本文主要是介绍严蔚敏数据结构p17(2.19)——p18(2.24) (c语言代码实现),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
2.19已知线性表中的元素以值递增有序排列,并以单链表作存储结构。试写一高效的算法,
删除表中所有值大于 mink 且小于 maxk 的元素(若表中存在这样的元素)同时释放被删结点空间,
并分析你的算法的时间复杂度(注意:mink 和 maxk 是给定的个参变量,它们的值可以和表中的元素相同,也可以不同)。
本题代码如下
void deletemidst(linklist* L, int mink, int maxk)
{lnode* p = (*L)->next, * pre = *L; // 定义指针p和pre分别指向链表头结点的下一个结点和链表头结点lnode* q; // 定义指针q用于释放临时结点while (p) // 遍历链表{if (p->data > mink && p->data < maxk) // 如果当前结点的值在指定范围内{q = p; // 将当前结点赋值给临时结点qp = p->next; // 将指针p指向下一个结点pre->next = p; // 将指针pre的next指针指向下一个结点free(q); // 释放临时结点q所占用的内存空间}else // 如果当前结点的值不在指定范围内{p = p->next; // 将指针p指向下一个结点pre = pre->next; // 将指针pre指向下一个结点}}
}完整测试代码如下
#include<stdio.h>
#include<stdlib.h>
typedef struct lnode
{int data; // 数据域,存储整数值struct lnode* next; // 指针域,指向下一个节点
}lnode, * linklist; // 定义链表结构体和指针类型
int a[8] = { 1,2,3,4,5,6,7,8 }; // 初始化数组a
int n = 8; // 数组a的长度
// 构建链表函数
void buildlinklist(linklist* L)
{*L = (lnode*)malloc(sizeof(lnode)); // 分配内存空间给链表头结点(*L)->next = NULL; // 初始化链表头结点的next指针为NULLlnode* s, * r = *L; // 定义临时结点s和当前结点rint i = 0;for (i = 0; i < n; i++) // 遍历数组a{s = (lnode*)malloc(sizeof(lnode)); // 分配内存空间给临时结点ss->data = a[i]; // 将数组a中的元素赋值给临时结点s的data域s->next = r->next; // 将当前结点的next指针指向临时结点的next指针所指向的结点r->next = s; // 将当前结点的next指针指向临时结点sr = s; // 更新当前结点r为临时结点s}r->next = NULL; // 将最后一个结点的next指针设为NULL
}
// 删除指定范围内的值函数
void deletemidst(linklist* L, int mink, int maxk)
{lnode* p = (*L)->next, * pre = *L; // 定义指针p和pre分别指向链表头结点的下一个结点和链表头结点lnode* q; // 定义指针q用于释放临时结点while (p) // 遍历链表{if (p->data > mink && p->data < maxk) // 如果当前结点的值在指定范围内{q = p; // 将当前结点赋值给临时结点qp = p->next; // 将指针p指向下一个结点pre->next = p; // 将指针pre的next指针指向下一个结点free(q); // 释放临时结点q所占用的内存空间}else // 如果当前结点的值不在指定范围内{p = p->next; // 将指针p指向下一个结点pre = pre->next; // 将指针pre指向下一个结点}}
}
// 打印链表函数
void print(linklist* L)
{lnode* k = (*L)->next; // 定义指针k指向链表头结点的下一个结点while (k) // 遍历链表{printf("%d ", k->data); // 输出当前结点的值k = k->next; // 将指针k指向下一个结点}
}int main()
{linklist L; // 定义链表Lbuildlinklist(&L); // 调用构建链表函数printf("原始单链表为:"); // 输出提示信息print(&L); // 调用打印链表函数printf("删除mink与maxk中间的值后的单链表为:"); // 输出提示信息deletemidst(&L, 2, 6); // 调用删除指定范围内的值函数print(&L); // 调用打印链表函数return 0; // 返回0表示程序正常结束
}测试结果为

2.20 同 2.19 题条件,试写一高效的算法,删除表中所有值相同的多余元素(得操作后的线性表中所有元素的值均不相同),同时释放被删结点空间,并分析你的算法的时间复杂度。
本题代码如下
void deleterepeat(linklist* L)
{lnode* p = (*L)->next, * pre = *L;//p为工作指针,pre为它的前驱指针防止断链lnode* q;while (p->next!=NULL){if (p->next->data == pre->next->data)//如果p的后继的值域等与它本身则执行删除操作{q = p;p = p->next;pre->next = p;free(q);}else//否则继续向后遍历{p = p->next;pre = pre->next;}}
