本文主要是介绍【华为数据之道学习笔记】3-1 基于数据特性的分类管理框架,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
华为根据数据特性及治理方法的不同对数据进行了分类定义:内部数据和外部数据、结构化数据和非结构化数据、元数据。其中,结构化数据又进一步划分为基础数据、主数据、事务数据、报告数据、观测数据和规则数据。
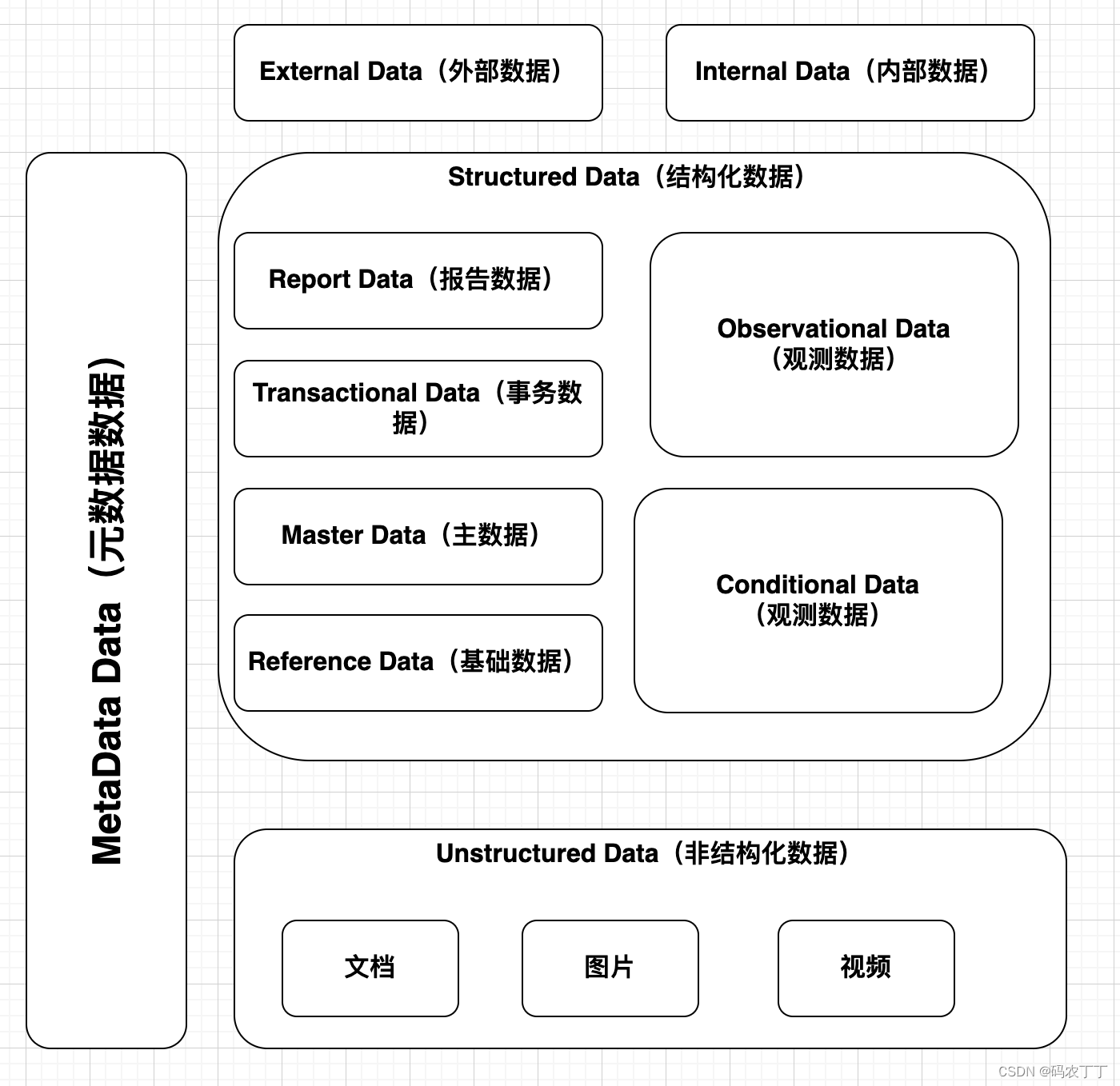
对上述数据分类的定义及特征描述。
| 分类维度 | 数据分类名称 | 定义 | 特征 | 举例 |
| 按数据主权所属华为内部/外部数据 | External Data(外部数据) | 华为通过公共领域获取的数据 | 客观存在,其产生、修改不受我司影响 | 国际、币种、汇率 |
| 从数据存储特性分为结构化和非结构化数据 | Internal Data(内部数据) | 企业内部经营生产的数据 | 在企业的业务流程中产生或在业务管理规则中定故意,受企业经营影响 | 合同、项目、组织 |
| Structured Data (结构化数据) | 可以存储在关系数据库里,用二维表结构来表达实现的数据 | 1)可以用关系数据库存储 2)先有数据结构,再产生数据 | 国家、币种、组织、产品、客户 | |
| Unstructured Data (非结构化数据) | 形式相对不固定,不方便用数据库二维逻辑表来表现的数据 | 1)形式多样,无法用关系数据库存储 2)数据量通常较大 | 网页、图片、视频、音频、XML | |
| Reference Data (基础数据) | 用结构化的语言描述属性,用于分类或目录整编的数据,也称作参考数据 | 1)通常有一个有限的允许/可选值范围 2)静态数据,非常稳定,可以用作业务/IT的开关、职责/权限的划分或统计报告的维度 | 合同类型、职位、国家、币种 | |
| Master Data (主数据) | 具有高业务价值的,可以在企业内跨流程跨系统被重复使用的数据,具有唯一、准确、权威的数据源 | 1)通常是业务事件的参与方,可以在企业内跨流程、跨系统重复调用 2)取值不受限于预先定义的数据范围 3)在业务事件发生之前就客观存在,比较稳定 | 实体型组织、客户、人员基础配置 | |
