本文主要是介绍Hdoop学习笔记(HDP)-Part.20 安装Flume,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
Part.01 关于HDP
Part.02 核心组件原理
Part.03 资源规划
Part.04 基础环境配置
Part.05 Yum源配置
Part.06 安装OracleJDK
Part.07 安装MySQL
Part.08 部署Ambari集群
Part.09 安装OpenLDAP
Part.10 创建集群
Part.11 安装Kerberos
Part.12 安装HDFS
Part.13 安装Ranger
Part.14 安装YARN+MR
Part.15 安装HIVE
Part.16 安装HBase
Part.17 安装Spark2
Part.18 安装Flink
Part.19 安装Kafka
Part.20 安装Flume
二十、安装Flume
1.配置Ambari的flume资源
(1)下载ambari-flume-service服务
在外网服务器上,下载ambari-flume-service服务
git clone https://github.com/maikoulin/ambari-flume-service.git
下载flume的tar包,下载链接为
https://archive.apache.org/dist/flume/1.9.0/apache-flume-1.9.0-bin.tar.gz
将apache-flume-1.9.0-bin.tar.gz放到ambari-flume-service目录下
mkdir /root/ambari-flume-service/buildrpm/rpmbuild/SOURCES
cp /root/apache-flume-1.9.0-bin.tar.gz /root/ambari-flume-service/buildrpm/rpmbuild/SOURCES
执行编译生成rpm包,需要安装rpm-build命令,需要进入到shell脚本目录下执行
yum install -y rpm-build
cd /root/ambari-flume-service/buildrpm/
sh buildrpm.sh
将/root/ambari-flume-service/目录下的FLUME文件夹复制到hdp01的/var/lib/ambari-server/resources/stacks/HDP/3.1/services/目录下
重启ambari-server
ambari-server restart
此时可在ambari界面中看到flume服务
(2)创建flume本地yum源
在外网服务器上,将之前生成的rpm包(/root/ambari-flume-service/buildrpm/rpmbuild/RPMS/noarch/flume-1.9.0-1.el7.noarch.rpm)拷贝至hdp01的/opt下
创建flume的本地yum源
mkdir /var/www/html/flume
cp /opt/flume-1.9.0-1.el7.noarch.rpm /var/www/html/flume/
createrepo /var/www/html/flume/
配置所有节点的flume yum源
ansible all -m yum_repository -a 'name="flume" description="flume" baseurl="http://hdp01.hdp.com/flume" enabled=yes gpgcheck=no'
查看/etc/yum.repos.d/flume.repo文件
[flume]
baseurl = http://hdp01.hdp.com/flume
enabled = 1
gpgcheck = 0
name = flume
更新所有节点的yum配置
ansible all -m shell -a 'yum clean all'
ansible all -m shell -a 'yum makecache fast'
2.安装
添加flume服务
需要重启HDFS、YARN等相关服务
默认安装在current下,建议将其移动至3.1.5.0-152下,并在软链接到current下
cp -r /usr/hdp/current/flume-server/ /usr/hdp/3.1.5.0-152/
rm -rf /usr/hdp/current/flume-server/
ln -s /usr/hdp/3.1.5.0-152/flume-server/ /usr/hdp/current/
3.Agent配置
(1)Sources
**Exec Source:**用于文件监控,可以实时监控文件中的新增内容,类似于tail -F的效果
**NetCat TCP/UDP Source:**采集指定端口的数据,可以读取流经端口的每一行数据
**Spooling Directory Source:**采集文件夹中新增的文件
**Kafaka Source:**从Kafaka消息队列中采集数据
(2)Channels
**File Channel:**使用文件来作为数据的存储介质。优点是数据不会丢失,缺点是相对内存效率有的慢
**Memory Channel:**使用内存作为数据的存储接受,优点效率高,缺点会丢失数据,会存在内存不足的情况
**Spillable Memory Channel:**使用内存和文件作为存储介质,即内存足够把数据存内存中,不足的时候再写入到文件中
(3)Sinks
