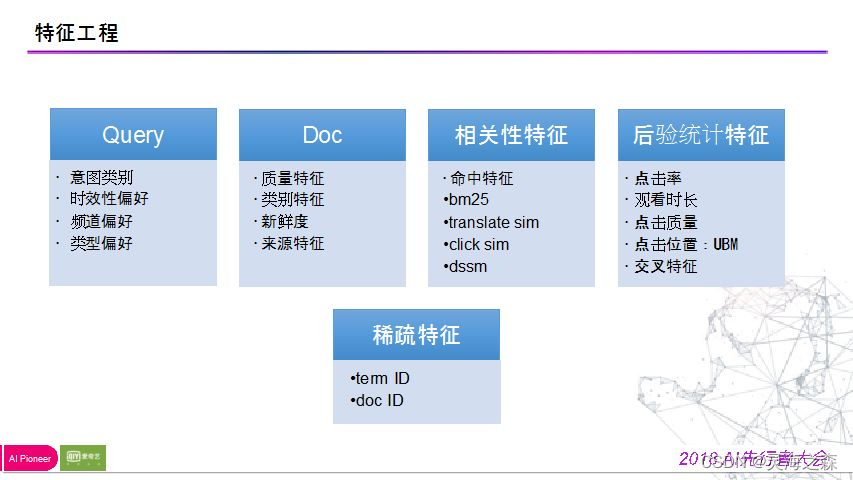
3.特征
如何把排序场景描述的非常准确,把固定问题泛化,在向量的维度表达出来,即特征提取。
Query维度:意图类别(喜欢那个类型的数据),时效性偏好
document维度:质量特征(码流、码率、用户评论、视频帧、视频标签、类别、来源等);相关性特征:命中特征,bm25等
后验特征:包括用户真实点击率,观看时长,满意程度、点击位置(马太效应影响)、各种维度交叉特征
4.模型
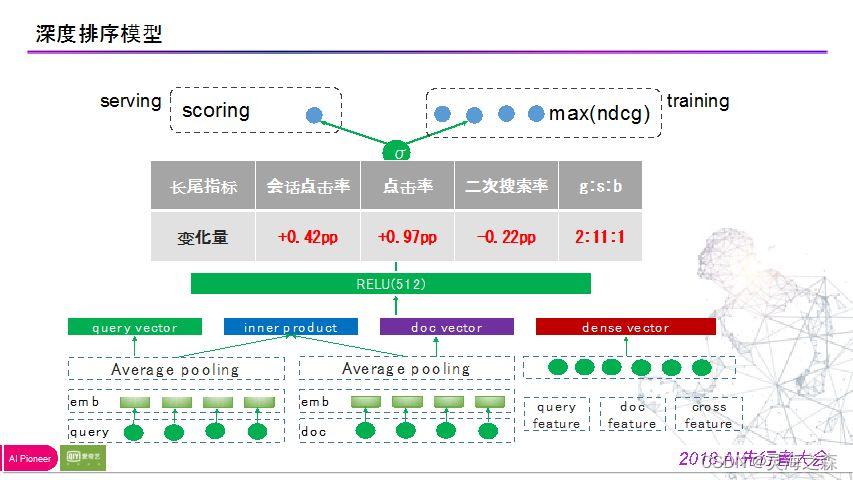 dnn排序框架。
dnn排序框架。
底层是query和document的一些描述文本做多粒度切词,之后做embedding然后做加权平均,得到document和query的向量表达,拼接这两组向量,同时再做点积,(两个向量越来越相近,拼接的时候希望上层网络学到两个向量的相似性,需要有足够的样本和正负样例,所以我们自己做了点积),同时用稠密特征,即在gbdt中用到的特征抽取出来,与embedding特征做拼接,最后经过三个全连接层,接sigmoid函数,就可以得到样本的score,并在此基础上用ndcg的衡量标准去计算损失,从而反向优化网络结构。
参考
https://mp.weixin.qq.com/s?__biz=MzU1NTMyOTI4Mw==&mid=2247487111&idx=1&sn=0466151a7745795694ee6b66838ef263&chksm=fbd4bcebcca335fd6038ab853b9a73ce1147c953594df2aea6fd1c1db013191086f4c656f5d2&scene=27#wechat_redirect
这篇关于搜索推荐技术-爱奇艺搜索引擎技术的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





