本文主要是介绍Milvus 2.0 质量保障系统详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
编者按:本文详细介绍了 Milvus 2.0 质量保障系统的工作流程、执行细节,以及提高效率的优化方案。
质量保障总体介绍
测试内容的关注点
开发团队与质量保障团队如何协同
Issue 的管理流程
发布标准
测试模块介绍
总体介绍
单元测试
功能测试
部署测试
可靠性测试
稳定性和性能测试
提效方法和工具
Github Action
性能测试
质量保障总体介绍
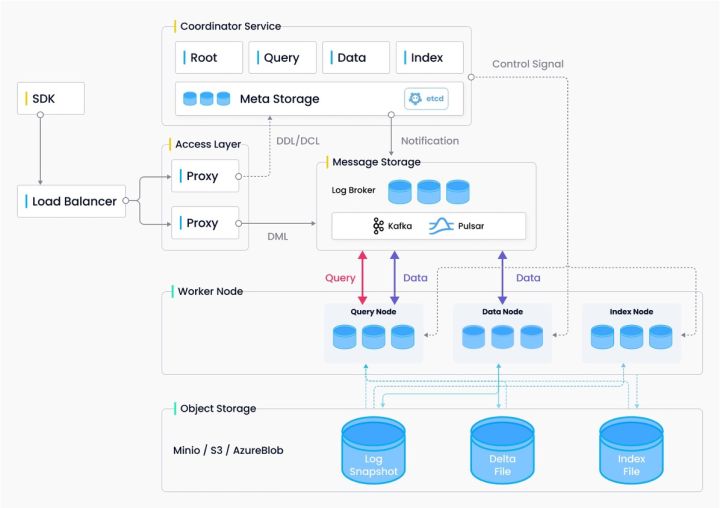
架构设计图对于质量保障同样重要,只有充分了解被测对象,才能制定出更合理和高效的测试方案。Milvus 2.0 是一个云原生、分布式的架构,主要的入口通过 SDK 进入,内部有很多分层的逻辑。因而对于用户来说,SDK 这一端是非常值得关注的一部分,对 Milvus 测试时,首先会对 SDK 这一端进行功能测试,并通过 SDK 去发现 Milvus 内部可能存在的问题。同时 Milvus 也是一个数据库,因此关于数据库的各种系统测试也会涉及到。
云原生、分布式的架构,既会给测试带来好处,也会引入各种挑战。好处在于,区别于传统的本地部署运行,在 k8s 集群中部署和运行能尽可能保证软件在开发和测试时环境一致。挑战则是分布式的系统变得复杂,引入了更多的不确定性,测试工作量和难度的增加。例如微服务化后服务数量增加、机器的节点会变多,中间阶段越多,出错的可能性越大,测试时就需要考虑各个情况。
测试内容的关注点
根据产品的性质、用户的需求,Milvus 测试的内容与优先级如下图所示。

首先在功能(Function)上,关注接口能否与设计的预期符合。
其次在部署(Deployment)上,关注 standalone 或者 cluster 模式下重启和升级是否能成功。
第三在性能(Performance)上,因为是流批一体的实时分析数据库,所以对于速度会更重视,会更关注插入、建立索引、查询的性能。
第四在稳定性(Stability)上,关注 Milvus 在正常的负载下的正常运行时间,预期目标是 5 - 10天。
第五在可靠性(Reliability)上,关注错误发生时 Milvus 的表现,以及错误消除是否还能正常工作。
第六是配置问题(Configuration),需要验证每个开放出来的配置项能否正常工作,变更能否生效。
最后是兼容性问题(Compatibility),主要是体现在硬件上和软件配置上。
由图可知,功能和部署是放在最高等级的,性能、稳定性、可靠性放在第二等级,最后将配置和兼容性放在第三的位置。不过,这个等级重要性也是相对而言的。
开发团队与质量保障团队如何协同
一般用户会认为质量保证的任务是仅仅分配给质量保证团队的,但是软件开发过程中,质量需要多方团队合作以得到保障。

最开始的阶段由开发设计文档,质量保障团队根据设计文档写测试计划。这两个文档需要测试和开发共同参与以减少理解误差。发布前会制定这一版本的目标,包括性能、稳定性、bug 数需要收敛到什么程度等。在开发过程中,开发侧重于编码功能的实现,功能完成之后质量保障团队会进行测试和验证。这两个阶段会轮巡很多遍,质量保障团队和开发团队需要每天保持信息同步。此外,除了本身功能的开发验证,开源的产品还会收到很多来自于社区的问题,也会根据优先级进行解决。
