本文主要是介绍.net环境下跨进程、高频率读写数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、需求背景
1、最近项目要求高频次地读写数据,数据量也不是很大,多表总共加起来在百万条上下。
单表最大的也在25万左右,历史数据表因为不涉及所以不用考虑,
难点在于这个规模的热点数据,变化非常频繁。
数据来源于一些检测设备的采集数据,一些大表,有可能在极短时间内(如几秒钟)可能大部分都会变化,
而且主程序也有一些后台服务需要不断轮询、读写某种类型的设备,所以要求信息交互时间尽可能短。
2、之前的解决方案是把所有热点数据,统一加载到共享内存里边,到也能够支撑的住(毫秒级的),但是由于系统架构升级,之前的程序(20年前的)不能兼容。
只能重新写一个,最先想到的是用redis,当时把所有API重写完成后,测试发现效率不行,是的,你没有看错,redis也是有使用范围的。
3、redis读写非常快,但是对于大批量读写操作我觉得支持不够,虽然redis支持批量读写,但是效率还是不够快,
对于字符串(string)类型的批量读写,我测试过;效率比较好的在每批次200 至 250条之间,处理20万条数据耗时5秒左右, (PC机,8G,4核)
而对于有序集合(sorted set)类型,批量写的操作用起来非常别扭,而且没有修改API(如有其他方式请指教),我测试过,效率没string类型那么高
其他类型不适合我的业务场景,就没考虑使用了
4、所以项目组最后决定还是用回共享内存,先决定在.net环境下使用c#的共享内存,这个功能可能使用的人不多,其实在.net4.0版本就已经集成进来了
在System.IO.MemoryMappedFile命名空间下。这个类库让人很无语,因为里边能用的只有Write、Read这2种方法,而且只是针对字节的操作,
需要非常多的类型转换,非常麻烦!想想,只能以字节为单位去构建一个需要存放百万级数据的内存数据库,得多麻烦?
需要手动搞定索引功能,因为要支持各种查询,最后花了一天的时间写完DEMO,最后测试后发现效率并没有很大提高,因为当时加了互斥量测试,
二、没错,第一节写的太多了
1、最后分析,这应该是c#语言的瓶颈,c#对于这种骚操作是不那么成熟的。
2、最后瞄来瞄去,决定使用VC开发一个dll,在里边封装对内存数据的读写功能,然后c#调用
3、本人的C、C++不那么熟、参考了一些实例,比如园子里的:http://www.cnblogs.com/cwbcwb505/archive/2008/12/08/1350505.html
4、是的,你没有看错,2008年的,我还看到一篇更早的,看来底层开发C、C++那么经久不衰不是没有道理的,很多技术现在都在用
5、看看什么是共享内存
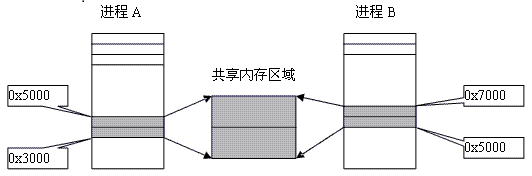
三、开始写代码了
1、首先建2个控制台项目,支持MFC,
2、先这样:一个负责创建共享内存,初始化数据
3、再这样:一个读写数据测试,最后修改
4、最后修改下图片细节,测试一下,看看效果
四、真的要贴代码了
1、先定义个枚举返回状态
1 typedef enum
2 {
3 Success = 0,
4 AlreadyExists = 1,
5 Error = 2,
6 OverSize = 3
7 }enumMemory;
2、再定义个结构体用来测试
1 typedef struct2 {3 int TagID;4 char TagName[32];5 int Area;6 double EngVal;7 double UpdateTime;8 double RawMax;9 double RawMin;
10 double RawVal;
11 char Name[50];
12 char Al;
13 double ASTime;
14 char MaskState;
15 double AMTime;
16 char Cf;
17 char Tdf;
18 char AlarmCode[32];
19 }TENG;
3、开始创建共享内存
1 int Create(UINT size)2 {3 // Data4 HANDLE fileMap = CreateFileMapping(INVALID_HANDLE_VALUE, NULL, PAGE_READWRITE, 0, size, “Name”);5 6 if (fileMap == NULL || fileMap == INVALID_HANDLE_VALUE)7 return Error;8 9 if (GetLastError() == ERROR_ALREADY_EXISTS)
10 return AlreadyExists;
11
12 // init
13 void *mapView = MapViewOfFile(fileMap, FILE_MAP_WRITE, 0, 0, size);
14
15 if (mapView == NULL)
16 return Error;
17 else
18 memset(mapView, 0, size);
19
20 return Success;
21 }
4、再开始写数据
