本文主要是介绍【LeetCode】692. 前K个高频单词,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
692. 前K个高频单词
- 描述
- 示例
- 解题思路及事项
- 思路一
- 思路二
描述
给定一个单词列表 words 和一个整数 k ,返回前 k 个出现次数最多的单词。
返回的答案应该按单词出现频率由高到低排序。如果不同的单词有相同出现频率, 按字典顺序 排序
示例
示例1
输入: words = [“i”, “love”, “leetcode”, “i”, “love”, “coding”], k = 2
输出: [“i”, “love”]
解析: “i” 和 “love” 为出现次数最多的两个单词,均为2次。
注意,按字母顺序 “i” 在 “love” 之前。
示例2
输入: [“the”, “day”, “is”, “sunny”, “the”, “the”, “the”, “sunny”, “is”, “is”], k = 4
输出: [“the”, “is”, “sunny”, “day”]
解析: “the”, “is”, “sunny” 和 “day” 是出现次数最多的四个单词,出现次数依次为 4, 3, 2 和 1 次。
解题思路及事项
思路一
遇到这样的题,我们一般思路肯定就是TOP-K问题,这样想当然没有问题,但是我们这里数据没那么多,用到这里属于杀鸡焉用牛刀,不过我们可以试一试,等下在讲别的思路。
不管是那个思路,首先这是一对一的关系,我们肯定要先用到map,,统计不同字符串出现的次数。
TOP-K在于建大堆和小堆的问题,这道题建议建大堆。我们现在已经学了,C++,因此可以使用priority_queue它默认就是建大堆,

然后把前K个元素拿出来就好了
class Solution {
public:vector<string> topKFrequent(vector<string>& words, int k) {map<string,int> mp;for(auto& str:words){mp[str]++;}vector<string> ret;//这里我们建一个大堆priority_queue<pair<string,int>>> py;auto it=mp.begin();while(it != mp.end()){py.push(*it);++it;}while(k--){ret.push_back(py.top().first);py.pop();}return ret;}
};
这是根据我们的思路写出来的代码