}void deleterepeat(linklist* L)
{lnode* p = (*L)->next, * pre = *L;//p为工作指针,pre为它的前驱指针防止断链lnode* q;while (p->next!=NULL){if (p->next->data == pre->next->data)//如果p的后继的值域等与它本身则执行删除操作{q = p;p = p->next;pre->next = p;free(q);}else//否则继续向后遍历{p = p->next;pre = pre->next;}}
}完整测试代码
#include<stdio.h>
#include<stdlib.h>
typedef struct lnode
{int data;struct lnode* next;
}lnode,*linklist;
int a[8] = { 1,2,2,3,3,4,5,6 };
int n = 8;
void buildlinklist(linklist* L)
{*L = (lnode*)malloc(sizeof(lnode));(*L)->next = NULL;int i = 0;lnode* s, * r = *L;for (i = 0; i < n; i++){s = (lnode*)malloc(sizeof(lnode));s->data = a[i];s->next = r->next;r->next = s;r = s;}r->next = NULL;
}
void deleterepeat(linklist* L)
{lnode* p = (*L)->next, * pre = *L;//p为工作指针,pre为它的前驱指针防止断链lnode* q;while (p->next!=NULL){if (p->next->data == pre->next->data)//如果p的后继的值域等与它本身则执行删除操作{q = p;p = p->next;pre->next = p;free(q);}else//否则继续向后遍历{p = p->next;pre = pre->next;}}
}
void print(linklist* L)
{lnode* k = (*L)->next;while (k){printf("%d ", k->data);k = k->next;}
}
int main()
{linklist L;buildlinklist(&L);printf("原始单链表为:"); print(&L); // 调用打印链表函数printf("\n删除重复值后的单链表为:");deleterepeat(&L); // 调用删除重复值的函数print(&L); // 调用打印链表函数return 0; // 返回0表示程序正常结束
}测试结果为

2.21 试写一算法,实现顺序表的就地逆置,即利用原表的存储空间将线性表(a1,a2,...,an)逆置为(an,...,a2,a1)。可以看下面这个(说的不好请见谅)👇
c语言代码实现数据结构课后代码题顺序表p18 2_哔哩哔哩_bilibili
本题代码如下
void nizhi(struct sqlist *s)
{int i = 0; // 定义一个整型变量i,用于遍历顺序表int j = s->length; // 定义一个整型变量j,用于存储顺序表的长度int temp = 0; // 定义一个整型变量temp,用于临时存储元素for (i = 0; i < s->length / 2; i++) // 遍历顺序表的前半部分{temp = s->a[i]; // 将当前元素存储到temp中s->a[i] = s->a[s->length - 1 - i]; // 将后半部分的元素赋值给前半部分s->a[s->length - 1 - i] = temp; // 将temp中的元素赋值给后半部分}
}完整测试代码如下
#include<stdio.h>
#define Max 10
struct sqlist
{int a[Max];int length;
};
void nizhi(struct sqlist *s)
{int i = 0; // 定义一个整型变量i,用于遍历顺序表int j = s->length; // 定义一个整型变量j,用于存储顺序表的长度int temp = 0; // 定义一个整型变量temp,用于临时存储元素for (i = 0; i < s->length / 2; i++) // 遍历顺序表的前半部分{temp = s->a[i]; // 将当前元素存储到temp中s->a[i] = s->a[s->length - 1 - i]; // 将后半部分的元素赋值给前半部分s->a[s->length - 1 - i] = temp; // 将temp中的元素赋值给后半部分}
}
int main()
{struct sqlist s; // 定义两个顺序表变量sint i = 0; // 定义一个整型变量,用于遍历顺序表ss.length = 5; // 设置顺序表s的长度为5for (i = 0; i < s.length; i++) // 遍历交集结果scanf("%d", &s.a[i]);printf("原顺序表为:");for (i = 0; i < s.length; i++) // 遍历交集结果printf("%d ", s.a[i]); // 输出交集结果中的每个元素nizhi(&s);printf("\n逆置后的顺序表为:");for (i = 0; i < s.length; i++) // 遍历交集结果printf("%d ", s.a[i]); // 输出交集结果中的每个元素return 0; // 程序正常结束,返回0
}
测试结果为

2.22试写一算法,对单链表实现就地逆置(可以看下面的视频讲解)👇
