本文主要是介绍论文阅读[2023ICME]Edge-FVV: Free Viewpoint Video Streaming by Learning at the Edge,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Edge-FVV: Free Viewpoint Video Streaming by Learning at the Edge
会议信息:
Published in: 2023 IEEE International Conference on Multimedia and Expo (ICME)
作者:

1 背景
FVV允许观众从多个角度观看视频,但是如果所选视点的视频帧不能及时加载或者从相邻视点的多个视频流合成,用户可能会遇到延迟。
2 挑战
a.FVV视图合成过程可能会消耗大量的带宽和计算资源
b.更多边缘缓存可以减少每个用户虚拟视图合成延迟,但设置缓存越多,每个缓存可能存储更少的参考视点
3 贡献
a.提出了一种边缘辅助FVV系统edge-FVV
b.分析了缓存容量与延迟之间的关系,在虚拟视图合成的延迟和从服务器下载的延迟之间取得平衡
4 系统建模
4.1服务架构

a.Edge-FVV采用三层架构,由服务器、边缘缓存和用户组成
b.Edge-FVV中,选择一种易于实现的视频帧插值(VFI)方法补充两张原始参考图像之间缺失的视点
c.请求视点和合成的过程
4.2 容量与延迟的关系
部署的缓存越多,每个缓存所服务的用户就越少,从而导致缓存为用户服务所需的虚拟视图合成时间越少。
如果缓存服务的用户较少,则缓存中的引用视点数量可能较少,这反过来又会增加从服务器下载引用视点的可能性。
对于单个参考视频流𝑣𝑘被特定用户使用的概率是
𝑣𝑘 在第i个缓存中没有任何用户使用的概率为
𝑚𝑖表示存储在第i个边缘缓存中的参考视频的数量,其期望
4.2.1 视频下载和合成的延迟

4.2.2 视频下载和合成的延迟

4.3 基于机器学习的用户分配
我们将第i个用户可以连接到的边缘缓存表示为该用户的代理集𝐴𝑖,并且Ai的大小为𝑁𝐴。
有两种不同的方式来匹配第i个用户的请求与附近的缓存
(1)分布式:每个用户自主连接到Ai中的代理
基于Multi-armed bandit的分配
(2)集中式:由拥有全局信息的服务器将用户分配给Ai中的代理
基于DQN的分配
服务用户的数量和缓存的参考视频的数量首先被馈送到两个独立的神经网络(即UserNet和VideoNet)中,以嵌入用户特征和视频特征。
然后将这两个特性连接并送到ValueNet中,以生成每个缓存的Q值。
每次用户的请求到来时,服务器都会为该用户选择一个代理。
5 实验结果
5.1 边缘缓存数量的影响
当合成时间远远小于下载时间时,处理时间曲线在任意数量的边缘缓存处都会有一个局部最小值。
当下载时间远小于合成时间时处理时间近似于反比曲线,增加更多边缘缓存的效果随着服务器数量的增加而减小。
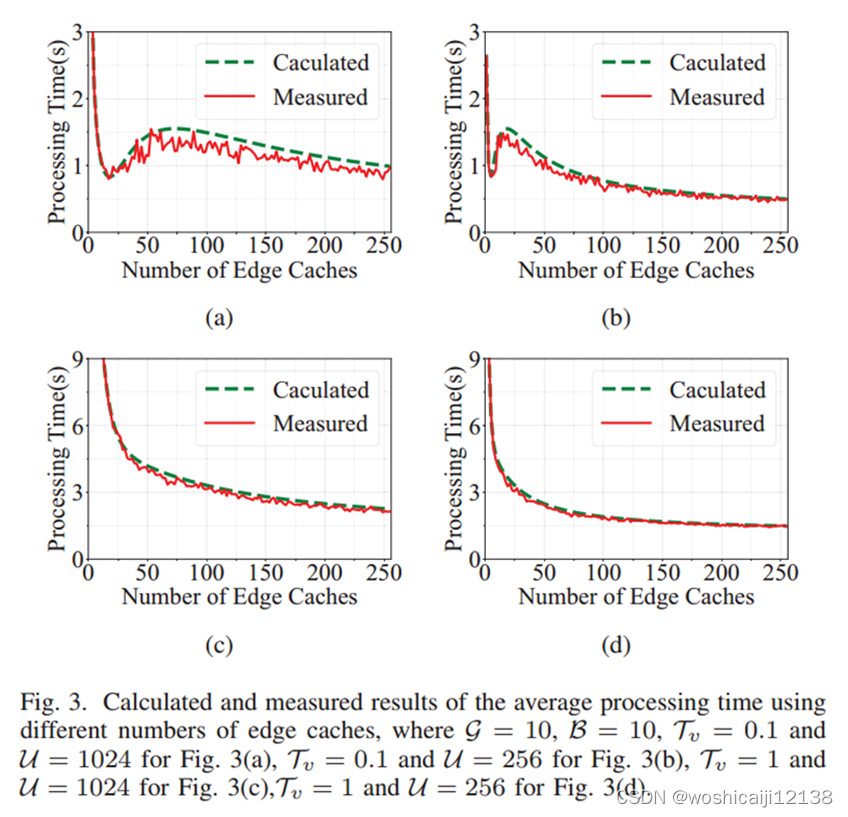
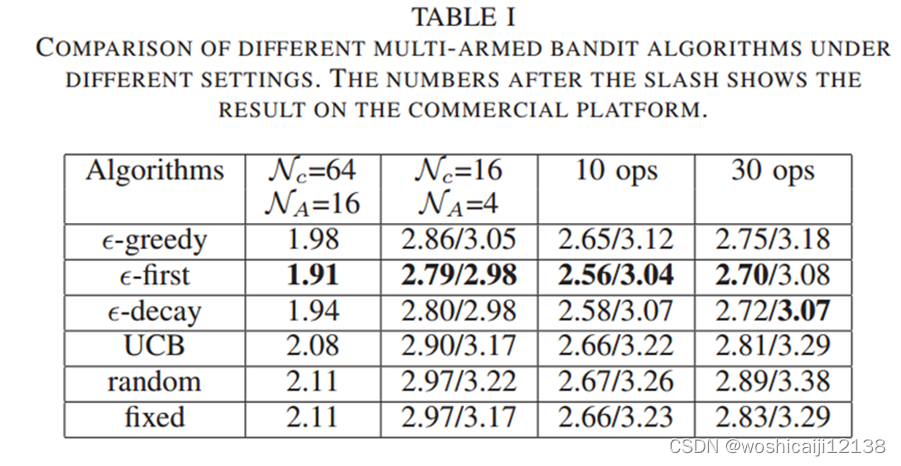
5.2 Comparison of Multi-armed Bandit Algorithms
比较方法:1让用户随机选择代理;2让他们连接到固定边缘缓存