在最后阶段,如果产品达到了发布标准,团队就会选定一个时间节点,发布一个新的镜像。在发布前需要准备一个 release tag 和 release note,关注这个版本实现了什么功能,修复了什么 issue,后期质量保障团队也会针对这个版本出一个测试报告。
Issue 的管理流程
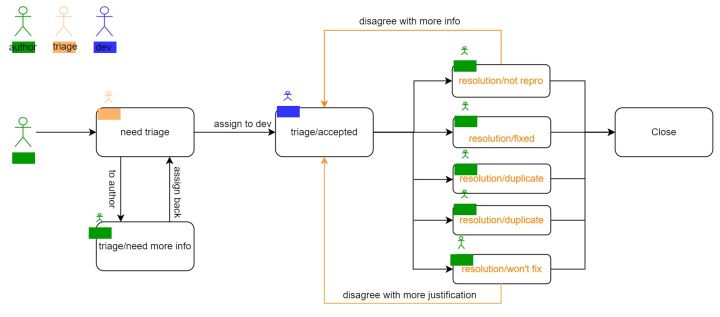
质量保障团队更多地关注于产品开发中的 issue。Issue 的作者除了质量保障团队的成员,还有大量的外部用户,因此需要规范每个 issue 的填写信息。每个 issue 都有一个模板,要求作者提供一些信息,例如当前使用的版本,机器配置信息,然后你的预期是什么?实际的返回结果是什么?如何去复现这个 issue,然后质量团队和开发团队会继续去跟进。
在创建这个 issue 之后,首先会 assign 给质量保障团队的负责人,然后负责人会对这个 issue 进行一些状态流转。如果 issue 成立且有足够多的信息,后续会有若干种状态,如:是否解决了;是否能复现;是否与之前有重复;出现概率大小;优先级大小。如果确认存在缺陷,开发团队会提交 PR,关联上这个 issue,进行修改。在得到验证后,这个 issue 会被关闭,如果之后发现依然存在问题,还可以 reopen。此外,为了提高 issue 的管理效率,还会引入标签和机器人,用于对 issue 分类和状态流转。
发布标准
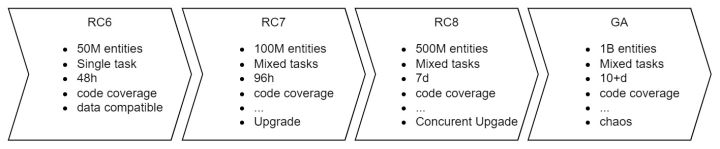
能否发布主要指当前这个版本能否达到预期要求。例如上图是一个大致的情况,RC6 到 RC7,RC8 和 GA 的标准。随着版本的推进,对 Milvus 的质量提出更高的要求:
- 从原先 50M 的数量级,逐渐演进到 1B 的数量级
- 在稳定性的任务运行中,由单任务变成混合任务,时长逐渐由小时级变成天级
- 对于代码而言,也在逐渐提高它的代码覆盖率
- ……
- 此外,随着版本的更替,也会加入其他的测试项。例如在 RC7 的时候,提出了要有一个兼容项,升级的时候要有兼容;在 GA 的时候,引入更多关于混沌工程的测试
测试模块介绍
第二部分是关于每个测试模块的一些具体细节。
总体介绍
业界有写代码就是写 bug 的戏谑,从下图可以看到,85%的 bug 是由 coding 阶段引入的。
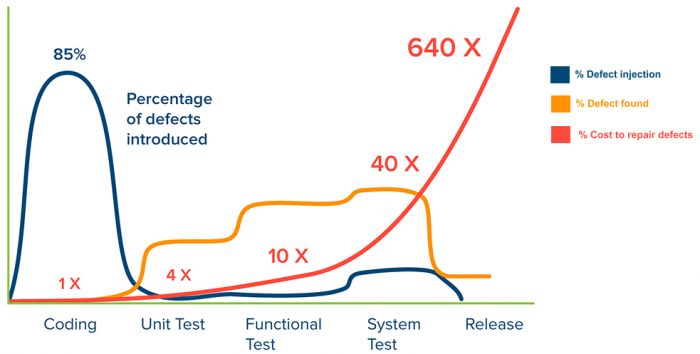
从测试的角度来看,代码编写到版本发布这个过程中,依次可以通过 Unit Test / Functional Test / System Test 去发现 bug;但是随着阶段的推移,修复 bug 的成本也会递增,所以往往倾向于早发现早修复。不过,每个阶段的测试有自己的侧重点,不可能只通过一种测试手段就发现所有的 bug。
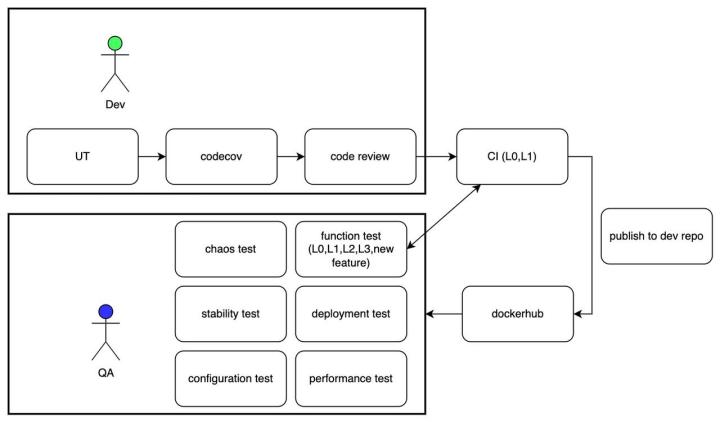
开发从编写代码到代码合并到主分支这个阶段分别会从 UT、code coverage 和 code review 去保障代码质量,这几项也体现在 CI 中 。在提交 PR 到代码合并的过程中,需要通过静态代码检查、单元测试、代码覆盖率标准以及 reviewer 的代码审核。
