本文主要是介绍AP考试-并行处理-1分钟最大处理多少件数据?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
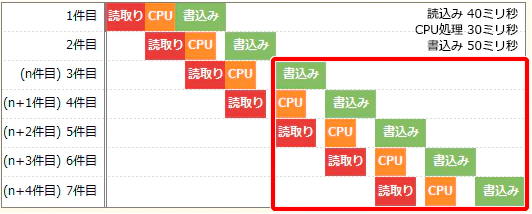
某程序处理1件数据时,读取需要 40 毫秒,CPU处理需要 30 毫秒,写回需要 50 毫秒。
该程序中,第 n 件写回、第 n+1 件CPU处理、第 n+2 件读取同步进行的话,那么 1 分钟内,
该程序最大可以处理多少件数据。不考虑任何系统开销时间。
本题咋看还是蛮唬人的哈。并行处理嘛,肯定要画个图,然后看看 1 分钟(60000毫秒)可以处理多少件。
把图画下来的话,大概像这样:
这里需要注意的是,题意中的,写-CPU处理-读,是一套并行操作,以最长的写为间隔,
那么就是写所花时间即为处理一件数据的时间了。
所以 60000毫秒/50毫秒 = 1200 件,即为最大处理件数。
(图From:https://www.ap-siken.com/kakomon/25_aki/q15.html)
这篇关于AP考试-并行处理-1分钟最大处理多少件数据?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




