本文主要是介绍Neural Task Graphs: Generalizing to Unseen Tasks from a Single Video Demonstration,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
科研相关
- 读论文目的:
- 目标: 完成上层任务规划
- 输入: 总任务
- 输出: n * (操作 + 参数)
- 论文题目:Neural Task Graphs: Generalizing to Unseen Tasks from a Single Video Demonstration
- 论文地址:论文地址
- 论文视频:视频从 23:56 开始讲这篇论文
- 会议官网:CVPR 2019
- 论文目的:在指定的域中,只有一个完成任务的视频演示,我们需要根据这个演示生成一个策略,用来完成一个没有见过的任务
Abstract
- 作者假定为了能借助单次演示完成复杂的任务,明确地将任务的组合结构合并到模型中是必要的
- 为此作者提出了 Neural Task Graph (NTG) Networks,用共轭任务图作为中间表示,对视频演示和衍生策略进行了模块化
- 实现的两个例子:
- Block Stacking in BulletPhysics
- Object Collection in AI2-THOR
- NTG 通过可视化输入提高了数据效率,同时实现了强大的泛化,而不需要密集的分层监督
- 当应用到真实世界的数据时,类似的性能仍然存在,作者证明 NTG 能有效地预测 JIGSAWS 手术数据集上的任务结构并推广到看不见的任务
1. Introduction
- 直接从视频中学习,对将现有的模仿学习方法推广到真实世界场景至关重要,因为在每个视频中注释状态(如物体轨迹)是不可行的
- 作者关注的是 long-horizon 任务,因为现实世界的任务,如烹饪或组装,本质上是 long-horizon 长期的和 hierarchical 分层的
- 作者将任务结构和策略组合建模,从而将一次性视觉模仿扩展到复杂的任务
- 在 Visual Question Answering 和 Policy Learning 中,使用组合性建模可以获得更好的泛化效果
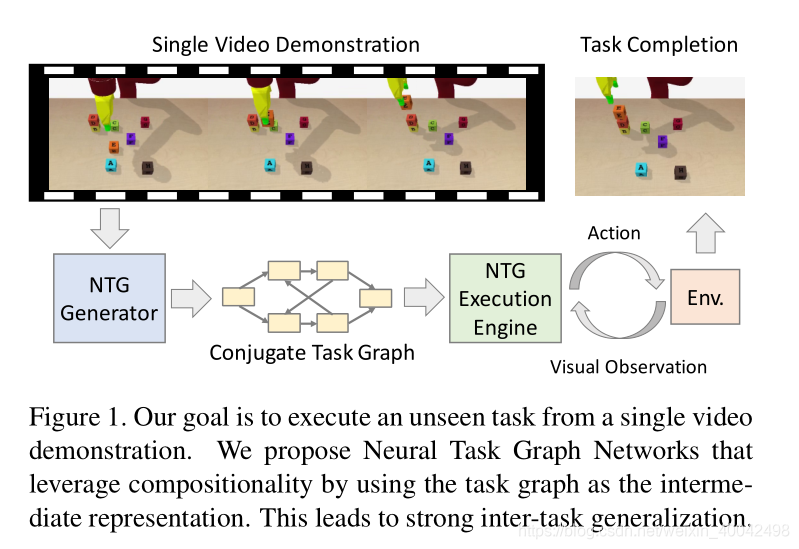
- 作者提出了 NTG 网络,这是一种以任务图作为中间表示的新框架,对视化演示和衍生策略进行了模块化
- NTG 由一个 generator 生成器和一个 execution engine 执行引擎组成,其中生成器从任务演示视频中构建一个任务图来捕获任务的结构,而执行引擎与环境交互并执行任务,该任务以推断的任务图为条件
- 挑战:未见过的演示很容易引出训练过程中从未观察过的状态,举个例子:一个未见过的块堆叠任务的目标状态,是在训练过程中从未出现的
- 这篇论文的目标是在没有强大监督的情况下从视觉观察中学习,这就放大了这种挑战,这种方法模糊了状态结构,并阻止了直接分解状态空间.