在合并代码时,同样需要通过集成测试。为了保证整个 CI 的时间不会太长,在这个集成测试里面,主要运行 L0 和 L1 这些具有高优先级标签的 case。通过所有检查后,就可以到 milvusdb/milvus-dev 仓库中发布这个 PR 构建的镜像。在镜像发布之后,会设置定时任务对最新的镜像进行前文提到的多种测试:全量的原有功能测试,新特性的功能测试,部署测试,性能测试,稳定性测试,混沌测试等。
单元测试
单元测试可以在尽可能早的阶段发现软件存在的 bug,同时也可以为代码重构提供验证标准。在 Milvus 的 PR 准入标准中,设定了代码的单元测试 80% 覆盖率目标。
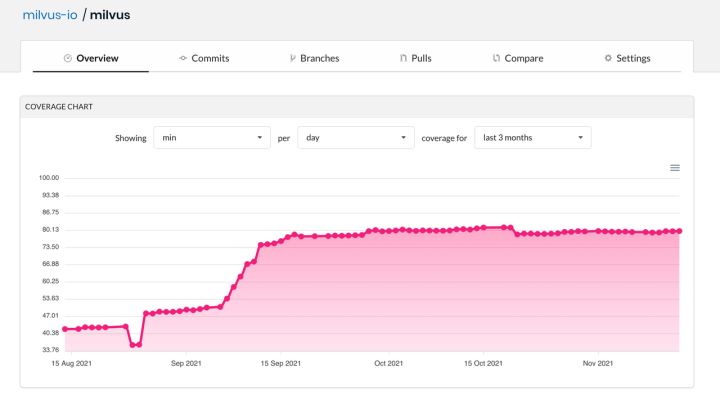
https://app.codecov.io/gh/milvus-io/milvus/
功能测试
对 Milvus 的功能测试,主要是通过 pymilvus 这个 SDK 作为切入点。
功能测试主要关注于接口能否按照预期工作。
- 输入正常的参数或采用正常的操作时,SDK 是否能返回预期的结果
- 当参数或操作是异常的时候,SDK 是否能 handle 住这些错误,同时能够返回一些合理的错误信息
下图是当前的功能测试框架,整体而言是基于目前主流的测试框架 pytest,并对 pymilvus 进行了一次封装,提供了接口自动化测试能力。
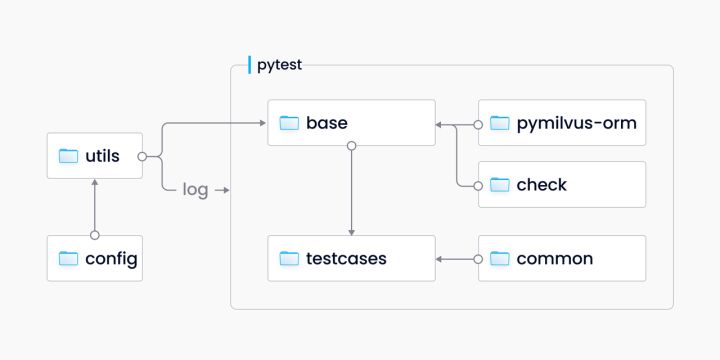
采用上述测试框架, 而不是直接用 pymilvus 原生的接口,是因为在测试过程中需要提取出一些公共方法,复用一些常用的函数。同时也会封装一个 check 的模块,能更方便地去校验一些预期和真实值。
当前 tests/python_client/testcases 目录下的功能测试用例已经有 2700+,基本上覆盖了 pymilvus 的所有接口,且包含正面用例和反面用例。功能测试作为 Milvus 的基本功能保障,通过自动化和持续集成,严格把控每一个提交的 PR 质量。
部署测试
部署测试中,支持 Milvus 部署形态有 standalone 和 cluster ,部署的方式有 docker 或者 helm。部署完成之后,需要对系统执行 restart 和 upgrade 的操作。
重启测试,主要是验证数据的持久化,即重启前的数据在重启后能否继续使用;升级测试,主要是验证数据的兼容性,防止在不知情的情况下引入了不兼容的数据格式。
重启测试和升级测试可以统一为如下的测试流程:

如果是重启测试,两次部署使用相同镜像;如果是升级测试,第一次部署使用旧版本镜像,第二次部署使用新版本镜像。第二次部署时,无论是重启还是升级,均会保留第一次部署后的测试数据( Volumes 文件夹或者 PVC )。在 Run first test 这个步骤中,会创建多个 collection,并对每个 collection 执行不同的操作,使其处于不同的状态,例如:
- create collection
- create collection --> insert data
- create collection --> insert data -->load
- create collection --> insert data -->flush