1 int Write(void *pDate, UINT nSize, UINT offset)2 {3 // open4 HANDLE fileMap = OpenFileMapping(FILE_MAP_WRITE, FALSE, “Name”);5 6 if (fileMap == NULL)7 return Error;8 9 // hander
10 void *mapView = MapViewOfFile(fileMap, FILE_MAP_WRITE, 0, 0, nSize);
11
12 if (mapView == NULL)
13 return Error;
14 else
15 WriteDataPtr = mapView;
16
17 // write
18 memcpy(mapView, pDate, nSize);
19
20 UnmapViewOfFile(pMapView);
21 return Success;
22 }
5、开始读数据
1 int Read(void *pData, UINT nSize, UINT offset)2 {3 // open4 HANDLE fileMap = OpenFileMapping(FILE_MAP_READ, FALSE, GetTableName());5 6 if (fileMap == NULL)7 return Error;8 9 // hander
10 void *pMapView = MapViewOfFile(fileMap, FILE_MAP_READ, 0, 0, nSize);
11
12 if (pMapView == NULL)
13 return Error;
14 else
15 ReadDataPtr = pMapView;
16
17 memcpy(pData, (pMapView, nSize);
18
19 UnmapViewOfFile(pMapView);
20 return Success;
21 }
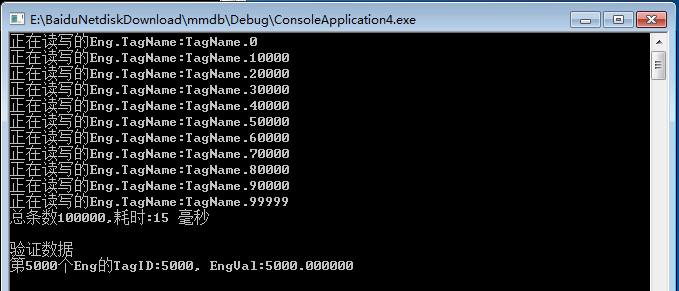
6、OK了,不复杂,网上都有这些资料,最后我们贴上测试程序
1 int _tmain(int argc, TCHAR* argv[], TCHAR* envp[])2 {3 int length = 100000;4 CEng * ceng = new CEng();5 DWORD dwStart = GetTickCount();6 7 for (int i = 0; i < length; i++) {8 TENG eng;9 ceng->Read(&eng, ceng->size, ceng->size * i);
10
11 eng.EngVal = i;
12 ceng->Write(&eng, ceng->size, (i*ceng->size));
13
14 if (i % 10000 == 0 || i == length - 1)
15 printf("正在读写的Eng.TagName:%s \n", eng.TagName);
16 }
17
18 printf("总条数%d,耗时:%d 毫秒 \n", length, GetTickCount() - dwStart);
19
20 // 验证数据
21 TENG eng5000;
22 ceng->Read(&eng5000, ceng->size, ceng->size * 5000);
23 printf("\n验证数据 \n");
24 printf("第5000个Eng的TagID:%d, EngVal:%lf \n", eng5000.TagID, eng5000.EngVal);
25
26
27 scanf_s("按任意键结束");
28 return 0;
29 }
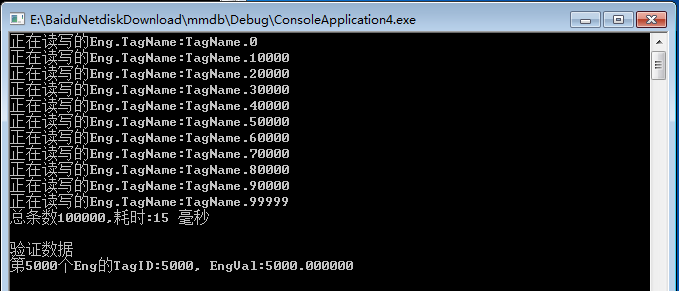
7、还有写测试程序
1 int _tmain(int argc, TCHAR* argv[], TCHAR* envp[])2 {3 int length = 100000;4 CEng * ceng = new CEng();5 ceng->Create(ceng->size * length);6 7 DWORD dwStart = GetTickCount();8 9 for (int i = 0; i < length; i++)
10 {
11 TENG eng;
12 memset(&eng, 0, ceng->size);
13
14 eng.TagID = i;
15 sprintf_s(eng.AlarmCode, "AlarmCode.%d", i);
16 sprintf_s(eng.TagName, "TagName.%d", i);
17
18 if (i % 10000 == 0 || i == length - 1)
19 printf("正在写入的Eng.TagName:%s \n", eng.TagName);
20
21 ceng->Write(&eng, ceng->size, (i*ceng->size));
22 }
23
24
25 // print time
