本文主要是介绍中国湖泊面积-水位长时序数据产品(2000-2020),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
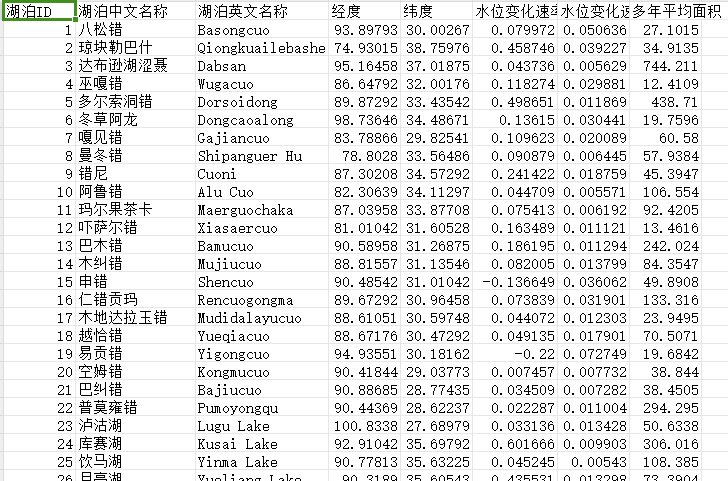
今天我们分享中国湖泊面积-水位长时序数据产品(2000-2020) 该数据集包含中国典型湖泊2000-2020年最大水体面积、多年平均面积、水位变化速率及空间分布矢量。 
数据溯源信息
「数据来源描述」Landsat、HJ、ZY、Jason、ENVISAT、Cryosat、ICESat和HY
「数据生成过程描述」 湖泊面积提取->水位
「提取数据质量信息」面积平均提取误差0.41%;Hydroweb雷达测高卫星水位与ICESat/ICESat-2水位相关性高于88%
「申明方式」中国湖泊面积-水位长时序数据产品(2000-2020)来源于中华人民共和国科学技术部国家遥感中心“全球生态环境遥感监测2021年度报告——全球典型湖泊生态环境状况”;
「引用方式」宋春桥,陈探,詹鹏飞,罗双晓.中国科学院南京地理与湖泊研究所.全球典型湖泊面积-水位长时序数据产品(2000-2020).2021年
获取方法
如有需要,请关注微信公众号「DataAssassin」后,后台回复「022」领取。
本文由 mdnice 多平台发布
这篇关于中国湖泊面积-水位长时序数据产品(2000-2020)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