- create collection --> insert data -->flush -->load
- create collection --> insert data -->flush --> create index
- create collection --> insert data -->flush --> create index --> load
- ......
在 Run second test 这个步骤中会进行两种验证:
- 之前创建的 collection 各种功能依然可用
- 可以创建新的 collection,同样各种功能依然可用
可靠性测试
当前针对云原生,分布式产品的可靠性,大部分的公司都会通过混沌工程的方法进行测试。混沌工程旨在将故障扼杀在襁褓之中,也就是在故障造成中断之前将它们识别出来。通过主动制造故障,测试系统在各种压力下的行为,识别并修复故障问题,避免造成严重后果。
在执行 chaos test 时,选择了 Chaos Mesh 作为故障注入工具。Chaos Mesh 是 PingCAP 公司在测试 TiDB 可靠性的过程中孵化出来的,非常适合用于云原生分布式数据库的可靠性测试。
在故障类型中,实现了以下几种故障类型:
- 首先就是 pod kill,测试范围是所有的组件,模拟节点宕机的情况
- 其次 pod failure,主要是关注于 work node 的多副本情况下,有一个 pod 不能工作,整个系统还能正常运作
- 第三个是 memory stress ,侧重内存和 CPU 的压力,主要注入到 work node 的节点
- 最后一个 network partition ,即 pod 与 pod 之间的一个通信隔离。Milvus 是一个存储计算分离,工作节点和协调节点分离的多层架构,不同组件之间的通信非常多,需要通过 network partition 测试它们之间的相互依赖关系
通过建构一套框架,较为自动化地实现 Chaos Test。

流程:
- 通过读取部署配置,初始化一个 Milvus 集群
- 集群状态 ready 后,首先会运行一个 e2e 测试,验证 Milvus 的功能可用
- 运行 hello_milvus.py,主要用于验证数据的可持久化,会在故障注入前创建一个 hello_milvus 的 collection,进行数据插入,flush,create index,load,search,query。注意,不会将 collection release 和 drop
- 创建一个监测对象,该对象主要是开启 6 个线程,分别不断执行 create,insert,flush,index,search,query 操作
checkers = {Op.create: CreateChecker(),Op.insert: InsertFlushChecker(),Op.flush: InsertFlushChecker(flush=True),Op.index: IndexChecker(),Op.search: SearchChecker(),Op.query: QueryChecker()
}- 故障注入前进行第一次断言:所有操作预期成功