26 printf("写入数据完毕,总条数:%d\n", length);
27 printf("初始化值共享内存区耗时:%d 毫秒 \n", GetTickCount() - dwStart);
28
29
30 scanf_s("按任意键结束");
31 return 0;
32 }
8、当然得再贴一遍啦
五、差点忘记做成DLL了
1、定义外部函数
1 extern "C" __declspec(dllexport) int ReadFromSharedMemory(TENG *pData, int nSize, int offset)
2 {
3 return ceng->Read(pData, nSize, offset);
4 }
5
6 extern "C" __declspec(dllexport) int WriteToSharedMemory(void *pData, int nSize, int offset)
7 {
8 return ceng->Write(pData, nSize, offset);
9 }
2、好了,VC到此为止,可以去领盒饭了,c#进场
1 public class Lib
2 {
3 [DllImport("ConsoleApplication4.dll", CallingConvention = CallingConvention.Cdecl)]
4 public static extern int ReadFromSharedMemory(IntPtr pData, int nSize, int offset);
5
6 [DllImport("ConsoleApplication4.dll", CallingConvention = CallingConvention.Cdecl)]
7 public static extern int WriteToSharedMemory(IntPtr pData, int nSize, int offset);
8 }
3、c#测试一下
1 static void Main(string[] args)2 {3 var length = 100000;4 var startTime = DateTime.Now;5 var size = Marshal.SizeOf(typeof(TEng));6 var intPtrOut = Marshal.AllocHGlobal(size);7 var intPtrIn = Marshal.AllocHGlobal(size);8 9 for (var i = 0; i < length; i++)
10 {
11 Lib.ReadFromSharedMemory(intPtrOut, size, size * i);
12
13 var eng = Marshal.PtrToStructure<TEng>(intPtrOut);
14 eng.EngVal = i;
15
16 Marshal.StructureToPtr(eng, intPtrIn, true);
17 Lib.WriteToSharedMemory(intPtrIn, size, size * i);
18
19 if (i % 10000 == 0)
20 Console.WriteLine("eng.TagID:{0}", eng.TagID);
21 }
22
23 Console.WriteLine("总条数{0},耗时:{1} 毫秒", length.ToString(),
24 (DateTime.Now - startTime).TotalMilliseconds.ToString());
25
26 // 验证数据
27 var intPtr100 = Marshal.AllocHGlobal(size);
28 Lib.ReadFromSharedMemory(intPtr100, size, size * 100);
29
30 var eng100 = Marshal.PtrToStructure<TEng>(intPtr100);
31
32 Console.WriteLine();
33 Console.WriteLine("验证数据");
34 Console.WriteLine("第100个Eng的TagID:{0},EngVal:{1}", eng100.TagID, eng100.EngVal);
35
36 Console.ReadKey();
37 }
4、165毫秒,相比在VC下运行,差了一个数量级,但是,也不错了;
因为c#环境下需要不断的Marshal.PtrToStructure、Marshal.StructureToPtr,频繁地把数据在托管内存俞共享内存之间搬运
是需要耗费时间的,这点有更好处理方式的请指教,
六、因为跨线程、进程,所以要考虑加入互斥量哦
1、很简单,MFC下有现成的类CMutex,加在Write里边在看看效率
互斥量是需要耗费资源的,多了将进100毫秒
2、读写都加上互斥量试试看
这篇关于.net环境下跨进程、高频率读写数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





