本文主要是介绍week07_day02_Queue,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
栈,底层实现一般是单链表
队列,底层实现一般是数组
队列的API:
入队 (enqueue):在队尾添加元素,O(1)
出队 (dequeue):从队头删除元素,O(1)
判空 (isEmpty):判断队列是否为空,方便遍历,O(1)
长度(size)
查看队头元素(peek)
队列的顺序映象(顺序队):

package com.cskaoyan.queue;import com.cskaoyan.exception.ArrayOverFlowException;
import com.cskaoyan.exception.EmptyQueueException;import java.util.Arrays;/*** @author shihao* @create 2020-05-19 11:32* <p>* 队列的API:* Void enqueue(E e)* E dequeue()* E peek()* boolean isEmpty()* int size()*/
public class MyQueue<E> {private static final int DEFAULT_CAPACITY = 10;private static final int MAX_CAPACITY = Integer.MAX_VALUE - 8;//属性private Object[] elements;private int front;private int rear;private int size;//构造方法//front、rear、size初始值为0,不需要在构造方法中初始化public MyQueue() {elements = new Object[DEFAULT_CAPACITY];}public MyQueue(int initialCapacity) {if (initialCapacity <= 0 || initialCapacity > MAX_CAPACITY) {throw new IllegalArgumentException("initialCapacity = " + initialCapacity);}elements = new Object[initialCapacity];}//方法/*** 将元素e入队** @param e 入队的元素*/public void enqueue(E e) {if (elements.length == size) {//扩容int newLength = calculateCapacity();grow(newLength);}//添加元素elements[rear] = e;rear = (rear + 1) % elements.length;size++;}private void grow(int newLength) {Object[] newArr = new Object[newLength];for (int i = 0; i < size; i++) {int index = (front + i) % elements.length;newArr[i] = elements[index];}elements = newArr;front = 0;rear = size;}private int calculateCapacity() {if (size == MAX_CAPACITY) {throw new ArrayOverFlowException();}int newLength = elements.length + elements.length >> 1;if (newLength < 0 || newLength > MAX_CAPACITY) {newLength = MAX_CAPACITY;}return newLength;}/*** 出队** @return 队头元素*/@SuppressWarnings("unchecked")public E dequeue() {if (size == 0) {throw new EmptyQueueException();}E retValue = (E) elements[front];elements[front] = null;front = (front + 1) % elements.length;size--;return retValue;}/*** 获取队头元素** @return 返回队头元素*/@SuppressWarnings("unchecked")public E peek() {if (size == 0) {throw new EmptyQueueException();}return (E) elements[front];}/*** 判空** @return 空的话返回true,否则返回false*/public boolean isEmpty() {return size == 0;}/*** 返回队列大小** @return 返回队列大小*/public int size() {return size;}/*** 情况队列中所有元素*/public void clear() {int index = front;for (int i = 0; i < size; i++) {elements[index] = null;index = (index + 1) % elements.length;}front = 0;rear = 0;size = 0;}@Overridepublic String toString() {StringBuilder sb = new StringBuilder("[");int i = front;while (i != rear) {sb.append(elements[i]).append(", ");i = (i + 1) % elements.length;}if (!this.isEmpty()) {sb.delete(sb.length() - 2, sb.length());}return sb.append("]").toString();}public static void main(String[] args) {MyQueue<Character> queue = new MyQueue<>();// System.out.println(queue);queue.enqueue('A');queue.enqueue('B');queue.enqueue('C');// System.out.println(queue);//E dequeue()
// System.out.println(queue.dequeue());
// System.out.println(queue.dequeue());
// System.out.println(queue.dequeue());