- 虽然存在无数种可能的 state 状态,但在一个特定的域中,可能的 action 操作的数量是有限的
- 作者利用 state 状态和 action 动作之间的共轭关系,并提出在 Conjugate Task Graph (CTG) 共轭任务图上学习 NTG,其中节点是动作,边是状态
- 此外,CTG 的中间表示可以产生 yield alternate action sequences 交替动作序列来完成任务,这一特性对于在随机动力学世界中泛化看不见的场景至关重要
- 这使得 NTG 与以前的工作不同,以前的工作是在一个演示中直接用 options 或 actions 动作输出策略
- Block Stacking in BulletPhysics 和 Object Collection in AI2-THOR 这两个任务都涉及到 multi-step planning for interaction 交互的多步骤规划,并且本质上是 compositional 组成的
- 本研究的主要成果有:
- 为 task 任务和 policy representation 策略表现引入组合性,实现 long-horizon 任务的一次性视觉模仿学习;
- 提出神经任务图 (NTG) 网络,这是一种利用任务图来捕获任务结构和目标的新框架;
- 利用共轭任务图 (CTG) 分解视觉状态
2. Related Work
- Imitation Learning 模仿学习
- 传统模仿学习:物理指导或远程操作作为演示
- 第三人称模仿学习使用来自其他 agent 观察者的数据
- NTP 和我们的工作很相似,NTP 使用强大的分层框架进行监督学习,在可视化状态时,性能明显下降
- 我们的方法减少了强监督的需要,在训练过程中只需要演示动作序列,同时提升了 25% 的成功率
- Task Planning and Representations 任务规划和表现
- 传统的任务规划侧重于高级计划和低级状态空间
- 最近的工作通过深度学习整合感知,HTN 将低级子任务组合为高级抽象,以降低规划的复杂性。
- 与以前的方法不同,我们的任务图表示是 data-driven 数据驱动和 domain-agnostic 域无关的
- 我们直接从任务演示中生成节点和边
- Structural Video Understanding 结构上对视频的理解
- 从演示视频生成任务图,与对视频的理解相关
- 很难获得视频中的注解,一个解决方案是使用语言作为监督,这包括教学视频,电影脚本和字幕注释
- 我们关注的是,这种结构对任务学习有什么帮助,并为所看到的任务进行注释
- Compositional Models in Vision and Robotics 视觉和机器人的组合模型
- 最近的研究已经利用 compositionality 组合性来改善模型的泛化,包括 visual question answering 视觉问题回答和 policy learning 策略学习
- 作者证明了,同样的原理可以显著提高模仿学习的数据效率,使复杂任务的视觉学习成为可能
3. Problem Formulation

