本文主要是介绍MyStyle: A Personalized Generative Prior-论文,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

作者团队: Google
论文链接:paper
代码链接:code
1.论文简介
MyStyle:个性化人像生成式先验。论文提出MyStyle模型框架,一种用数十张个人照片训练的个性化深度生成式先验。MyStyle允许重建、增强和编辑特定人物图像,使输出高度保留此人的关键人脸特征。首先先在大数据集(FFHQ)训练StyleGAN,随后,在给定一小部分人像图像的参考集(100张),调整预训练StyleGAN人脸生成器的权重,在潜空间形成一个局部、低维、个性化流形。该流形构成了一个个性化区域,跨越了与个人不同肖像图像相关的潜代码。由此得到了一个个性化生成式先验,论文还提出了一种统一方法,将其应用于各种病态图像增强问题,如补全和超分辨率,以及语义编辑。用个性化生成式先验,得到的输出结果表现出对输入图像的高保真度,也忠实于参考集中个人的关键人脸特征。对所提出方法进行了评估,表明个性化先验在数量上和质量上都优于最先进的替代方法。
相关工作
Generative Prior
- 预训练好的GAN可以作为很多任务的先验信息,将图片映射到训练好的GAN的数据分布上面去,就可以利用GAN的先验信息对图片进行编辑、增强等操作。
- 利用GAN的隐空间作为先验信息的一个问题就是,GAN不可能拟合所以训练集图片信息的数据分布,输入新的图片的时候,所使用的先验信息不一定是准确的。在更大的数据集上进行预训练可以缓解这样的现象,但问题依旧存在,之前有部分工作提出对预训练好的GAN进行微调,来适应特定图片的分布
- 作者提出一种新的方法,对预训练好的StyleGAN进行微调,并在其微调后的子隐空间区域进行操作。
Few-Shot Generative Models
- Few-Shot Generative Models一般是在预训练好的Generative Models进行微调的,因为仅仅考Few-Shot的数据进行训练容易造成过拟合的问题。
- 大量实验表明,先前的Few-Shot Generative Models并不能很好地保留Few-Shot数据的个性化信息,作者推断,先前的研究都将Few-Shot的数据映射到整个数据分布上面去了,只保留了粗糙的特征信息,故作者提出一种方法,只将Few-Shot的数据映射到整个数据分布中的一小部分区域,并在此区域对输入进行个性化建模。
Personalization
- 先前,个性化广泛用于机器学习(如:推荐系统)、自然语言处理(如:个性化对话模型),在计算机视觉中,先前的工作有将个性图片输入网络作为提示,但个性化的信息是无法从单张图片学习到的,故论文提出MyStyle来开创这个先例。
3.论文motivation
如果给出一个人物的少量肖像图像,我们是否可以学习一个个性化先验,来为特定的人物进行脸部编辑和增强操作,同时保留该人独特的面部特征?
4.论文方法
作者的目标是利用一个小的个性化数据集(大约100张)来微调一个在FFHQ上训练过的StyleGAN,下面对方法就行具体讲解:
Adaptation
第一步是做数据域的适应,先直接利用个性化数据集,根据如下损失函数来微调StyleGAN,先让StyleGAN拥有生成编辑个性化人物的能力:
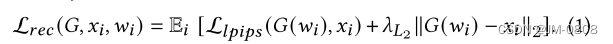
此时, G d G_d Gd、 G p G_p Gp分别表示一般化生成器、个性化生成器。
Obtaining a Personalized Sub-Space
在这里先上一幅图:
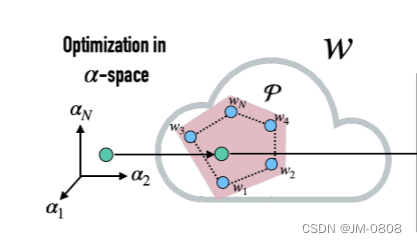
里面的凸性区域中的那些蓝色的点,作者称为anchors,作者通过实验发现沿着两个anchor进行插值和每个anchor的领域的数据都或多或少地被风格化了,如果能在这个子空间内对输入数据进行建模,就能高效地对图片进行编辑并保留其细节特征。作者通过一下利用一下两条公式(不是很懂)来确定子空间的大小,其中i为anchors的数目:
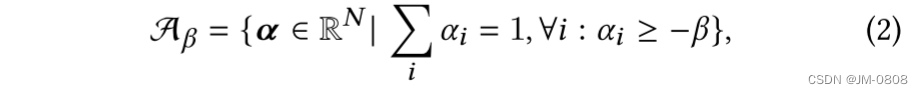
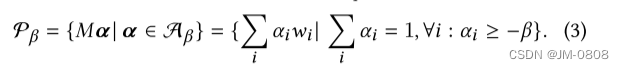
Personalized Image Enhancement
在找到的子空间中对图片进行高效建模:

5.对比
- 应用子空间和不应用子空间的ID信息对比和对anchors进行插值/领域采样的ID信息保留对比:

待更新,有些地方不是很懂呀
这篇关于MyStyle: A Personalized Generative Prior-论文的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)