- 注入故障:解析定义故障的 yaml 文件,通过 Chaos Mesh,向 Milvus 系统中注入故障,例如使 query node 每 5s 被 kill 一次
- 故障注入期间进行第二次断言:判断针对故障期间的 Milvus 执行的各个操作返回的结果与预期是否一致
- 删除故障:通过 Chaos Mesh 删除之前注入的故障
- 故障删除,Milvus 恢复服务后(所有 pod 都 ready ),进行第三次断言:所有操作预期成功
- 运行一个 e2e 测试,验证 Milvus 的功能可用,因为第三次断言,有些操作会在 chaos 注入期间被阻塞,即使故障消除后,依然被阻塞,导致第三次断言不能如预期一样全部成功。因此增加这个步骤辅助第三次断言的判断,并暂时将这次 e2e 测试作为 Milus 是否恢复的标准
- 运行 hello_milvus.py,加载之前创建的 collection,并对该 collection 执行一系列操作,判断故障前的数据在故障恢复后,是否依然可用
- 日志收集
稳定性和性能测试
稳定性测试
稳定性测试的目的:
- Milvus 可以在正常水平的压力负载下,平稳运行设定的时长
- 在运行过程中,系统使用的资源保持平稳,Milvus 的服务正常
主要考虑两种负载场景:
- 读密集:search 请求 90%,insert 请求 5%, 其他 5%。这种场景主要是离线场景,数据导入之后,基本不更新,主要提供查询服务
- 写密集: insert 请求 50%,search 请求 40%,其他 10%。这种场景主要是在线场景,需要提供边插入边查询的服务
检查项:
- 内存使用量平滑
- CPU 使用量平滑
- IO 延时平滑
- Milvus 的 pod 状态正常
- Milvus 服务响应时间平滑
性能测试
性能测试的目的:
- 对 Milvus 各个接口进行性能摸底
- 通过性能对比,找到接口最佳的参数配置
- 作为性能基准,防止之后的版本出现性能下降
- 找到性能瓶颈点,为性能调优提供参考
主要考虑的性能场景:
- 数据插入性能
- 性能指标:吞吐量
- 变量:每批次插入向量数,......
- 索引构建性能
- 性能指标:索引构建时间
- 变量:索引类型,index node 数量,......
- 向量查询性能
- 性能指标:响应时间,每秒查询向量数,每秒请求数,召回率
- 变量:nq,topK,数据集规模大小,数据集类型,索引类型,query node 数量,部署模式,......
- ......
测试框架和流程
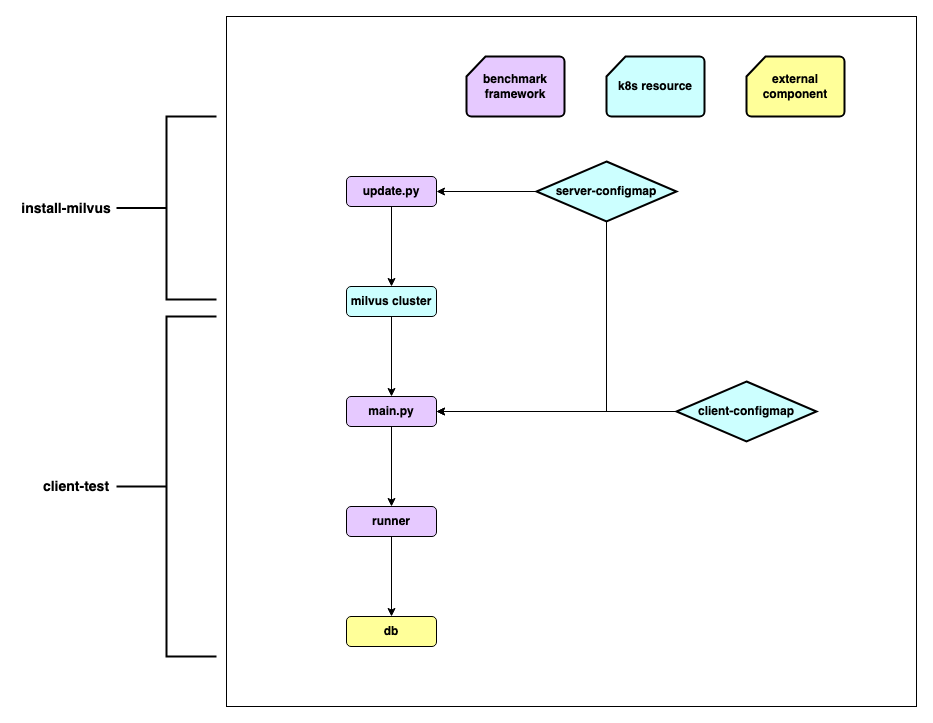
- 解析并更新配置,定义指标
- server-configmap 对应的是 Milvus 单机或者集群的配置
- client-configmap 对应的是测试用例配置
- 配置服务端和客户端
- 数据准备
- 客户端与服务端之间的请求交互
- 指标数据的上报与展示
提效方法和工具
由前文可知,测试中很多步骤流程是相同的,主要是修改 Milvus server 端的配置,client 端的配置,接口的传入参数。在多项配置下,通过排列组合,需要执行很多次实验才能比较全面地覆盖各种测试场景,因此代码复用、流程复用、测试效率就是非常重要的问题。
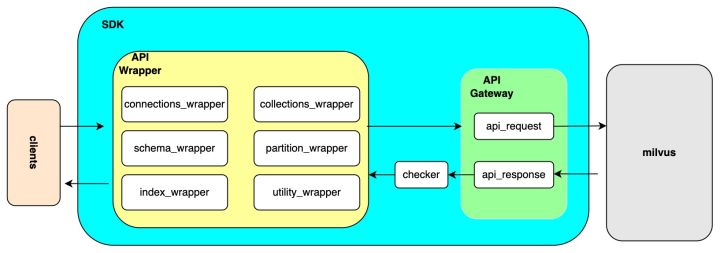