- 论文的目标是通过一个视频演示来学习执行一个以前看不到的任务
- 作者将此称为单次视觉模仿,来强调模型直接从视觉输入中学习
T: 感兴趣领域中所有任务的集合A: 高层次的动作集合O: 视觉观察的空间d: 视频演示τ: 任务dτ = [o1, ..., oT]: 演示完成任务Tseen: 利用很多的演示和监督进行训练Tunseen: 利用单个演示进行测试φ(·): 由Tseen训练得到的模型πd(a|o): 基于视觉观察o,实例化一个策略πd(a|o),根据演示d,完成任务Tunseen- 问题可以描述为:将演示
d映射到策略φ(d) = πd(a|o)
4. Neural Task Graph Networks

φ(·)被分解为φgen(·)和φexe(·)φgen(·):G = φgen(d)根据演示d生成任务图Gφexe(·): 图形执行引擎,πd = φexe(G)执行任务图G, 作为策略πd
4.1. Neural Task Graph Generator
- 应用了 conjugate task graph 共轭任务图,将 state 状态和 action 动作关联起来,节点是动作,边和当前状态相关
Conjugate Task Graph (CTG)
- 传统任务图
G' = {V', E'}V': 状态节点E': 节点之间的有向边,表示动作- 成功执行任务,等同于按照图中到达目标节点路径执行一遍
- 但在高纬状态空间中,如何对未见过的任务,生成传统的任务图,是极具挑战的
- 因此本文提出共轭任务图
G = {V, E}V: 动作E: 状态- 这种方法是在对操作的先决条件进行编码
- 可以绕过显式的状态建模,并仍然能够通过遍历共轭任务图来执行任务
- 生成节点
- 假设在训练过程中所有的动作,都是从见过的任务中观察到的,这对于相同域的任务来说是合理的
- 将观察到的动作,作为所有的节点,目标是推断出正确的边
- 生成边:分为两步
- Demo Interpretation 演示解释:通过观察演示中的动作顺序,获得一个遍历共轭任务图的有效路径
- Graph Completion 补全图:添加演示中未观察到的边(状态)
- 虽然改变部分行为顺序可能不影响最后结果,但由于我们只有一个演示,在前面的步骤中无法得出这种互换性
- 需要训练一个 Graph Completion Network图补全网络,除了 Demo Interpretation 已有的边,它还可以添加更多适当的边
Demo Interpreter
- 输入:演示
d = [o1, ..., oT] - 输出:行动序列
A = [a1, ..., aK], 其中的ai都是在演示中执行的行动,这些ai也同样都是在 CTG 中的初始节点(论文中这里似乎出现了笔误,写成了 the initial edges)

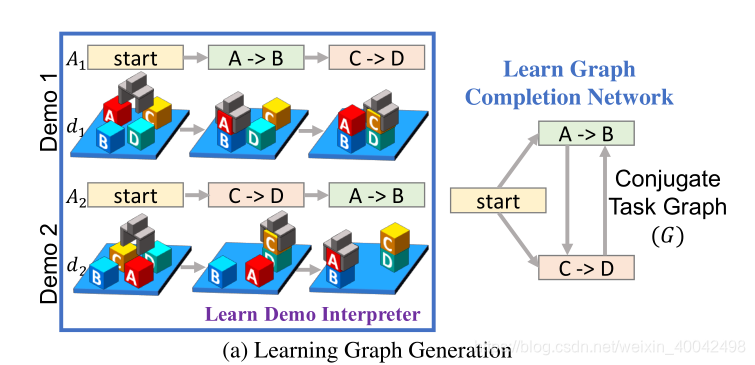
- 作者采用了 machine translation literature 机器翻译文献中的
seq2seq模型作为 demo interpreter 演示解释器 - 这里的关键是,动作序列
A为我们的共轭任务图,提供了合理的初始动作顺序约束(边)
Graph Completion Network (GCN)
- 输入:Demo Interpreter 演示解释提供的行动序列
A = [a1, ..., aK] - 输出:添加演示中未观察到的边
- 这个过程可以描述为:学习图的状态转换
- Graph Completion Network (GCN) 迭代以下两步:
- edge update 更新边
- propagation 传播
- 由于这一部分涉及公式,并且有较多专有名词,直接上图

4.2. Neural Task Graph Execution
- 本文提出了 NTG execution engine NTG 执行引擎,通过执行任务图与环境交互
- NTG execution engine 通过以下两步来执行任务图:
- Node Localization 节点定位 :执行引擎首先根据视觉观察,对图中的当前节点进行定位
- Edge Classification 边分类:对于一个给定的节点,可以有多个输出边,用于转换到不同的动作。边缘分类器检查每个可能的下一步动作的(潜在的)先决条件,并选择最适合的一个
- 这两个步骤,可使执行引擎使用生成的共轭任务图作为反应策略,来完成任务给定的观察
- 由于这一部分涉及公式,并且有较多专有名词,直接上图
n: 当前节点o: 视觉观察l(n|o): 当前节点的定位ϵ(a|n,o): 边分类器π(a|o) ∝ ϵ(a|n,o)l(n|o)边分类器根据n当前节点和o视觉观察,加上当前节点的定位,决定边转移,这等同于选择对应的下一个动作a

