本文主要是介绍【代码】基于储能电站服务的冷热电多微网系统双层优化配置(完美复现)matlab/yalmip,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
程序名称:基于储能电站服务的冷热电多微网系统双层优化配置
实现平台:matlab-yalmip-cplex/gurobi
代码简介:代码主要做的是一个共享储能电站的双层优化配置模型,将储能电站服务应用到多维网系统中,建立了考虑不同时间尺度的多维网双层规划模型,上层模型负责求解长时间尺度的储能电站配置问题,下层模型负责求解短时间尺度的多微网系统优化运行问题。再 次,根据下层优化模型的Karush-Kuhn-Tucher(KKT)条件将下层模型转换为上层模型的约束条件,采用 Big-M 法对非线性问题线性化。最后,通过 3 个场景的算例分析验证所提双层规划模型的合理性和有效性。附带参考文献。
参考文献:《基于储能电站服务的冷热电多微网系统双层优化配置》
代码获取方式:代码获取方式
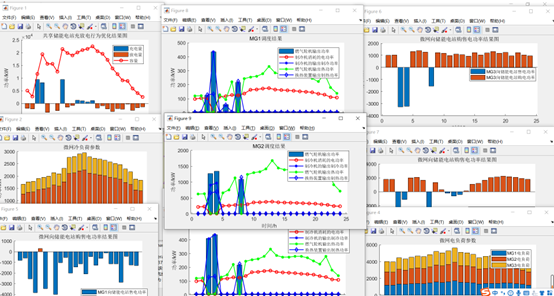
运行结果展示
这篇关于【代码】基于储能电站服务的冷热电多微网系统双层优化配置(完美复现)matlab/yalmip的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