// //System.out.println(queue.dequeue());
// System.out.println(queue);// E peek()/*System.out.println(queue.peek());System.out.println(queue);*/// System.out.println(queue);
// System.out.println(queue.size());
// System.out.println(queue.isEmpty());
// queue.clear();
// System.out.println(queue);
// System.out.println(queue.size());
// System.out.println(queue.isEmpty());}
}实现一个链队(队列的非顺序映象):
···································································································································································································
普通队列的应用场景是很有限的,一般在工程中用到的是阻塞队列。
阻塞队列:常用于生产者-消费者模型中。
当队列满的时候,入队列就阻塞。
当队列空的时候,出队列就阻塞。
jdk给我们提供了阻塞队列:
BlockingQueue:阻塞队列
|-- ArrayBlockingQueue (建议使用)
|-- LinkedBlockingQueue
API:
void put(E e): 阻塞方法
E take(): 阻塞方法
阻塞队列:常用于生产者-消费者模型中。
应用场景:
缓存
利用队列实现 BFS
Task: 自己实现一个阻塞队列
package com.cskaoyan.queue;/*** @author shihao* @create 2020-05-19 15:03***/
public class MyBlockingQueue<E> {private static final int MAX_CAPACITY = Integer.MAX_VALUE - 8;//属性private Object[] elements;private int front;private int rear;private int size;//构造方法public MyBlockingQueue(int initialCapacity) {if (initialCapacity < 0 || initialCapacity > MAX_CAPACITY) {throw new IllegalArgumentException("initialCapacity = " + initialCapacity);}elements = new Object[initialCapacity];}//方法/*** 入队** @param e 入队元素*/public synchronized void enqueue(E e) {//如果队列满了,就阻塞//下面这行代码必须用while不能用if//你正在wait,一会别人把你notify,notify你后你还得抢this这把锁,要是抢不到//别人再往队列里添加元素,队满。等下别人把锁释放了,你获取到这把锁,你能添加数据吗//不能while (size == elements.length) {try {this.wait();} catch (InterruptedException e1) {e1.printStackTrace();}}//接下来队列一定不满,就可以添加数据了elements[rear] = e;rear = (rear + 1) % elements.length;size++;//唤醒其他线程this.notifyAll();}/*** 出队** @return*/@SuppressWarnings("unchecked")public synchronized E dequeue() {//队列为空就阻塞while (size == 0) {try {this.wait();} catch (InterruptedException e) {e.printStackTrace();}}//队列一定不为空,可以出队E retValue = (E) elements[front];elements[front] = null;front = (front + 1) % elements.length;size--;//唤醒其他线程this.notifyAll();return retValue;}/*** 取队头元素** @return 队头元素*/@SuppressWarnings("unchecked")public synchronized E peek() {//队列为空就阻塞while (size == 0) {try {this.wait();} catch (InterruptedException e) {e.printStackTrace();}}return (E) elements[front];}/*** 获取队列大小** @return*///必须得加synchronized,否则就不是原子操作,//假如你调用size()方法,其他线程添加或删除元素,size发生变化,//你所获取到的size就不是当前的size了。public synchronized int size() {return size;}//不加synchronized,你现在获取到的是不空,你想要获取元素,//别的线程也获取到的是不空,它就给删除了,现在是空的,//然后你获取到锁,你一看,你刚刚得到的结果是不空,你就获取元素,发生错误public synchronized boolean isEmpty() {return size == 0;}
}···········································································································································································
写一个线程池,线程池就是生产者消费者的典型应用
Executor是一个接口,Executors是一个工具类
Collection是一个接口,Collections是一个工具类
一般后缀为s的都是工具类
线程池:
以前我们是怎样创建线程池的?
Executors中的静态方法
注意事项:工作中最好不要使用Executors中的静态方法去创建线程池
原因: Executors中的静态方法创建的线程池,阻塞队列是LinkedBlockingQueue,并且没有限制容量。
在高并发的场景中,很容易导致OOM现象。
那我们该怎么去创建线程池呢?
