本文主要是介绍大小盘轮动策略:如何在上证50ETF与创业板50ETF之间实现高效投资,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1
引言
大小盘动量轮动策略是一种常见的量化投资策略,它利用市场中不同市值板块之间的相对强弱来实现盈利。本文以上证50ETF作为大盘股代表,以创业板50ETF作为小盘股代表。上证50ETF主要反映的是大盘蓝筹股的走势,其成份股主要是市值较大、流动性好、盈利能力强的优质企业。大盘股的投资特点是稳健、低风险,但可能收益较低。相比之下,创业板50ETF主要反映的是小盘成长股的走势,其成份股主要是市值较小、成长性较强的创新型企业。小盘股的投资特点是高风险、高收益。
动量投资策略的基本原理是强者恒强,弱者恒弱。即过去表现较好的资产在未来一段时间内很可能会继续表现优越,而过去表现较差的资产在未来一段时间内很可能会继续表现不佳。动量策略通过捕捉市场的趋势来实现盈利,本策略试图采用价格与均线的比值捕捉大盘和小盘之间的轮动,实现在两个ETF中进行择时交易,可以在不同市场环境下选择相对表现较好的指数ETF进行投资,获得更好的收益。
2
策略实现与回测
下面基于qstock获取上证50ETF和创业板50ETF行情数据。
import qstock as qs
import pandas as pd
import numpy as np
from tabulate import tabulate
import matplotlib.pyplot as pltdef etf_data(code1,code2,ma_period=20):#获取第一个ETF数据data1=qs.get_data(code1)data1['ma'] = data1['close'].rolling(ma_period).mean()data1['ma_ratio'] = (data1['close'] / data1['ma']) - 1data1=data1[['close','open','ma_ratio']]#获取第二个ETF数据data2=qs.get_data(code2)data2['ma'] = data2['close'].rolling(ma_period).mean()data2['ma_ratio'] = (data2['close'] / data2['ma']) - 1data2=data2[['close','open','ma_ratio']]#列重命名cols=['close','open','ma_ratio']cols1=[i+'_x' for i in cols]cols2=[i+'_y' for i in cols]data1=data1.rename(columns=dict(zip(cols,cols1)))data2=data2.rename(columns=dict(zip(cols,cols2)))#数据合并data=pd.concat([data1,data2],axis=1,join='inner').dropna()return datadf=etf_data('510050','159949',30)
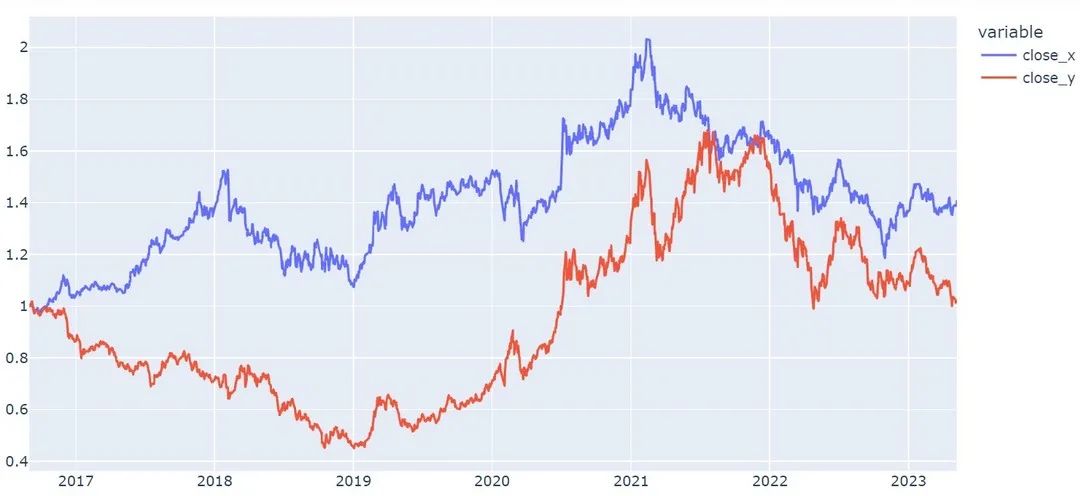
#上证50ETF(close_x,图中蓝色)和创业板50ETF(close_y,图中红色)