- 对原有方法进行一个 api_request 的装饰器封装,设置成类似于一个 API gateway,统一去接收所有的 API 请求,发送给 Milvus 然后统一接收响应,再返回给 client。 这样更容易去捕捉一些日志信息,比如传的参数、返回的结果。同时返回的结果可以通过 checker 模块去校验,便于将所有的检查方法定义在同一个 checker 模块
- 设置默认参数,将多个必要的初始化步骤封装成一个函数,原先需要大量代码实现的功能就可以通过一个接口实现。这种设定能够减少大量冗余重复的代码,使每个测试用例更简单清晰
- 每个测试用例都是关联独有的 collection 进行测试,保证了测试用例之间的数据隔离性。在每个测试用例的的执行起始步骤,创建新的 collection 用于测试,在测试结束后也会删除对应的 collection
- 因为每个测试用例都是互相独立的,在执行测试用例的时候,可以通过 pytest 的插件
pytest -xdist并发执行,提高执行效率
Github Action
GitHub Action 的优点:
- 与 GitHub 深度集成,原生的 CI/CD 工具
- 统一配置的机器环境,同时预装了丰富的常用软件开发工具
- 支持多种操作系统和版本:Ubuntu, Mac 和 Windows-server
- 拥有丰富的插件市场,提供了各种开箱即用的功能
- 通过 matrxi 进行排列组合,复用同一套测试流程,支持并发的 job,从而提高效率
部署测试和可靠性测试都需要独立隔离的环境,非常适合在 GitHub Action 上进行小规模数据量的测试。通过每日定时运行,测试最新的 master 镜像,起到日常巡检的功能。

性能测试工具
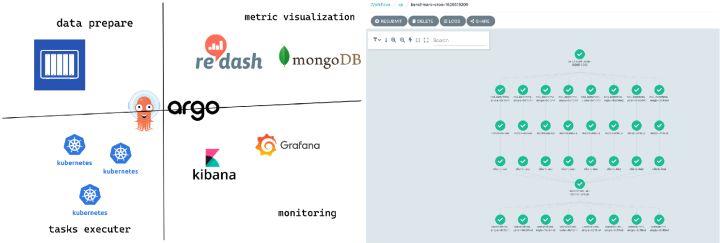
- Argo workflow:通过创建 workflow,实现任务的调度,将各个流程串联起来。从右图可以看出,通过 Argo 可以实现多个任务同时运行
- Kubernetes Dashboard:可视化 server-configmap 和 client-configmap
- NAS:挂载常用的 ann-benchmark 数据集
- InfluxDB 和 MongoDB: 保存性能指标结果
- Grafana:服务端资源指标监控,客户端性能指标监控
- Redash: 性能图表展示
完整版视频讲解请戳:
Deep dive#7 Milvus 2.0 质量保障系统详解_哔哩哔哩_bilibili
如果你在使用的过程中,对 Milvus 有任何改进或建议,欢迎在 GitHub 或者各种官方渠道和我们保持联系~
Zilliz 以重新定义数据科学为愿景,致力于打造一家全球领先的开源技术创新公司,并通过开源和云原生解决方案为企业解锁非结构化数据的隐藏价值。
Zilliz 构建了 Milvus 向量数据库,以加快下一代数据平台的发展。Milvus 数据库是 LF AI & Data 基金会的毕业项目,能够管理大量非结构化数据集,在新药发现、推荐系统、聊天机器人等方面具有广泛的应用。

这篇关于Milvus 2.0 质量保障系统详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