线程池类ThreadPoolExecutor在包java.util.concurrent下
ThreadPoolExecutor threadPool= new ThreadPoolExecutor(10, 15, 60, TimeUnit.SECONDS, new LinkedBlockingQueue());
第一个参数10 表示这个线程池初始化了10个线程在里面工作
第二个参数15 表示如果10个线程不够用了,就会自动增加到最多15个线程
第三个参数60 结合第四个参数TimeUnit.SECONDS,表示经过60秒,多出来的线程还没有接到活儿,就会回收,最后保持池子里就10个
第四个参数TimeUnit.SECONDS 如上
第五个参数 new LinkedBlockingQueue() 用来放任务的集合
先设计一个Task类,表示需要执行的任务:
package com.cskaoyan.queue;/*** @author shihao* @create 2020-05-19 17:11*/
public class Task implements Runnable {private int number;public Task(int number) {this.number = number;}@Overridepublic void run() {System.out.println("线程" + Thread.currentThread().getName() + "开始执行任务" + number);try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}System.out.println("线程" + Thread.currentThread().getName() + "执行完毕任务" + number);}
}创建线程池类:
package com.cskaoyan.queue;import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.Executor;/*** @author shihao* @create 2020-05-19 16:07* <p>* 线程池(Executor)就是一个典型的生产者消费者模型* 生产者:提交任务的线程* 消费者:线程池中的线程* 产品:任务* <p>* 我们只需要实现消费者和产品这块的代码就好了,生产者是外部的*/
public class MyThreadPool implements Executor {private static final int DEFAULT_THREAD_SIZE = 3;private static final int MAX_THREAD_SIZE = 100;private static final int DEFAULT_CAPACITY = 10;private static final int MAX_CAPACITY = 10000;//属性//Runnable就表示一个任务//阻塞队列应当是有界的,防止报OOM异常,高并发环境下设置有界队列。//无界的话就能一直往阻塞队列中加入元素,服务器处理不过来,内存会爆掉。private BlockingQueue<Runnable> tasks;//线程池中养的线程个数private int threadSize;//构造方法public MyThreadPool() {//调用第二个构造方法this(DEFAULT_THREAD_SIZE, DEFAULT_CAPACITY);}public MyThreadPool(int threadSize, int capacity) {if (threadSize <= 0 || threadSize > MAX_THREAD_SIZE) {throw new IllegalArgumentException("threadSize = " + threadSize+ ", MAX_THREAD_SIZE" + MAX_THREAD_SIZE);}if (capacity <= 0 || capacity > MAX_CAPACITY) {throw new IllegalArgumentException("capacity = " + capacity+ ", MAX_CAPACITY" + MAX_CAPACITY);}this.threadSize = threadSize;//创建阻塞队列tasks = new ArrayBlockingQueue<>(capacity);//在线程池中创建线程// 1.线程从tasks中拿任务// 2.不想让其中的线程执行完run方法就死亡了for (int i = 0; i < this.threadSize; i++) {new workThread().start();}}//一个线程执行完run方法后就会死亡,我们不想让它死亡,// 而是想让它一直从tasks中取任务执行。private class workThread extends Thread {@Overridepublic void run() {while (true) {//从阻塞队列中取任务Runnable task = null;try {task = tasks.take();} catch (InterruptedException e) {e.printStackTrace();}//执行任务task.run();}}}//方法/*** 将任务command提交给阻塞队列tasks** @param command 待提交的任务*/@Overridepublic void execute(Runnable command) {//提交任务try {tasks.put(command);} catch (InterruptedException e) {e.printStackTrace();}}public static void main(String[] args) {MyThreadPool pool = new MyThreadPool();for (int i = 0; i < 20; i++) {pool.execute(new Task(i));}}