**Logger Sink:**将数据作为日志处理,可以将其选择打印到控制台或写到文件中
**HDFS Sink:**将数据传输到HDFS中,主要针对离线计算场景
**Kafka Sink:**将数据传输到Kafka消息队列中,主要针对实时计算场景
4.实验1:netcat收集并写入本地文件
以netcat为监测源,将输入内容写入到本地文件中
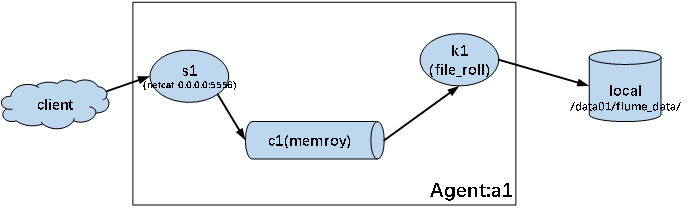
配置文件如下:
# 配置一个agent,agent的名称可以自定义(如a1)
# 指定agent的sources(如s1)、sinks(如k1)、channels(如c1)
a1.sources = s1
a1.channels= c1
a1.sinks = k1# source定义
a1.sources.s1.type = netcat
a1.sources.s1.bind = 0.0.0.0
a1.sources.s1.port = 5556# sink定义
a1.sinks.k1.type=file_roll
a1.sinks.k1.sink.directory=/data01/flume_data
a1.sinks.k1.sink.rollInterval=30# channel定义
a1.channels.c1.type = memory# 关系绑定
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1
输出的file_roll位置/data01/flume_data为目录,并非文件,并且需要手工创建
mkdir /data01/flume_data
chown flume:hadoop /data01/flume_data/
在hdp01上以netcat客户端连接hdp03.hdp.com:5556,并发送信息
nc hdp03.hdp.com 5556

在hdp03上查看结果文件

5.实验2:监控本地文件并写入到HDFS中
以本地日志文件为监测源,将输入内容写入到HDFS中
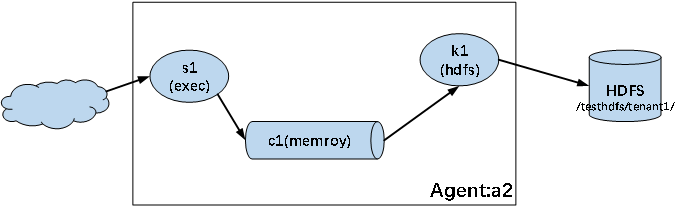
配置文件如下:
a2.sources = s1
a2.channels= c1
a2.sinks = k1# source定义
a2.sources.s1.type = exec
a2.sources.s1.command = tail -f /var/log/messages
a2.sources.s1.shell = /bin/sh -c# sink定义
a2.sinks.k1.type = hdfs
a2.sinks.k1.hdfs.kerberosPrincipal = tenant1@HDP315.COM
a2.sinks.k1.hdfs.kerberosKeytab = /root/keytab/tenant1.keytab
a2.sinks.k1.hdfs.path = hdfs://hdp315/testhdfs/tenant1/pt_time=%Y%m%d%H%M
a2.sinks.k1.hdfs.useLocalTimeStamp = true
a2.sinks.k1.hdfs.fileType = DataStream
a2.sinks.k1.hdfs.writeFormat = Text
a2.sinks.k1.hdfs.filePrefix = flume-%Y%m%d%H%M
a2.sinks.k1.hdfs.round = true
a2.sinks.k1.hdfs.roundUnit = minute
a2.sinks.k1.hdfs.roundValue = 1
a2.sinks.k1.hdfs.rollInterval = 10# channel定义
a2.channels.c1.type = memory# 关系绑定
a2.sources.s1.channels = c1
a2.sinks.k1.channel = c1
sink中参数说明:
filePrefix:文件前缀,会在hdfs上生成的文件前面加上这个前缀,属于可选项
writeFormat:默认为Writable,建议改为Text,如果后期想使用hive或者impala操作这份数据的话,必须在生成数据之前设置为Text,Text表示是普通文本数据
fileType:默认为SequenceFile,还支持DataStream和CompressedStream;DataStream不会对输出数据进行压缩,CompressedStream会对输出数据进行压缩
rollInterval:默认值为30,单位是秒,表示hdfs多长时间切分一个文件,因为这个采集程序是一直运行的,只要有新数据,就会被采集到hdfs上面,hdfs默认30秒钟切分出来一个文件,如果设置为0表示不按时间切文件
rollSize:默认为1024,单位是字节,最终hdfs上切出来的文件大小都是1024字节,如果设置为0表示不按大小切文件
rollCount:默认为10,表示每隔10条数据切出来一个文件,如果设置为0表示不按数据条数切文件
这篇关于Hdoop学习笔记(HDP)-Part.20 安装Flume的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