但是结果不对,难道我们思路出现了问题,这道题不应该这样解,
其实并不是,这样的思路是对的,但是问题就在于priority_queue第三个参数仿函数的比较出现了问题。
因为它比较的是pair对象。而pair的相关比较函数我们可以看看到底是怎么比的
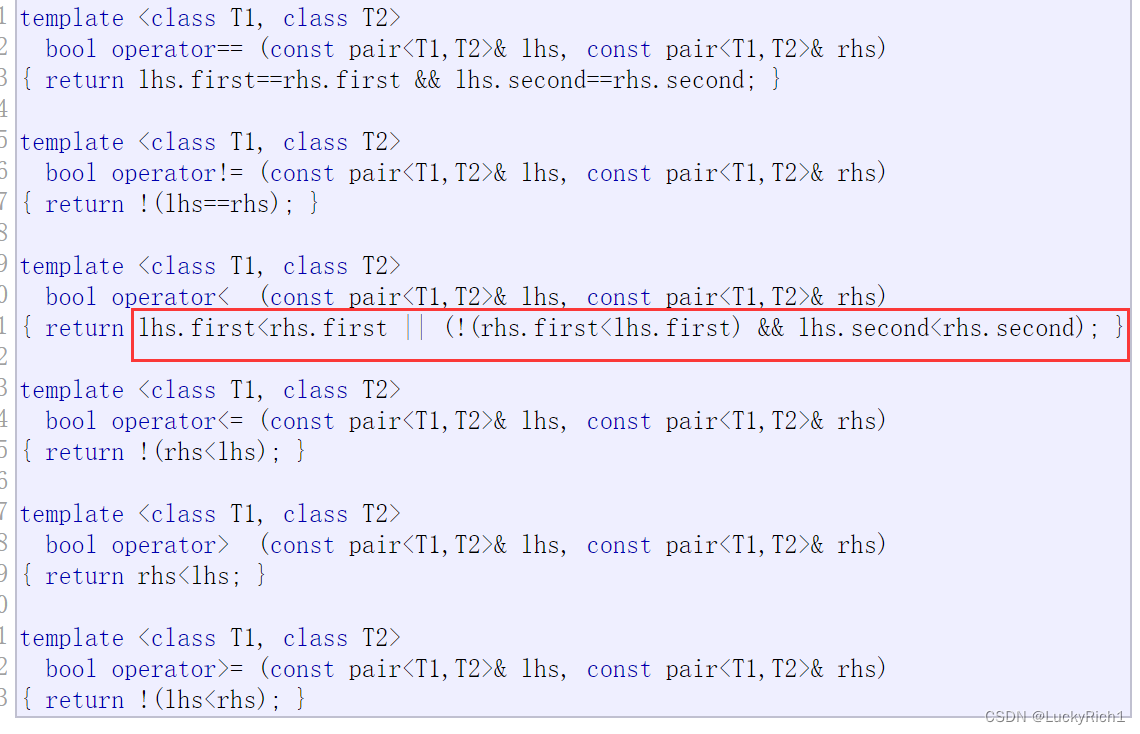
可以看到pair是先比较first,如果first相等在比较second。
但是我们的pair第一个参数是string,第二个参数是int。
这于我们想要优先比较int就不对,因此我们自己写一个仿函数。
class Solution {
public:template<class T>struct Less{bool operator()(const pair<string,int>& l,const pair<string,int>& r){return l.second < r.second;}};vector<string> topKFrequent(vector<string>& words, int k) {map<string,int> mp;for(auto& str:words){mp[str]++;}vector<string> ret;//这里我们建一个大堆priority_queue<pair<string,int>,vector<pair<string,int>>,Less<pair<string,int>>> py;auto it=mp.begin();while(it != mp.end()){py.push(*it);++it;}while(k--){ret.push_back(py.top().first);py.pop();}return ret;}
};
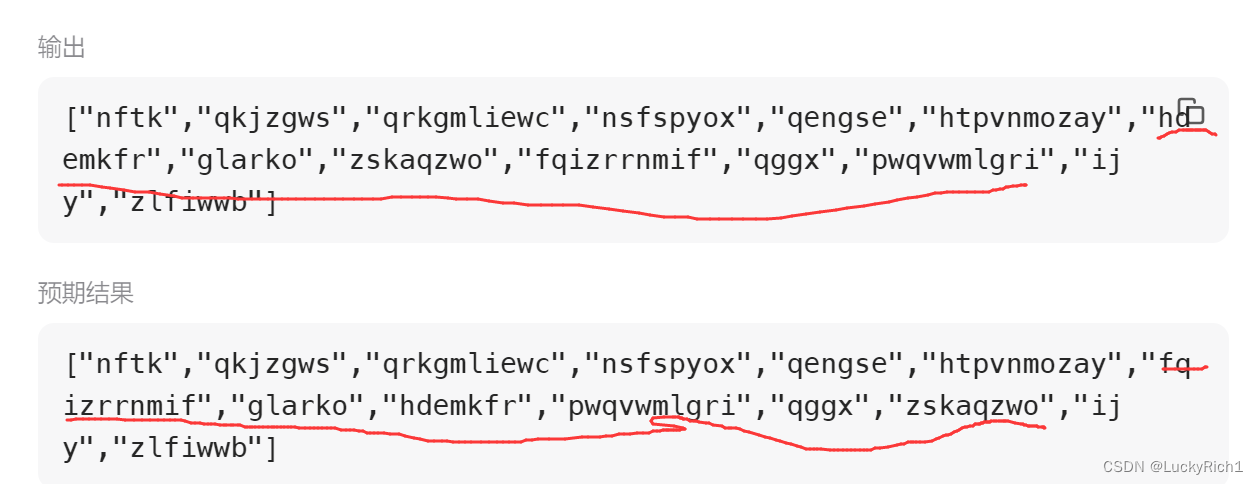
运行结果还是出现了问题。经过分析可能是建大堆出现了问题,我们打印一下看看是不是这个问题。

经过对比发现,它们出现次数都是6次,就是建立大堆谁在上面谁在下面出现了问题。
注意看到我们的题目要求,不同单词出现相同频率,按 字典顺序 排序

而我们在写自己的仿函数的时候,只考虑了出现次数不同的情况,而没有考虑这个情况。
class Solution {
public:template<class T>struct Less{bool operator()(const pair<string,int>& l,const pair<string,int>& r){//出现次数相同,就按 字典顺序 排序return l.second < r.second || (l.second == r.second && l.first > r.first);}};vector<string> topKFrequent(vector<string>& words, int k) {map<string,int> mp;for(auto& str:words){mp[str]++;}// for(auto& e: mp)// {// cout<<e.first<<":"<<e.second<<endl;// }vector<string> ret;//这里我们建一个大堆priority_queue<pair<string,int>,vector<pair<string,int>>,Less<pair<string,int>>> py;auto it=mp.begin();while(it != mp.end()){py.push(*it);++it;}while(k--){ret.push_back(py.top().first);py.pop();}return ret; }
};
思路二
刚才说过使用堆来对少的数据排序,杀鸡焉用牛刀了。现在想一想我用map建立一对一的关系之后,我给它排序一下不就好了吗,反正有算法库给我提供的sort函数。那来试一试
注意sort底层使用的快速排序,结构是线性结构,而map并不是线性结构而是树形结构,因此要把map里的数据放在vector,才能使用sort。
sort默认是升序,第一个版本是按照operator<比较的,第二个是按照comp比较的也就是说我们给它提供一个仿函数按照自己的想法比较。

