本文主要是介绍科技论文中的Assumption、Remark、Property、Lemma、Theorem、Proof含义,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、背景
学控制、数学、自动化专业的学生在阅读论文时,经常会看到Assumption、Remark、Property、Lemma、Theorem、Proof等单词,对于初学者可能不太清楚他们之间的区别,因此这里做一下详细的说明。
以机器人领域的论文为例。
论文题目:Adaptive robust coordinated control of multiple mobile manipulators interacting with rigid environments
期刊:控制顶刊Automatica
二、Assumption
Assumption:顾名思义假设的意思,通常在给出一些定理或证明之前有一些假设,一般写在Lemma、Proof的前面,如下图所示:

三、Remark
Remark:备注、标注。可以出现在论文中的任何位置,对论文中感觉重要的地方突出说明,或者对文中的某些条件进行说明,如下图所示:

四、Property
Property:性质,列举出论文中的一些重要性质,一般是约定俗成的性质,方便后期的证明。
如机器人领域中经常看到的一个性质,M-2C为斜对称矩阵
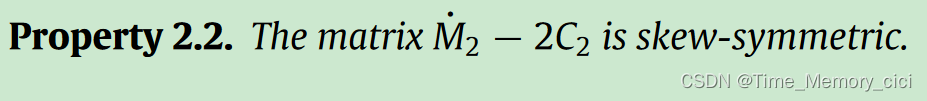
五、Lemma
Lemma:引理。一般是现有论文已经证明出的结论,我们在自己论文中Proof时需要用到,所以通常写在Proof前面。
六、Theorem
Theorem:定理。非常重要,也就是论文中的创新点和主要贡献,它是自己论文中推导出的理论,一般写在Lemma之后,Proof之前,Proof要证明的就是你的Theorem是否合理。
七、Proof
Proof:证明,这个就不用多说了,就是证明论文中你提出的Theorem
这篇关于科技论文中的Assumption、Remark、Property、Lemma、Theorem、Proof含义的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)