本文主要是介绍高并发热点缓存数据可能出现问题及解决方案,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
背景
电商场景促销活动的会场页由于经常集中在某个时间点进行“秒杀”促销,这些页面的QPS(服务器每秒可以处理的请求量)往往特别高,数据库通常无法直接支撑如此高QPS的请求,常见的解决方案是让大部分相同信息的请求都尽可能地压在缓存(cache)上来缓解数据库(DB)的压力,从而尽可能地去满足高并发访问的诉求(如图2-1所示)。
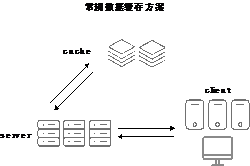
图2-1 常规数据缓存方案
在一次业务促销过程中,运营给一大批用户集中推送了一条消息:10点钟准时抢购一批远低于市场价而且数量有限的促销活动商品。由于确实物美价廉,用户收到消息之后10点钟准时进入手机客户端的会场页进行疯抢。几分钟内很多用户进入会场页,最终导致页面异常,服务器疯狂报警。报警信息显示很多关于缓存的异常,由于缓存拿不到数据转而会转向数据库去查询数据,这样数据库更加难以支撑,整个业务集群处于雪崩状态(如图2-2所示)。
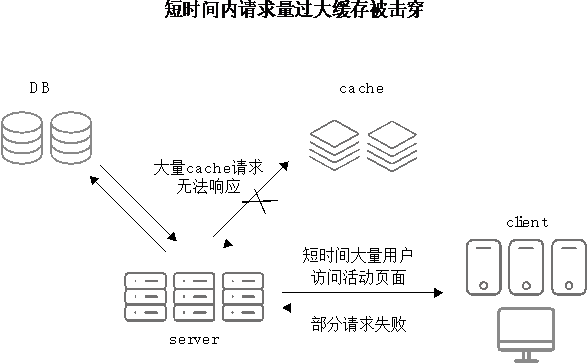
图2-2 短时间内请求量过大缓存被击穿
此时缓存到底发生了什么问题?关注哪些方面可以有效地预防缓存被击穿导致雪崩的发生呢?
缓存问题分析与解决过程
- 首先查看缓存详细日志,发现有很多带有“CacheOverflow”字样的日志,初步怀疑是触发了缓存限流。但是计算了缓存的整体能力和当前访问量情况:缓存的机器数×单机能够承受的QPS > 当前用户访问的最大QPS值,此时用户访问QPS并没有超过缓存之前的预算,怎么也会触发限流呢?
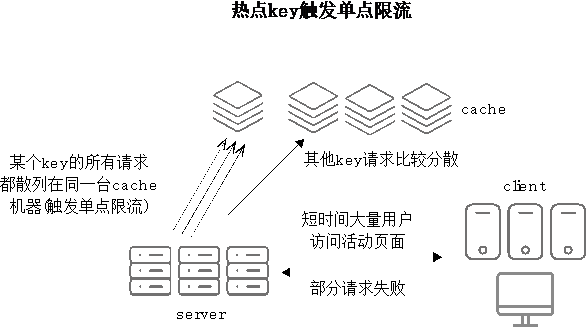
- 进一步分析日志,发现所有服务器上限流日志中缓存机器IP貌似都是同一台,说明大流量并没有按预想平均分散在不同的缓存机器上。回想前面提到的案例实际现象,发现确实有部分数据用户的访问请求都会触发对缓存中同一个key(热点key)进行访问,用户访问QPS有多大,则这个key的并发数就会有多大,而其他缓存机器完全没有分担任何请求压力,如图2-3所示。
- 然后紧急梳理出存在“热点请求”的key,并快速接入“热点本地缓存”方案,然后迅速在下一场秒杀活动中进一步进行验证,此时发现之前异常大幅度减少。不过还是有少量“CacheOverflow”字样异常日志。热点key的请求都被“本地缓存”拦截掉了,此时发现远程QPS限流异常已经基本没有了,这又是什么原因呢?
图2-3 热点key触发单点限流
仔细查看缓存单台机器的网络流量监控,发现偶尔有网络流量过大超过单台缓存机器的情况(如图2-4所示)。
图2-4 网络流量监控
说明缓存中有某些key对应的value数据过大,导致尽管QPS不是很高,但是网络流量(QPS×单个value的大小)还是过大,触发了缓存单台机器的网络流量限流。 - 紧急梳理出存在“大value”的key,发现这些“大value”部分是可以精简,部分是可以直接放入内存不用每次都远程获取的,经过一番梳理和优化之后,下次“秒杀”场景终于风平浪静了。至此问题初步得到解决。

预防“缓存被击穿”总结
- 评估缓存是否满足具体业务场景的请求流量,不是简单地对预估访问流量除以单台缓存的最大服务能力。
- 如果使用的缓存机制是按key的hash值散列到同一台机器,则必须梳理出当前业务场景中被高并发访问的那些key,看看这些key的并发访问量是否会超过单台机器的服务能力,如果超过则必须采取更多措施进行规避。
- 除了关注key的并发访问量外,还要关注key对应value的大小,如果key的并发访问量×value大小 > 单台缓存机器的网络流量限制,则也需要采取更多措施进行数据精简。
更多思考
- 单个key的请求量不超过单台缓存机器的服务能力,但是如果多个key正好散列到同一台机器,而且这几个key的流量之和超过单台机器的服务能力,我们该如何处理呢?
- 单个key的并发访问量×对应value大小 < 单台缓存机器的网络流量限制,但是如果多个key的并发访问量×各自对应value大小 >单台缓存机器的网络流量限制,又该如何处理呢?
针对上述两个问题,首先要做的是做好缓存中元素key的访问监控,一旦发现缓存有QPS限流或者网络大小限流时,能够迅速定位哪些key并发访问量过大,或者哪些key返回的value大小较大,再结合缓存的散列算法,通过一定规则动态修改key值来自动将这些可疑的key平均散列到各台缓存机器上去,这样就可以充分地利用所有缓存机器来分摊压力,保证缓存集群的最大可用能力,从而减少缓存被击穿的风险。
这篇关于高并发热点缓存数据可能出现问题及解决方案的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