由TOP-K我们就知道如果直接让pair对比会有问题,所以我们选第二种。
class Solution {
public:struct Compare{bool operator()(const pair<string,int>& l,const pair<string,int>& r){return l.second > r.second || (l.second == r.second && l.first < r.first);}};vector<string> topKFrequent(vector<string>& words, int k) {map<string,int> mp;for(auto& str:words){mp[str]++;}vector<string> ret;vector<pair<string,int>> v;for(auto& e:mp){v.push_back(e);}//这个Compare我们是按照降序进行判断的sort(v.begin(),v.end(),Compare());for(int i=0;i<k;++i){ret.push_back(v[i].first);}return ret;}
};
这样也能解决问题,不过这样的sort并不能保持稳定性,需要我自己手动控制才能保持稳定性以达到相同次数按 字典顺序 排序。
下面介绍一种稳定的排序算法。
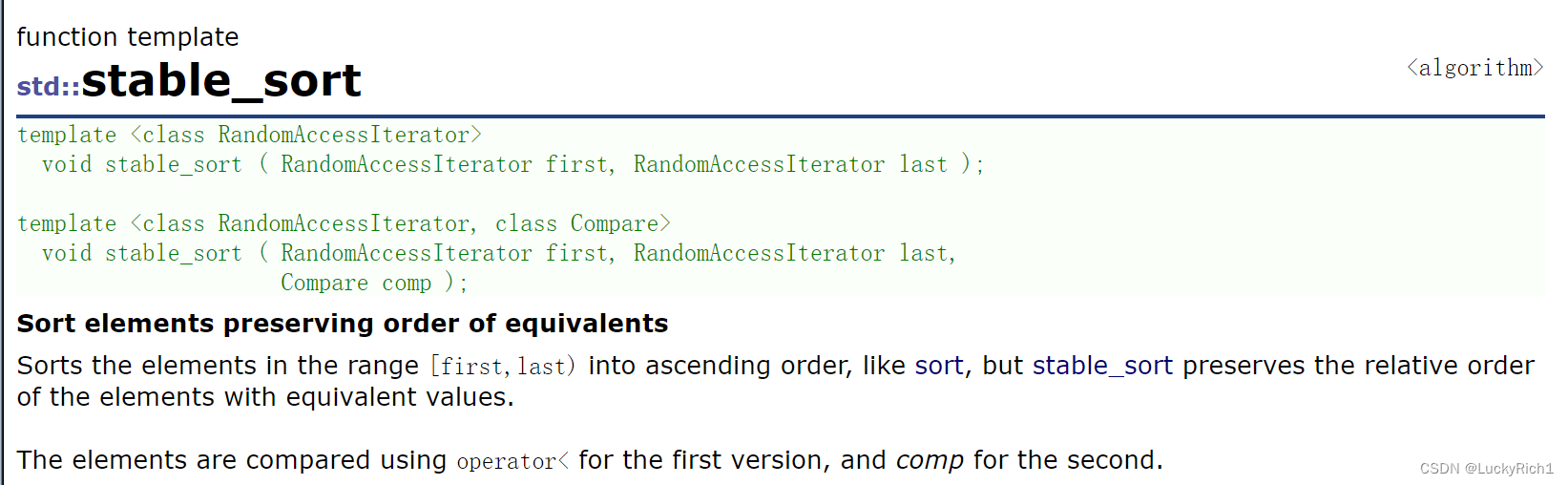
stable_sort,可以保持排序的稳定性。

i 在 love的前面,出现次数相同,i 依旧在 love前面。
class Solution {
public:struct Compare{bool operator()(const pair<string,int>& l,const pair<string,int>& r){return l.second > r.second ;}};vector<string> topKFrequent(vector<string>& words, int k) {map<string,int> mp;for(auto& str:words){mp[str]++;}vector<string> ret;vector<pair<string,int>> v;for(auto& e:mp){v.push_back(e);}//这个Compare我们是按照降序进行判断的//sort(v.begin(),v.end(),Compare());stable_sort(v.begin(),v.end(),Compare());for(int i=0;i<k;++i){ret.push_back(v[i].first);}return ret;}
};
这篇关于【LeetCode】692. 前K个高频单词的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







