本文主要是介绍Leetcode每日一题学习训练——Python3版(到达首都的最少油耗),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
版本说明
当前版本号[20231205]。
| 版本 | 修改说明 |
|---|---|
| 20231205 | 初版 |
目录
文章目录
- 版本说明
- 目录
- 到达首都的最少油耗
- 理解题目
- 代码思路
- 参考代码
原题可以点击此 2477. 到达首都的最少油耗 前去练习。
到达首都的最少油耗
给你一棵 n 个节点的树(一个无向、连通、无环图),每个节点表示一个城市,编号从 0 到 n - 1 ,且恰好有 n - 1 条路。0 是首都。给你一个二维整数数组 roads ,其中 roads[i] = [ai, bi] ,表示城市 ai 和 bi 之间有一条 双向路 。
每个城市里有一个代表,他们都要去首都参加一个会议。
每座城市里有一辆车。给你一个整数 seats 表示每辆车里面座位的数目。
城市里的代表可以选择乘坐所在城市的车,或者乘坐其他城市的车。相邻城市之间一辆车的油耗是一升汽油。
请你返回到达首都最少需要多少升汽油。
示例 1:
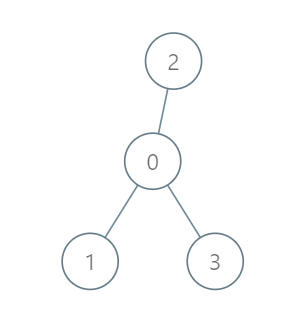
输入:roads = [[0,1],[0,2],[0,3]], seats = 5
输出:3
解释:
- 代表 1 直接到达首都,消耗 1 升汽油。
- 代表 2 直接到达首都,消耗 1 升汽油。
- 代表 3 直接到达首都,消耗 1 升汽油。
最少消耗 3 升汽油。
示例 2:
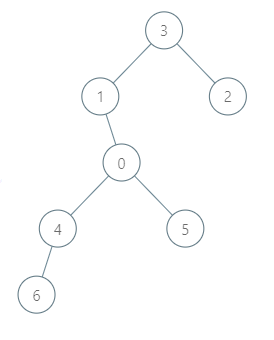
输入:roads = [[3,1],[3,2],[1,0],[0,4],[0,5],[4,6]], seats = 2
输出:7
解释:
- 代表 2 到达城市 3 ,消耗 1 升汽油。
- 代表 2 和代表 3 一起到达城市 1 ,消耗 1 升汽油。
- 代表 2 和代表 3 一起到达首都,消耗 1 升汽油。
- 代表 1 直接到达首都,消耗 1 升汽油。
- 代表 5 直接到达首都,消耗 1 升汽油。
- 代表 6 到达城市 4 ,消耗 1 升汽油。
- 代表 4 和代表 6 一起到达首都,消耗 1 升汽油。
最少消耗 7 升汽油。
示例 3:

输入:roads = [], seats = 1
输出:0
解释:没有代表需要从别的城市到达首都。
提示:
1 <= n <= 105roads.length == n - 1roads[i].length == 20 <= ai, bi < nai != biroads表示一棵合法的树。1 <= seats <= 105
理解题目
- 这个问题可以使用图的广度优先搜索(BFS)算法来解决。
- 广度优先搜索(BFS)算法是一种用于遍历或搜索树或图的算法。它从根节点开始,然后访问所有相邻的节点,然后再访问这些相邻节点的相邻节点,依此类推。
- 首先,我们需要创建一个邻接表来表示城市之间的道路关系。
- 然后,从首都开始进行BFS搜索,每次搜索时,将当前城市的汽油消耗累加到总油耗中,并更新每个城市的汽油消耗。
- 最后,返回到达首都的总油耗。
代码思路
-
它包含一个名为minimumFuelCost的方法,该方法接受两个参数:roads和seats。**roads是一个二维列表,表示城市之间的道路关系;seats是一个整数,表示每辆车的座位数。**方法的目的是计算到达首都所需的最少汽油量。
(该函数:
minimumFuelCost是函数名;
self是类实例的引用,表示这个函数是一个类的方法;
(self, roads: List[List[int]], seats: int)是函数的参数列表,包括两个参数: 一个是
roads,类型为List[List[int]],表示一个二维整数列表; 另一个是
seats,类型为int,表示一个整数。
-> int表示这个函数的返回值类型是整数。)def minimumFuelCost(self, roads: List[List[int]], seats: int) -> int: -
首先,代码创建了一个名为g的空列表,用于存储道路关系。然后,遍历roads列表,将每个城市的邻居添加到g中。
(
[[] for i in range(len(roads) + 1)]表示创建一个长度为len(roads) + 1的列表; 其中每个元素都是一个空列表。
这样做的目的是为了让每个节点都有一个与之对应的邻接表,
方便后续进行图的遍历和操作。)
# 创建一个空的邻接表g,用于存储道路关系g = [[] for i in range(len(roads) + 1)]for e in roads:# 将道路的两个端点添加到对方的邻接表中g[e[0]].append(e[1])g[e[1]].append(e[0])res = 0 # 初始化结果变量为0 -
接下来,定义了一个名为dfs的内部函数,用于深度优先搜索。这个函数接受两个参数:**cur表示当前城市,fa表示当前城市的父节点。**在dfs函数中,首先初始化一个名为peopleSum的变量,表示当前城市及其代表的人数之和。
def dfs(cur, fa):nonlocal res # 声明res为非局部变量,以便在dfs函数中修改它peopleSum = 1 # 初始化当前节点的人数为1 -
然后,遍历当前城市的代表,如果代表不是父节点,则递归调用dfs函数,并将返回的人数累加到peopleSum中。同时,更新res变量,将其加上(peopleCnt + seats - 1) // seats的结果。最后,返回peopleSum。
for ne in g[cur]: # 遍历当前节点的所有代表if ne != fa: # 如果代表不是父节点peopleCnt = dfs(ne, cur) # 递归调用dfs函数,计算代表的人数peopleSum += peopleCnt # 累加代表的人数到当前节点的人数res += (peopleCnt + seats - 1) // seats # 更新结果变量,计算所需的汽油量return peopleSum # 返回当前节点的人数 -
在主函数中,调用dfs函数,传入初始值0和-1。最后,返回res作为结果。
dfs(0, -1) # 从根节点开始调用dfs函数return res # 返回结果变量
参考代码
class Solution:def minimumFuelCost(self, roads: List[List[int]], seats: int) -> int:g = [[] for i in range(len(roads) + 1)]for e in roads:g[e[0]].append(e[1])g[e[1]].append(e[0])res = 0def dfs(cur, fa):nonlocal respeopleSum = 1 for ne in g[cur]:if ne != fa:peopleCnt = dfs(ne, cur)peopleSum += peopleCntres += (peopleCnt + seats - 1) // seatsreturn peopleSumdfs(0, -1)return res这篇关于Leetcode每日一题学习训练——Python3版(到达首都的最少油耗)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







