本文主要是介绍茄子科技张韶全:跨多云大数据平台DataCake在OceanBase的实践,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

11 月 16 日,OceanBase 在北京顺利举办 2023 年度发布会,正式宣布:将持续践行“一体化”产品战略,为关键业务负载打造一体化数据库。其中,在“数字化转型升级实践专场”,我们有幸邀请到了茄子科技大数据技术总监张韶全进行《跨多云大数据平台 DataCake 在 OceanBase 的实践》主题演讲,以下为演讲全文:

大家下午好!非常荣幸受到 OceanBase 组委会的邀请,跟大家分享茄子科技大数据平台 DateCake 与 OceanBase 的合作实践。
首先介绍一下茄子科技。我们是第一批出海的互联网公司,公司的业务场景从最开始工具类 APP 扩展到内容、游戏、支付等多个场景,月活跃用户数量达到数亿级别,正是因为这种级别的用户体量,同时还有复杂的使用场景,我们很早便开启了大数据平台 DateCake 的自研,通过挖掘数据价值支撑业务高速发展。

因为我们是一家出海企业,所以很早就把大数据平台做到了彻底的云原生化。2018 年开始,大数据平台完全摆脱了传统的 Hadoop 架构,全部采用了云原生架构。我们在支撑内部业务的同时,发现在大数据方面的技术和积累,可以很好的帮助其他行业、不同场景更好地解决数字化转型过程中的问题和需求。所以,我们决定将大数据平台作为独立的产品商业化,去赋能外部企业,希望能够帮助外部企业拥有低门槛、低成本的大数据解决方案,能够落实数据方法论,帮助企业在竞争中获得一些优势。
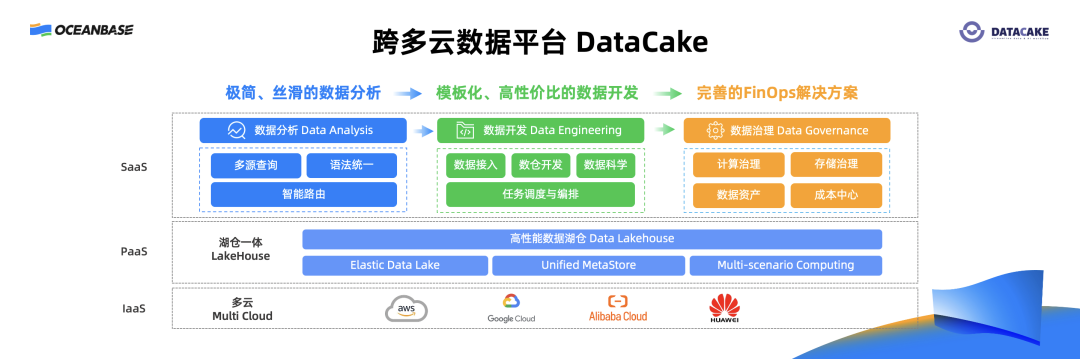
我们的大数据平台名字叫“DateCake”[1],从整体架构上分成三层,从底层 IaaS、中层 PaaS,到上层 SaaS。
Iaas 层,是完全的云原生架构,同时也支持多云。可以充分利用不同云的特点。比如,可以充分利用云上 Spot 实例,通过自研 PVC Reuse 技术[2],把 Spot 实例当成 On-demand 实例来使用,大幅降低使用成本;同时还可以充分利用底层云厂商提供的弹性存储和计算,保证业务只在使用时付费,进一步降低成本。
中层是 PaaS 层,采用湖仓一体架构,可以做到一份数据支撑不同的场景,例如数据分析、数据科学、数据开发,这样就可以避免数据从不同的系统导入导出的复杂流程,造成数据孤岛。另外,我们也自研了 Catalog 管理系统,通过该系统做到统一的数据资产视图,并能够做到细粒度数据管控、数据血缘和审计,现在该系统也对外开源[3]。
再到 SaaS 层,按照不同模块,从数据分析到数据开发,再到数据治理。第一,在数据分析里可以用统一的 SQL 完成不同的数据源的数据查询,不管数据是在湖里面、仓里面,还是在外部数据源的关键数据库里面,可以用一条 SQL 把全部数据查询出来。第二,通过非常低门槛的高性价比数据开发的模块化解决方案,不管用户是数据分析师还是数仓工程师,都可以用模块化非常简单地完成整个数据链路的构建。第三,还提供智能化、完善的 FinOPS 解决方案。

