本文主要是介绍千里之行,始于足下。python 爬虫 requestes模块(3),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
简易网页搜集器(2)
前面我们学会了如何用 UA 伪装骗过服务器爬取我们想要的网页数据,不知道你们会不会和我一样在学会 UA 伪装的兴奋后突然想到另一个问题——就是我们爬取一个页面就要改一次 url 吗?
答案当然是否定的。
我们观察下面两个网址
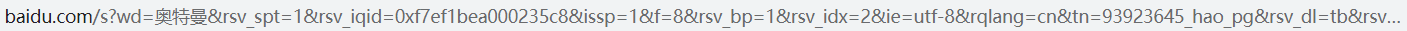

一个显然易见的区别是我圈起来的部分,即“wd = ”
那我就怀疑搜索不同的关键词,“wd” 都不同,那么是不是这么一回事呢?我们可以试试。
结果就像这样
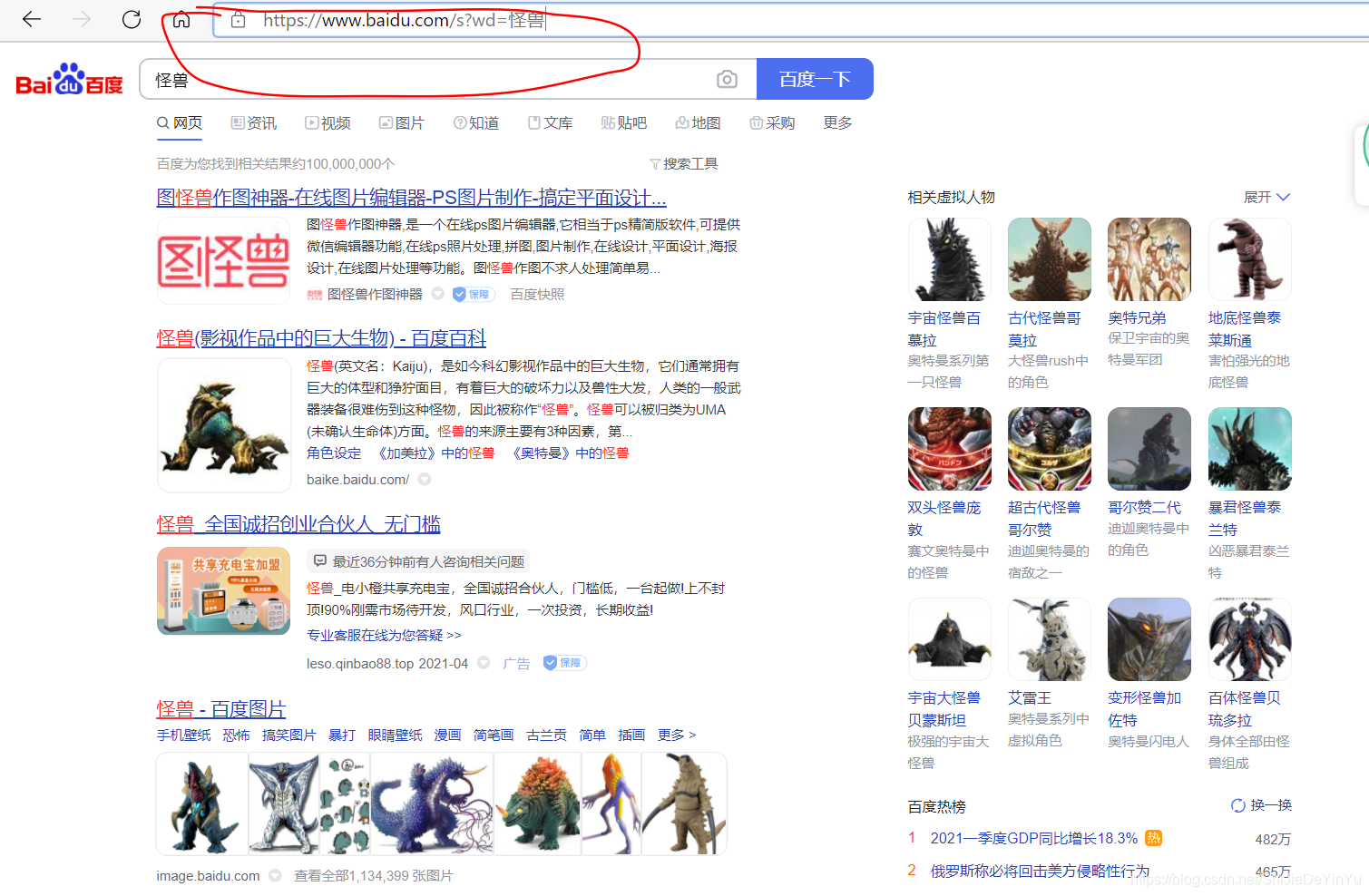
欧克,这就说明关键在于 “wd”的值,那么我们就可以根据这点写一个动态的URL
代码如下:
import requestsif __name__ == "__main__":# 要搜索的内容kd = input("百度一下,你就知道:")# 指定urlurl = "https://www.baidu.com/s?"param = {"wd": kd}# UA 伪装header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36"}# 发送请求page_text = requests.get(url = url, params = param, headers = header).text# 存储with open("."+kd+".html", "w", encoding = "utf-8") as fp:fp.write(page_text)print("爬取数据成功!!!")
当然,url 还可以写成这样的
url = "https://www.baidu.com/s?" + "wd=" + kd
我们打开保存的文件,看看结果

这说明我们的代码没有问题,我们可以不改变代码实现关键词搜索爬取网页了
这篇关于千里之行,始于足下。python 爬虫 requestes模块(3)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