c语言代码实现数据结构课后代码题顺序表p18 2_哔哩哔哩_bilibili
本题代码如下
void nizhi(linklist* L)//单链表就地逆置
{lnode* p = (*L)->next;lnode* r = p;(*L)->next = NULL;while (p != NULL){p = p->next;r->next = (*L)->next;(*L)->next = r;r = p;}
}完整测试代码如下
#include<stdio.h>
#define Max 50
struct sqlist
{int a[Max];int length;
};
void nizhi(struct sqlist* s)
{int temp = 0;for (int i = 0; i < s->length / 2; i++){temp = s->a[i];s->a[i] = s->a[s->length - i - 1];s->a[s->length - 1 - i] = temp;}
}
int main()
{struct sqlist s;int j = 0;s.length = 5;for (j = 0; j < s.length; j++)scanf("%d", &s.a[j]);printf("原先数组为:");for (j = 0; j < s.length; j++)printf("%d", s.a[j]);nizhi(&s);printf("\n逆置后的数组为:");for (j = 0; j < s.length; j++)printf("%d", s.a[j]);return 0;
}测试结果为

2.23
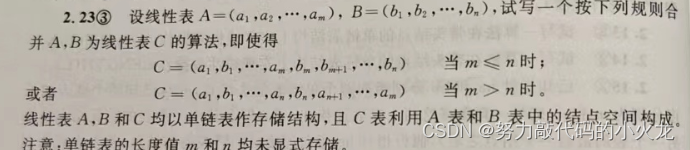
本题代码如下
linklist Union(linklist* A, linklist* B)
{lnode *C = (lnode*)malloc(sizeof(lnode));C->next = NULL;lnode* ra = (*A)->next, * rb = (*B)->next;lnode* rc = C;while (ra && rb){if (ra->data<rb->data)//若A中当前结点小于B中当前结点值{rc->next = ra;rc = ra;ra = ra->next;}else if (ra->data>rb->data)//若A中当前结点大于B中当前结点值{rc->next = rb;rc = rb;rb = rb->next;}else{rc->next = ra;rc = ra;ra = ra->next;rb= rb->next;}}while (ra)//B遍历完,A没有遍历完{rc->next= ra;rc = ra;ra = ra->next;}while (rb)//A遍历完,B没有遍历完{rc->next = rb;rc = rb;rb= rb->next;}rc->next = NULL; //结果表的表尾结点置空return C;
}完整测试代码如下
#include<stdio.h>
#include<stdlib.h>
typedef struct lnode
{int data;struct lnode* next;
}lnode, * linklist;
int na = 5;
int nb = 3;
int a[5] = { 1,3,5,7,9};
int b[3] = { 2,4,6 };
void buildlinklist(linklist* L, int arr[], int n)//创建链表
{*L = (lnode*)malloc(sizeof(lnode));(*L)->next = NULL;lnode* s = *L, * r = *L;int i = 0;for (i = 0; i < n; i++){s = (lnode*)malloc(sizeof(lnode));s->data = arr[i];s->next = r->next;r->next = s;r = s;}r->next = NULL;
}
linklist Union(linklist* A, linklist* B)
{lnode *C = (lnode*)malloc(sizeof(lnode));C->next = NULL;lnode* ra = (*A)->next, * rb = (*B)->next;lnode* rc = C;while (ra && rb){if (ra->data<rb->data)//若A中当前结点小于B中当前结点值{rc->next = ra;rc = ra;ra = ra->next;}else if (ra->data>rb->data)//若A中当前结点大于B中当前结点值{rc->next = rb;rc = rb;rb = rb->next;}else{rc->next = ra;rc = ra;ra = ra->next;rb= rb->next;}}while (ra)//B遍历完,A没有遍历完{rc->next= ra;rc = ra;ra = ra->next;}while (rb)//A遍历完,B没有遍历完{rc->next = rb;rc = rb;rb= rb->next;}rc->next = NULL; //结果表的表尾结点置空return C;
}
void print(linklist* L)//输出单链表
{lnode* k = (*L)->next;while (k){printf("%d ", k->data);k = k->next;}
}
int main()