OceanBase 在 DateCake 中主要在两个场景中使用。第一个场景,利用OceanBase 的 OLAP 能力,把 OceanBase 作为一个轻型数仓来使用,围绕OceanBase构建完整的数据开发链路。第二个场景,利用 OceanBase 的 OLTP 能力,把 OceanBase 作为服务的数据库支持高并发查询,包括事务和一些复杂 SQL 查询。
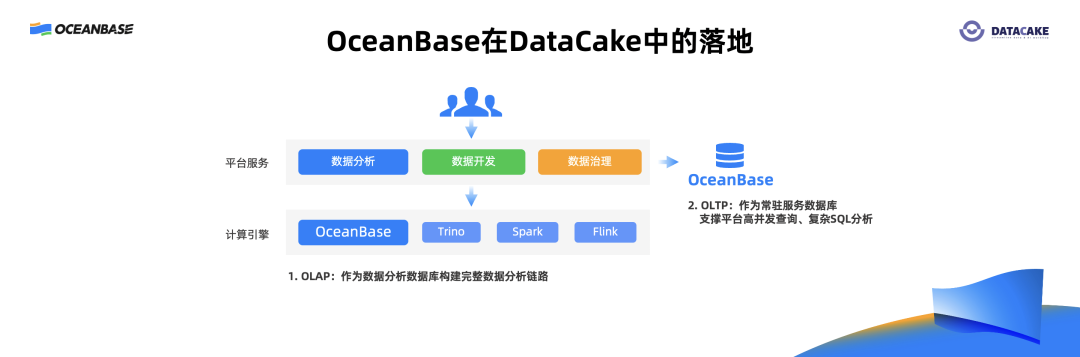

茄子科技为什么要选择 OceanBase?首先,最看中的一点是,OceanBase 经过了线上复杂系统的验证,我们非常相信经过复杂系统验证的数据库的能力;同时,OceanBase 支持多基础设施、高性价比、高兼容的特性,这些特性也非常契合我们 DateCake 本身的产品特点。

第一个特点,跨多云架构轻松运维。
因为我们是完全的云原生大数据平台,同时支持多云策略。为了能够支撑统一的服务和下面不同的云进行对接,我们研发了一套可以做到承上启下的作用且能够对底层环境透明化的系统。同时,该系统可以对查询做智能分析、智能路由,保证用户提交的查询都可以命中到准确的集群和高性价比的集群上。
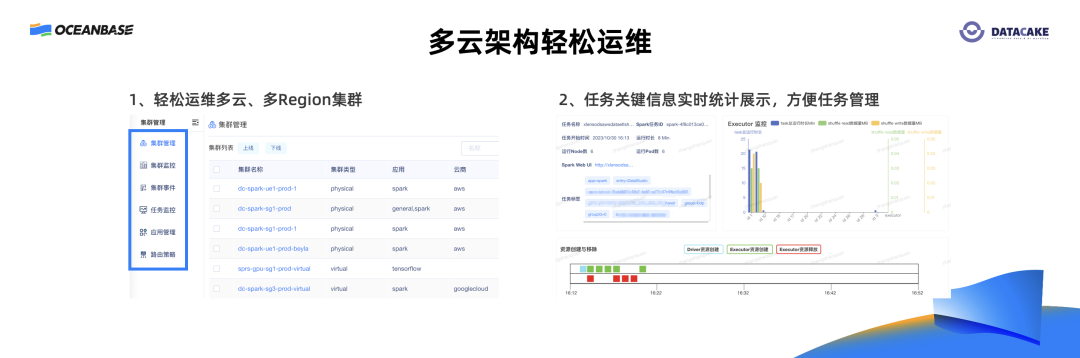
此外,为了让平台管理人员很好地运维多云系统、多云集群,我们也自研了一套多云集群的管理和监控系统,专门用来对多云的集群进行创建、管理、监控,同时对集群上的任务进行管理、对多云的任务做实时不同维度的分析。这样,就可以非常容易地帮助系统管理人员,轻松管理多云的集群、多云的环境。
第二个特点,一个平台覆盖 Data Workflow。
在一个平台上轻松构建从数据源到业务场景端到端的 Data Workflow,支持数据集成、数据导入、数据 ETL,同时提供了非常低门槛方式让用户通过模板化方式通过 SQL+低代码非常快速地构建一套完整的系统。比如,我们公司的一个数据分析师,就可以在平台上管理几百号的数据开发任务。