}···········································································································································································
树:
与线性表表示的一一对应的线性关系不同,树表示的是数据元素之间更为复杂的非线性关系。
直观来看,树是以分支关系定义的层次结构。树在客观世界中广泛存在,如人类社会的族谱和各种社会组织机构都可以用树的形象来表示。
简单来说,树表示的是1对多的关系。
定义:
树(Tree)是n( n>=0 )个结点的有限集合,没有结点的树称为空树,在任意一颗非空树中:
有且仅有一个特定的称为根(root)的结点
当n>1的时,其余结点可分为 m( m>0 ) 个互不相交的有限集T1,T2,…, Tm,其中每一个集合 Ti 本身又是一棵树,并且称之为根的子树。
注意:树的定义是一个递归定义,即在树的定义中又用到树的概念。
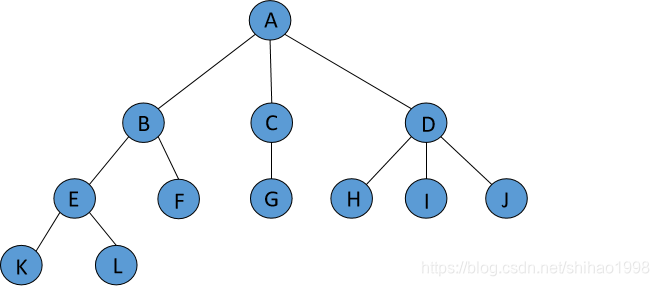
比如,这颗树,其中A是根,其余结点分成3个互不相交的子集:
T1={B, E, F, K, L}
T2={C, G}
T3={D, H, I, J}
T1, T2, T3 都是 A 的子树,且其本身也是一棵树。
比如T1, 其根为B, 其余结点分为两个互补相交的子集:
T11={E, K, L}
T12={F}
T11和T12都是T1的子树,且其本身也是一棵树。
…
基本术语:
一个结点的子树的根,称为该结点的孩子(儿子),相应的该结点称为子树的根的父亲。
没有孩子的结点称为树叶,又叫叶子结点。
具有相同父亲的结点互为兄弟。
用类似的方法可以定义祖父和孙子的关系。
从结点n1 到 nk 的路径定义为节点 n1 n2 … nk 的一个序列,使得对于 1 <= i < k,节点 ni是 ni+1 的父亲。这条路径的长是为该路径上边的条数,即 k-1。从每一个结点到它自己有一条长为 0 的路径。注意,在一棵树中从根到每个结点恰好存在一条路径。
如果存在从n1到n2的一条路径,那么n1是n2的一位祖先 ,而n2是n1的一个后裔。(也就是说自己既是自己的祖先也是自己的后裔)如果n1 != n2,那么n1是n2的真祖先, 而n2是n1的真后裔。
结点的层级从根开始定义,根为第一层,根的孩子为第二层。若某结点在第i层,则其孩子就在i+1层。
对任意结点ni,ni的深度为从根到ni的唯一路径的长。因此,根的深度为0。
ni 的高是从ni 到一片树叶的最长路径的长。因此,所有树叶的高都为0。
一颗树的高等于它根的高。一颗树的深度等于它最深的树叶的深度; 该深度总是等于这棵树的高。
性质:如果一棵树有n个结点,那么它有n-1条边。(为什么呢?)
每个孩子结点都有一个父亲,只有根节点没有父亲。
···········································································································································································
树的实现:
实现树的一种方法可以是在每一个结点除数据外还要有一些链,使得该结点的每一个儿子都有一个链指向它。
然而,由于每个结点的儿子数可以变化很大,并且事先不知道,因此,在数据结构中建立到各子结点的直接链接是不可行的,因为这样会产生太多浪费的空间。
那怎么办呢?
···········································································································································································
二叉树:
二叉树的性质:

···········································································································································································
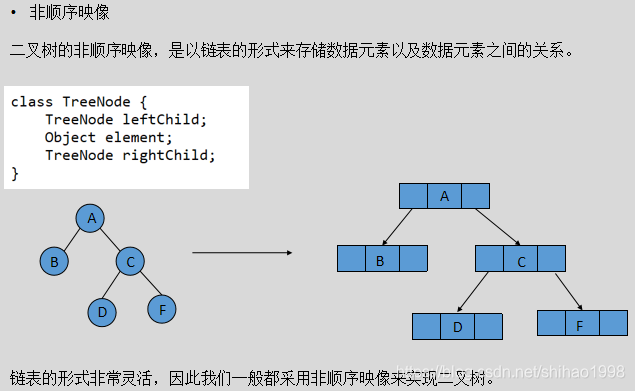
树的存储结构:

堆排序的时候我们是将数组看成一个树来处理的。
···········································································································································································
深度优先遍历:
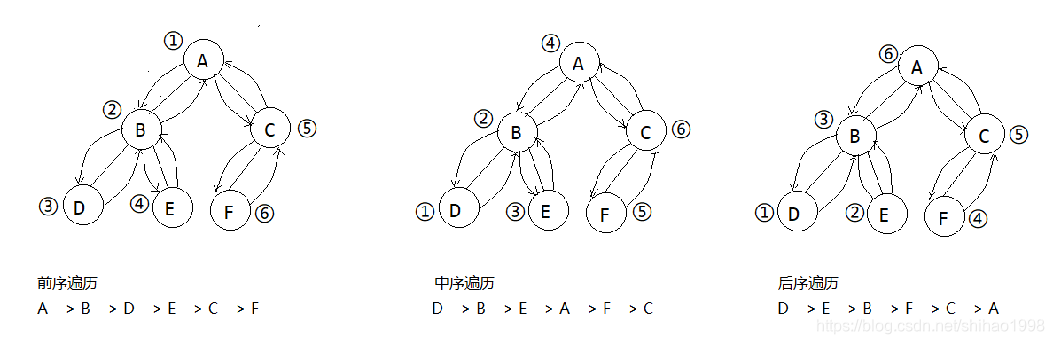
时间复杂度为O(n),n表示结点个数
很容易看出:三种遍历对每个结点都遍历了两次
二叉树的建树:

···········································································································································································