| Transactional Data (事务数据) | 用于记录企业经营过程中产生的业务事件,其实质是主数据之间活动产生的数据 | 1)有较强的时效性,通常是一次性的 2)事务数据无法脱离主数据独立存在 | BOQ、支付指令、主生产计划 | |
| Observational Data (观测数据) | 观测者通过观测工具获取观测对象行为/过程的记录数据 | 1)通常数据量较大 2)数据是过程性的,主要用作监控分析 3)可以由机器自动采集 | 系统日志、物联网数据、运输过程中国产生的GPS数据 | |
| Conditional Data (规则数据) | 结构化描述业务规则变量(一般为决策表、关联关系表、评分卡等形式)的数据,是实现业务规则的核心数据 | 1)规则数据不可实例化,只以逻辑实体形式存在 2)规则数据的结构在纵向和横向两个维度上相对稳定,变化形式多为内容刷新 3)规则数据的变更对业务活动的影响是大范围的 | 员工报销遵从性评分规则、出差补助规则 | |
| Report Data (报告数据) | 是指对数据进行处理加工后,用作业务决策依据的数据 | 1)通常需要对数据进行加工处理 2)通常需要将不同来源的数据进行清洗、转换、整合,以便更好地进行分析 3)维度、指标值都可归入报告数据 | 收入、成本 | |
| 从描述数据的手段上分类 | Meta-data (元数据) | 定义数据的数据,是有关一个企业所使用的物理数据、技术和业务流程、数据规则和约束以及数据的物理与逻辑结构的信息 | 是描述性标签,描述了数据(如数据库、数据元素、数据模型)、相关概念(如业务流程、应用系统、软件代码、技术架构)以及它们之间的联系(关系) | 数据标准、业务术语、指标定义 |
不同分类的数据,其治理方法有所不同。如基础数据内容的变更通常会对现有流程、IT系统产生影响,因此基础数据的管理重点在于变更管理和统一标准管控。主数据的错误可能会导致成百上千的事务数据错误,因此主数据的管理重点是确保同源多用、重点进行数据内容的校验等。
这篇关于【华为数据之道学习笔记】3-1 基于数据特性的分类管理框架的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