数据开发方案基于云的弹性资源,只需为使用付费,同时把云厂商的一些特点吃得很透,有非常强的技术积累,保证比传统的 Hadoop 解决方案低 70% 以上的成本。用户只需要通过简单配置就可以把数据链路中,比如数据集成、数据处理、数据导出场景中一些非常具体的案例,通过简单的配置就可以完成,不需要写非常复杂的代码。

OceanBase 在 Data Workflow 里主要有两个场景。第一个是 BI 场景,从数据集成入湖之后,经过湖上数据的处理,通常数据量比较大,处理完之后把数据导入到OceanBase,用 OceanBase 来支撑 BI 的可视化图表、仪表盘等。第二个是实时分析场景,相当于把 OceanBase 当成实时数仓,省去ETL的步骤,做实时的数据分析。
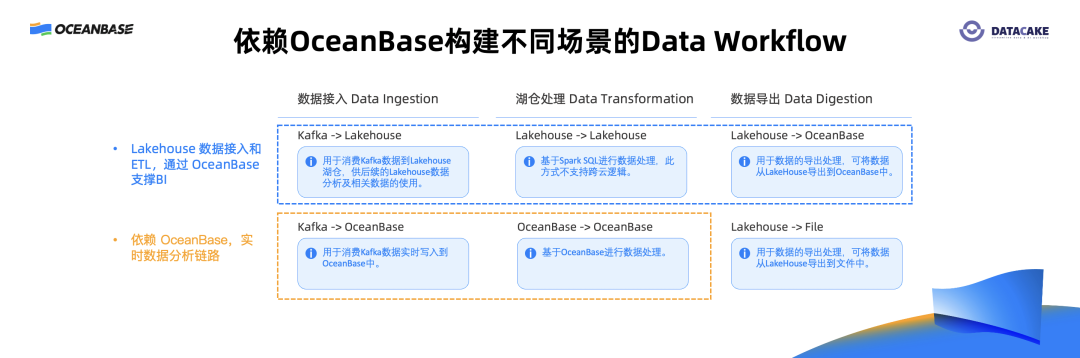
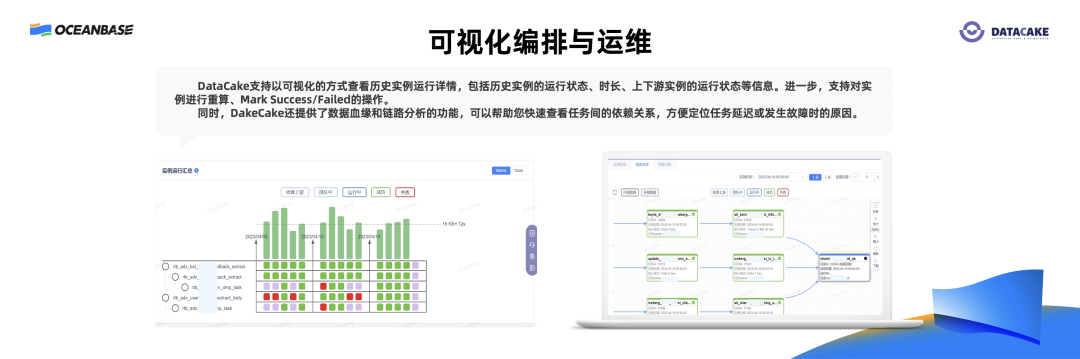
DateCake 可以通过可视化的方式查看历史实例运行详情,包括历史实例的运行状态、时长、上下游实例的运行状态等信息。进一步,支持对实例进行重算、Mark Success/Failed 的操作。同时,DakeCake 还提供数据血缘和链路分析的功能,可以快速查看任务间的依赖关系,方便定位任务延迟或发生故障时的原因。
第三个特点,实时成本分析。
现在都在讲数字化转型,其中数字化转型解决方案,最重要的一点就是能够让企业评估投入产出比,要知道投入的成本是什么样的,得到的回报是什么样的。
现在,我们的平台支持实时化任务级的成本分析,一个任务运行完之后立马可以知道这个任务的用量和成本是什么样的。相比云厂商“T-2”的成本费用计算方式,可以做到实时地任务级的成本分析。有了任务级的成本分析后,企业就可以做很多工作延伸,比如成本监控,一个任务的成本波动,如果有显著变化可以及时通知业务。