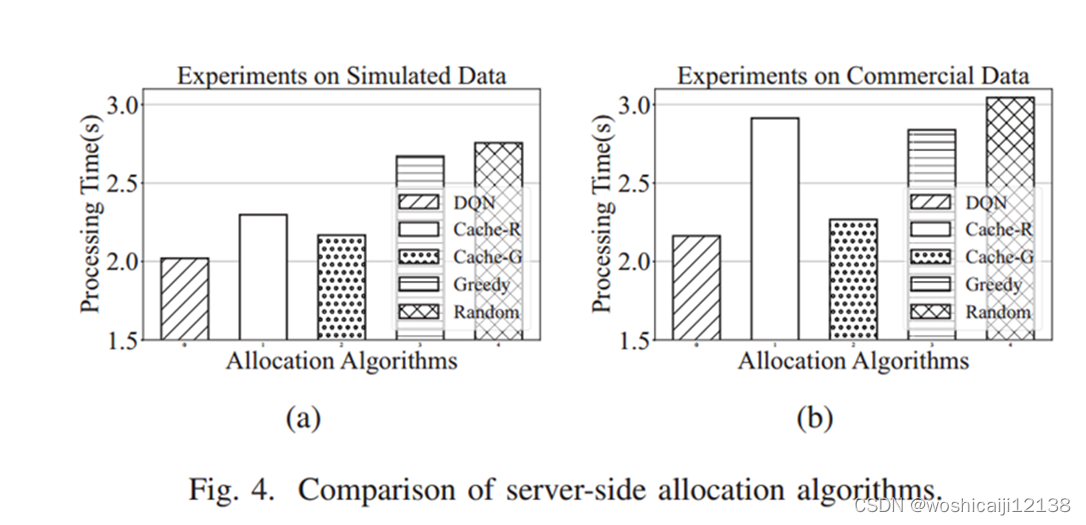
5.3 DQN的评估
比较方法:1将用户分配到用户最少的边缘缓存的算法;2随机选择缓存中有所需参考视频的边缘缓存的算法;3在所有缓存中有所需视频的边缘缓存中选择用户最少的边缘缓存的算法
与比较的所有算法中性能最好的相比,DQN减少了4.6-6.8%的总处理时间。
6 评价
优点
方案较简单
缺点与改进
a.评估指标单一
b.合成的新视点视频复用
c.缺乏缓存之间的协同
d.缺乏对用户观看视点的预测机制
e.组播
f.不同质量级别的FVV参考视频
这篇关于论文阅读[2023ICME]Edge-FVV: Free Viewpoint Video Streaming by Learning at the Edge的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)