本文主要是介绍OpenAI发布一周年,那些声称超过它的模型都怎么样了?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这篇报告详尽地回顾了自ChatGPT发布一年以来,各种声称与ChatGPT相当或更优的开源大语言模型在各种任务上的表现!
报告整合了各种评估基准,分析了开源LLMs与ChatGPT在不同任务上的比较。
包括一般能力、代理能力、逻辑推理能力、长文本建模能力、特定应用能力(如问答、总结)、以及可信赖性(如幻觉、安全性)。
结论先行:综合能力,ChatGPT,依然,遥遥领先!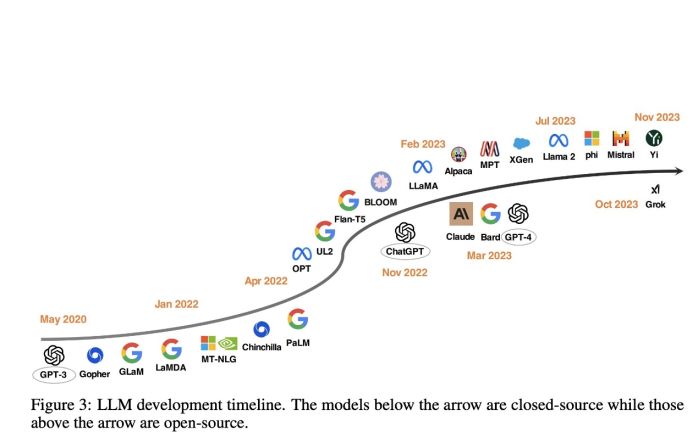
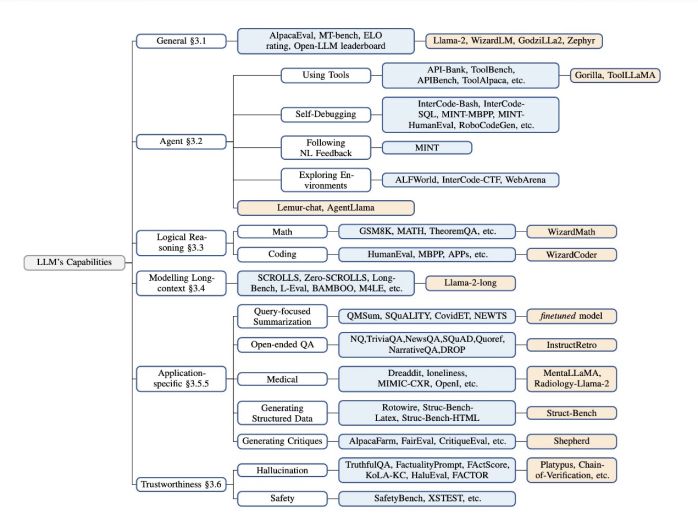 以下是报告简要总结:
以下是报告简要总结:
1、一般能力:
基准测试:
包括MT-Bench(多轮对话和指令遵循能力测试),AlpacaEval(测试模型遵循一般用户指令的能力),Open LLM Leaderboard(评估LLMs在多种推理和通用知识任务上的表现)。
模型性能:
•Llama-2-70B-chat 在 AlpacaEval 中达到了 92.66% 的胜率,超过了 GPT-3.5-turbo。
•WizardLM-70B 在 MT-Bench 上得分为 7.71,但低于 GPT-4(8.99)和 GPT-3.5-turbo(7.94)。
•Zephyr-7B 在 AlpacaEval 中的胜率为 90.60%,在 MT-Bench 上得分为 7.34。•GodziLLa2-70B 在 Open LLM Leaderboard 上的得分为 67.01%,而 Yi-34B 得分为 68.68%。•GPT-4 保持最高表现,胜率为 95.28%
2、代理能力:
基准测试:包括工具使用(API-Bank、ToolBench)、自我调试(InterCode-Bash、MINT-HumanEval),遵循自然语言反馈(MINT),和环境探索(ALFWorld、WebArena)。模型性能:Lemur-70B-chat 在 ALFWorld、IC-CTF 和 WebArena 环境测试中表现优于 GPT-3.5-turbo 和 GPT-4
3、逻辑推理能力:
基准测试:包括GSM8K(数学问题解决)、MATH(竞赛数学问题)、TheoremQA(应用定理解决科学问题)、HumanEval(编程问题)等。模型性能:•WizardCoder 在 HumanEval 上比 GPT-3.5-turbo 高出 19.1% 的绝对改进。•WizardMath 在 GSM8K 上比 GPT-3.5-turbo 有 42.9% 的绝对改进
4、应用特定能力:
基准测试:包括查询聚焦摘要(AQualMuse、QMSum等)和开放式问答(SQuAD、NewsQA等)。模型性能:InstructRetro在NQ、TriviaQA、SQuAD 2.0和DROP上比GPT-3有7-10%的改进。
5、医学领域应用:
基准测试:包括心理健康分析(IMHI)和放射学报告生成(OpenI、MIMIC-CXR)。模型性能:•MentalLlama-chat-13B 在 IMHI 训练集上微调后,其表现超过了 ChatGPT 在 9 个任务中的 9 个。•Radiology-Llama-2 在 MIMIC-CXR 和 OpenI 数据集上大幅超过了 ChatGPT 和 GPT-4
6、可信赖性:
基准测试:包括TruthfulQA、FactualityPrompts、HaluEval等,用于评估LLMs的真实性和安全性。模型性能:•不同的方法和模型(如 Platypus、Chain-of-Verification、Chain-of-Knowledge 等)在减少幻觉和提高安全性方面取得了进步 •例如Platypus在TruthfulQA上比GPT-3.5-turbo表现出约20%的改进。
在这份调查中,我们对在ChatGPT发布一周年之际在各个任务领域超越或迎头赶上ChatGPT的高性能开源LLM进行了系统性回顾。此外,我们提供了关于开源LLM的见解、分析和潜在问题。我们相信这份调查将为开源LLM领域提供有前途的方向,并激发进一步的研究和发展,有助于缩小它们与付费对手之间的差距。
这篇关于OpenAI发布一周年,那些声称超过它的模型都怎么样了?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