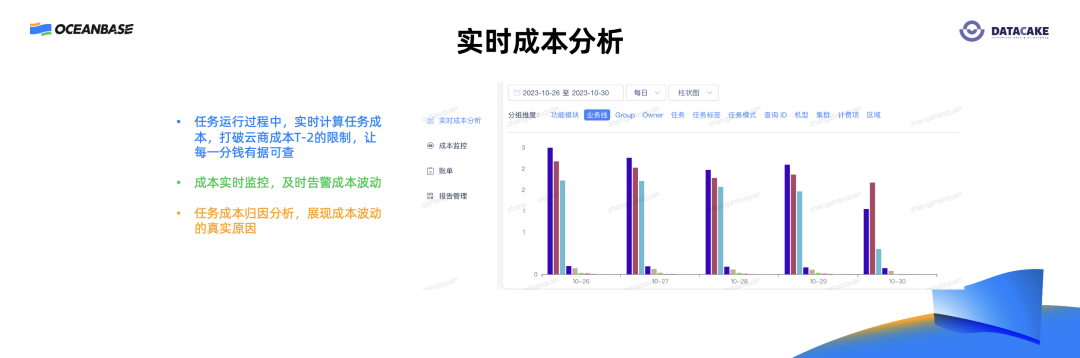
同时,我们的平台还提供了任务级成本的归因分析。任务成本有波动,可以分析出它是因为数据本身的波动、任务的变更,还是因为集群波动导致成本有波动。上图展示对实时成本从不同维度做多维分析,这是一个典型的海量数据的多维分析场景。
在数据多维分析场景,我们之前使用 RDS,愈发感觉力不从心,当我们迁移到 OceanBase 后,借助 OceanBase 的 OLAP 能力,在千万级数据分析上,OceanBase 的分析时间降低 60%-70%。
之后,我们也把实时成本数据分析后的数据库完全切到 OceanBase,整个迁移过程,因为 OceanBase 本身的高 MySQL 兼容性,以及只要稍微简单配置一下就可以完成,非常丝滑。

我今天分享的内容就到这里,希望跨多云大数据平台 DataCake 在 OceanBase 的实践分享能对大家有所帮助。未来 DataCake 会在云原生大数据方向上和大家一起继续奔跑,和伙伴们一起打赢数字化转型之役,谢谢大家!
[1] DataCake: https://www.datacake.cloud/
[2] Spot最佳实践:https://aws.amazon.com/cn/blogs/china/the-practice-of-shareit-big-data-platform-datacake-in-spark-on-eks/
[3] Polycat: https://github.com/DataCakeCloud/Polycat
这篇关于茄子科技张韶全:跨多云大数据平台DataCake在OceanBase的实践的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