Node Localizer

- 一个节点的概率,与编码过的视觉观察 Enc(o) 和嵌入该节点的节点 NE loc(n) 的内积成正比
- 因为节点是动作,并且是之前见过的任务中的动作,作者容易高效学习 node embeddings
- 这体现了模块化作者策略的好处,使得子模块更加一般化
Edge Classifier
- 边分类器是 NTG 算法推广到未见过任务的关键
- 与 Localizer 不同,边分类器是近似的


- 例子:目标是将 A B C 依次堆叠,除非 B 在 A 上,否则不应该操作 C,边分类器应该识别出涉及 C 的行动前提条件
- 式子解读有困难
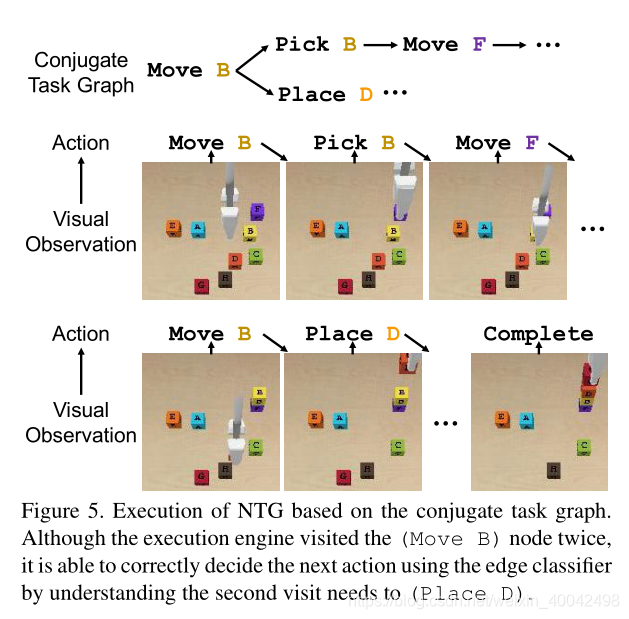
4.3. Learning NTG Networks
- NTG 只需要原始视觉观察和平面动作序列

Learning Graph Generation

- 任务
τ,演示dτi,对应的执行动作Aτi = [a1, ..., aK] - 先将
Ai转化为路径{Pτi = (V, Eτi)},节点V是所有动作ai,并添加从Ai过渡到Ei的边 - 对于单个任务
τ,作者使用任务τ路径演示路径的并集,作为 ground truth 正确标注的共轭任务图gτ的边Et - GCN 的目标是,将每个
Pτi通过补全缺失边转化成gτ - 作者通过 binary cross entropy loss (pytorch 有) 训练 GCN,输入的
Pτi,训练生成gτ
Learning Graph Execution
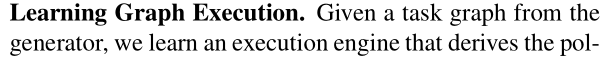

- 从生成器中给出一个任务图,我们就可以学习一个导出策略的执行引擎
- 作者将策略分解为节点定位器和边分类器
- 对于定位器,使用视频帧作为输入,使用来自演示的相应动作标签作为目标
- 对于边分类器,收集通过转换连接的所有 source-target 源-目标节点对,并使用演示中的动作标签作为目标
- 此外,边分类器使用从图补全网络嵌入的节点
- 这个想法是,来自 GCN 的嵌入可以通知边分类器,它应该分类什么样的视觉状态,并学习将其推广到看不见的任务
5. Experiments
- 结果肯定是很好的,但是,我们需要先把上面的东西弄懂
这篇关于Neural Task Graphs: Generalizing to Unseen Tasks from a Single Video Demonstration的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




