本文主要是介绍SQL Sever 基础知识 - 数据筛选(1),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
SQL Sever 基础知识 - 四、数据筛选
- 四、筛选数据
- 第1节 DISTINCT - 去除重复值
- 1.1 SELECT DISTINCT 子句简介
- 1.2 SELECT DISTINCT 示例
- 1.2.1 DISTINCT 一列示例
- 1.2.2 DISTINCT 多列示例
- 1.2.3 DISTINCT 具有 null 值示例
- 1.2.4 DISTINCT 与 GROUP BY 对比
- 第2节 WHERE - 过滤查询返回的行
- 2.1 WHERE 子句简介
- 2.2 WHERE 子句示例
- 2.2.1 使用简单等式查找行
- 2.2.2 查找满足两个条件的行
- 2.2.3 使用比较运算符查找行
- 2.2.4 查找满足两个条件之一的行
- 2.2.4 查找值在两个值之间的行
- 2.2.4.1 使用between...and...关键字
- 2.2.4.2 使用判断符
- 2.2.5 在值列表中查找具有值的行
- 2.2.6 查找值包含字符串的行 - 模糊查询
更多SQL Sever基础知识可查看:SQL Sever 基础知识(全)
特别说明:
本文章所用的所有数据库、数据表及其数据皆为AI随机生成,不涉及个人隐私,且仅供学习使用!
四、筛选数据
第1节 DISTINCT - 去除重复值
SELECT DISTINCT 子句来检索指定列列表中的唯一非重复值。
1.1 SELECT DISTINCT 子句简介
SELECT DISTINCT 子句语法:
SELECT DISTINCT <列名>
FROM <表名>
Note:
① 查询仅返回指定列中的非重复值,即从结果集中删除列中的重复值。
② 查询使用 SELECT 列表中所有指定列的值的组合来评估唯一性。
③ 将 DISTINCT 子句应用于具有NULL的列,则 DISTINCT 子句将仅保留一个NULL并消除另一个, DISTINCT 子句将所有NULL“值”视为相同的值。
1.2 SELECT DISTINCT 示例
1.2.1 DISTINCT 一列示例
查询CustomerInfo表中客户所在省份:
select distinct Provincefrom CustomerInfoorder by Province
执行结果:

1.2.2 DISTINCT 多列示例
查询CustomerInfo表中客户所在省份和城市:
select distinct Province,Cityfrom CustomerInfoorder by Province
执行结果:

1.2.3 DISTINCT 具有 null 值示例
1.2.4 DISTINCT 与 GROUP BY 对比
查询CustomerInfo表中客户所在省份和城市(分组查询):
select Province,Cityfrom CustomerInfogroup by Province,Cityorder by Province,City
执行结果:

与前面使用DISTINCT对比结果相同,相当于以下使用 DISTINCT 运算符的查询。
DISTINCT 和 GROUP BY 子句都通过删除重复项来减少结果集中返回的行数。但是,如果要对一个或多个列应用聚合函数,则应使用 GROUP BY 子句。
第2节 WHERE - 过滤查询返回的行
根据一个或多个条件筛选查询输出中的行。
2.1 WHERE 子句简介
使用 SELECT 语句查询一个表的数据时,会获得该表的所有行,这不一定必要,有时候可能只处理一组。要从表中获取满足一个或多个条件的行组,可使用where子句,语法如下所示:
select <列名1>,<列名2>,...from [表]where <条件>
以上语法:
① 在 WHERE 子句中,指定搜索条件以筛选由 FROM 子句返回的行。 WHERE 子句仅返回导致搜索条件计算为 TRUE 的行。
② 搜索条件是逻辑表达式或多个逻辑表达式的组合。在SQL中,逻辑表达式通常称为谓词。
③ 请注意,SQL Server使用三值谓词逻辑,其中逻辑表达式的计算结果可以是 TRUE 、 FALSE 或 UNKNOWN 。 WHERE 子句不会返回任何导致谓词计算为 FALSE 或 UNKNOWN 的行。
2.2 WHERE 子句示例
2.2.1 使用简单等式查找行
查询CustomerInfo表中已签收的所有顾客信息:
select *from CustomerInfowhere Status = '已签收'
执行结果:

2.2.2 查找满足两个条件的行
查询CustomerInfo表中广东省已签收的所有顾客信息:
select *from CustomerInfowhere Status = '已签收' and Province = '广东省'
执行结果:

2.2.3 使用比较运算符查找行
查询CustomerInfo表中已签收且年龄大于30岁的所有顾客信息:
select *from CustomerInfowhere Status = '已签收' and Age > 30
执行结果:

2.2.4 查找满足两个条件之一的行
查询CustomerInfo表中是湖北或者北京地区的所有顾客信息:
select *from CustomerInfowhere Province = '湖北省' or Province = '北京市'
执行结果:

OR 关键字:满足条件之一的任何数据都包含在结果集中
2.2.4 查找值在两个值之间的行
2.2.4.1 使用between…and…关键字
查询年龄在30到35岁之间女性用户信息:
select *from CustomerInfowhere Age between 30 and 35 and Gender = 'Female'
执行结果:

2.2.4.2 使用判断符
查询年龄在30到35岁之间女性用户信息:
select *from CustomerInfowhere Age >= 30 and Age <= 35 and Gender = 'Female'
执行结果:

2.2.5 在值列表中查找具有值的行
查询在湖北、湖南和北京地区的客户信息“
select *from CustomerInfowhere Province in ('湖北省','湖南省','北京市')
执行结果:

2.2.6 查找值包含字符串的行 - 模糊查询
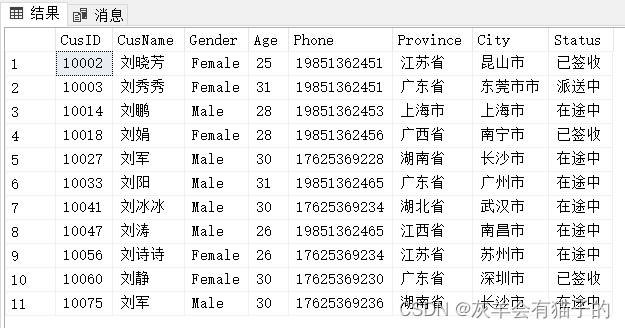
查找‘刘’姓客户的所有信息:
select *from CustomerInfowhere CusName like'刘%'
执行结果:
这篇关于SQL Sever 基础知识 - 数据筛选(1)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