作业:
- 用栈实现队列数据结构。
package com.cskaoyan.Homework;import com.cskaoyan.queue.MyQueue;import java.util.Deque;
import java.util.LinkedList;/*** @author shihao* @create 2020-05-20 8:21* <p>* 用栈实现队列数据结构。* 思路:* push: 添加元素都是在s1中添加,并且用front标识队头元素。* pop: 出队列是从s2中出队列,如果s2是空的,就将s1中的元素倒入s2中。* peek: 如果s2是空的,就返回s1中标识的front, 否则返回s2的栈顶元素* empty: 两个栈都为空, 队列才为空* 队列的API:* void enqueue(E e)* E dequeue()* E peek()* boolean isEmpty()* int size()*/
public class StackQueue<E> {//属性private Deque<E> s1 = new LinkedList<>();private Deque<E> s2 = new LinkedList<>();E front;//方法/*** 入队** @param e*/public void enqueue(E e) {if (s1.isEmpty()) {front = e;}s1.push(e);}/*** 出队** @return*/public E dequeue() {if (s2.isEmpty()) {while (!s1.isEmpty()) {s2.push(s1.pop());}}return s2.pop();}/*** 获取队头元素** @return*/public E peek() {if (s2.isEmpty()) {return front;}return s2.peek();}/*** 判空** @return*/public boolean isEmpty() {return s1.isEmpty() && s2.isEmpty();}public static void main(String[] args) {StackQueue<Character> queue = new StackQueue<>();System.out.println(queue.isEmpty());queue.enqueue('A');queue.enqueue('B');queue.enqueue('C');System.out.println(queue.isEmpty());System.out.println(queue.dequeue());System.out.println(queue.dequeue());System.out.println(queue.dequeue());}
}- 用队列实现栈数据结构。
package com.cskaoyan.Homework;import java.util.Deque;
import java.util.EmptyStackException;
import java.util.LinkedList;/*** @author shihao* @create 2020-05-20 8:21** 用队列实现栈数据结构。* 思路:* 我们把队头当作栈顶。* push:* 1) 算出当前队列中元素的个数sz* 2) 在队尾添加元素e* 3) 从队头删除sz个元素,并且添加到队列的末尾。*/
public class QueueStack<E> {//属性private Deque<E> queue = new LinkedList<>();//方法/*** 入栈* @param e*/public void push(E e){int size = queue.size();queue.add(e);while(size>0){queue.add(queue.remove());size--;}}/*** 出栈* @return*/public E pop(){if(queue.isEmpty()){throw new EmptyStackException();}return queue.pop();}/*** 取栈顶元素* @return*/public E peek(){if(queue.isEmpty()){throw new EmptyStackException();}return queue.peek();}/*** 判空* @return*/public boolean isEmpty(){return queue.isEmpty();}public static void main(String[] args) {QueueStack<String> stack = new QueueStack<>();System.out.println(stack.isEmpty());stack.push("123");stack.push("456");stack.push("789");System.out.println(stack.isEmpty());System.out.println(stack.pop());System.out.println(stack.pop());System.out.println(stack.pop());}
}- 已知某二叉树的先序遍历为 ABDECFG,中序遍历为 DBEAFGC,试求它的后序遍历.
DEBGFCA
这篇关于week07_day02_Queue的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