{linklist A, B;buildlinklist(&A, a, na);buildlinklist(&B, b, nb);printf("A链表为:");print(&A);printf("\nB链表为:");print(&B);linklist C = Union(&A, &B);printf("\n合并后的链表为:");print(&C);return 0;
}测试结果如下


2.24假设有两个按元素值递增有序排列的线性表A和B均以单链表作存储结构,请编写算法将A表和B表归并成一个按元素值递减有序(即非递增有序,允许表中含有值相同的元素)排列的线性表 C,并要求利用原表(即A表和B 表)的结点空间构造C表。
本题代码如下
linklist Union(linklist* A, linklist* B)
{lnode* C = (lnode*)malloc(sizeof(lnode));C->next = NULL;lnode* ra = (*A)->next, * rb = (*B)->next;lnode* rapre = *A, * rbpre = *B;//rapre为ra的前驱指针,rbpre为rb的前去指针 lnode* rc = C;while (ra && rb){if (ra->data < rb->data)//若A中当前结点小于B中当前结点值{rapre = ra->next;ra->next=rc->next ;rc->next= ra;ra =rapre;}else if (ra->data > rb->data)//若A中当前结点大于B中当前结点值{rbpre = rb->next;rb->next = rc->next;rc->next = rb;rb = rbpre;}else{rapre = ra->next;ra->next = rc->next;rc->next = ra;ra = rapre;rb = rb->next;}}while (ra)//B遍历完,A没有遍历完{rapre = ra->next;ra->next = rc->next;rc->next = ra;ra = rapre;}while (rb)//A遍历完,B没有遍历完{rbpre = rb->next;rb->next = rc->next;rc->next = rb;rb = rbpre;}return C;
}完整测试代码如下
#include<stdio.h>
#include<stdlib.h>
typedef struct lnode
{int data;struct lnode* next;
}lnode, * linklist;
int na = 5;
int nb = 8;
int a[5] = { 1,3,5,7,9 };
int b[8] = { 2,4,6,8,10,12,14,16 };
void buildlinklist(linklist* L, int arr[], int n)//创建链表
{*L = (lnode*)malloc(sizeof(lnode));(*L)->next = NULL;lnode* s = *L, * r = *L;int i = 0;for (i = 0; i < n; i++){s = (lnode*)malloc(sizeof(lnode));s->data = arr[i];s->next = r->next;r->next = s;r = s;}r->next = NULL;
}
linklist Union(linklist* A, linklist* B)
{lnode* C = (lnode*)malloc(sizeof(lnode));C->next = NULL;lnode* ra = (*A)->next, * rb = (*B)->next;lnode* rapre = *A, * rbpre = *B;//rapre为ra的前驱指针,rbpre为rb的前去指针 lnode* rc = C;while (ra && rb){if (ra->data < rb->data)//若A中当前结点小于B中当前结点值{rapre = ra->next;ra->next=rc->next ;rc->next= ra;ra =rapre;}else if (ra->data > rb->data)//若A中当前结点大于B中当前结点值{rbpre = rb->next;rb->next = rc->next;rc->next = rb;rb = rbpre;}else{rapre = ra->next;ra->next = rc->next;rc->next = ra;ra = rapre;rb = rb->next;}}while (ra)//B遍历完,A没有遍历完{rapre = ra->next;ra->next = rc->next;rc->next = ra;ra = rapre;}while (rb)//A遍历完,B没有遍历完{rbpre = rb->next;rb->next = rc->next;rc->next = rb;rb = rbpre;}return C;
}
void print(linklist* L)//输出单链表
{lnode* k = (*L)->next;while (k){printf("%d ", k->data);k = k->next;}
}
int main()
{linklist A, B;buildlinklist(&A, a, na);buildlinklist(&B, b, nb);printf("A链表为:");print(&A);printf("\nB链表为:");print(&B);linklist C = Union(&A, &B);printf("\n合并后的链表为:");print(&C);return 0;
}测试结果如下

这篇关于严蔚敏数据结构p17(2.19)——p18(2.24) (c语言代码实现)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