qs.line(df[['close_x','close_y']]/df[['close_x','close_y']].iloc[0])由于创业板50ETF上市较晚,因此回测期间为2016年9月1日至203年5月8日。以2016年9月1日为基准,上证50ETF和创业板50ETF累计净值如下图所示。2016.9-2018.12年,大盘强于小盘;2019.1-2021.1二者均出现向上趋势,小盘强于大盘;2021-2023.5指数均出现下跌趋势,其中大盘相对小盘较稳健。
交易策略思路:
交易策略基于两个指数ETF:上证50ETF(510050,代表大盘股)和创业板50ETF(159949,代表小盘股),下面分别使用x和y表示,对应价格为close_x和close_y。策略的核心逻辑是根据两者的均线比例动态调整持仓,以捕捉相对强势的标的,并在不同市场环境下实现超额收益。具体如下:
(1)若当前无持仓,根据昨日两个标的的均线比例判断:a. 若x的均线比例大于0且大于y的均线比例,买入x标的。b. 若y的均线比例大于0且大于x的均线比例,买入y标的。
(2)若当前持仓为x标的,根据昨日两个标的的均线比例判断:a. 若两者均线比例都小于0,卖出x标的并空仓。b. 若y的均线比例大于0且大于x的均线比例,卖出x标的,买入y标的。
(3)若当前持仓为y标的,根据昨日两个标的的均线比例判断:a. 若两者均线比例都小于0,卖出y标的并空仓。b. 若x的均线比例大于0且大于y的均线比例,卖出y标的,买入x标的。
策略在每个交易日都会根据上述逻辑进行相应的操作,从而实现在大盘股和小盘股之间的动态轮动。下面先基于pandas构建向量化的简易回测函数,这里暂不考虑交易手续费和滑点的影响。由于代码篇幅较长,此处省略,完整代码见Python金融量化知识星球【文末】。
def backtest(df):# 初始化holding = Nonedf['strategy_return']=0# 回测for i in range(1, len(df)):#判断持仓情况#空仓if holding is None:#注意信号判断要滞后一期#触发空仓条件#触发买入x标的条件#触发买入y标的条件#持仓xelif holding == 'x':#触发空仓条件#触发买入x标的条件#触发买入y标的条件#持仓yelif holding == 'y':#触发空仓条件#触发买入x标的条件#触发买入y标的条件#计算累计收益率#计算年化收益率#计算夏普比率#计算最大回撤# 输出回测指标比较结果回测结果如下:
backtest(etf_data('510050','159949',30))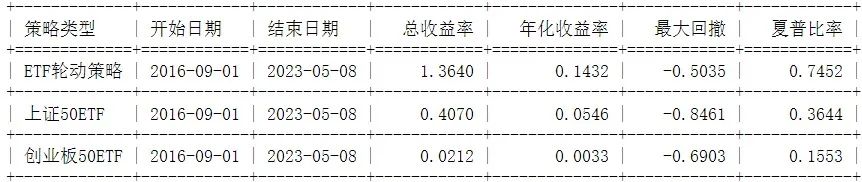
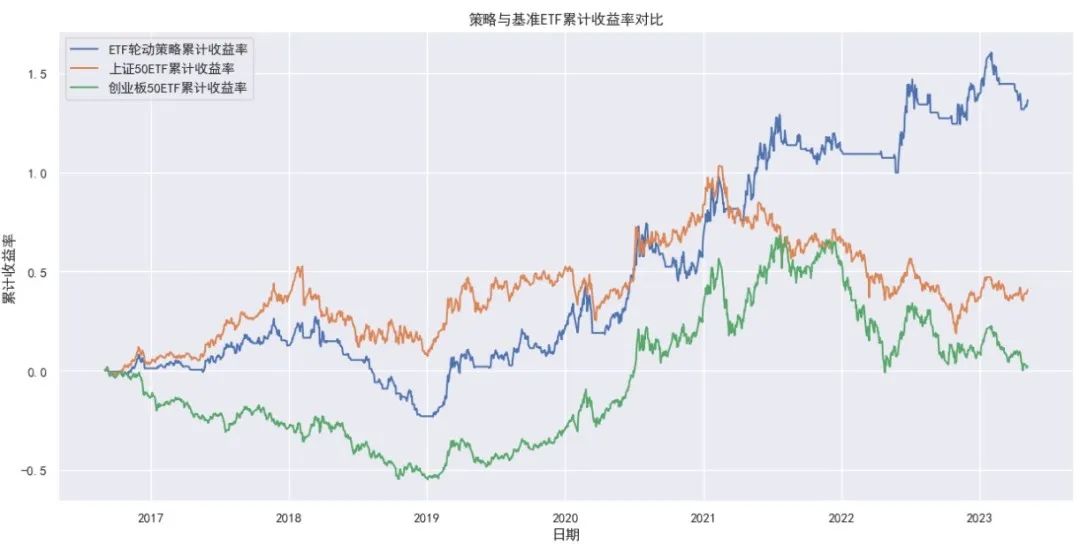
从回测结果来看,在2016年9月1日至2023年5月8日期间,ETF轮动策略的总收益率为1.3640,年化收益率为0.1432,相较于上证50ETF和创业板50ETF的表现,策略取得了较好的收益,同时策略在最大回撤和夏普比率上均优于买入持有对应指数ETF。当然,这里没有考虑交易手续费和滑点的影响。下面再给出基于backtrader事件驱动的回测结果(部分)进行比较。
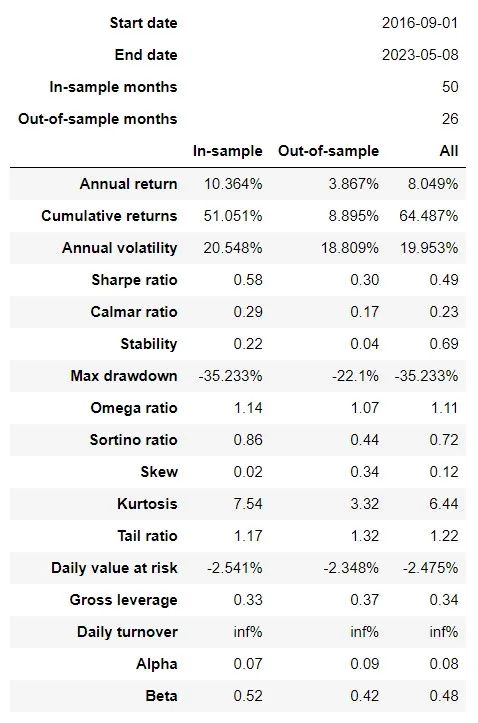
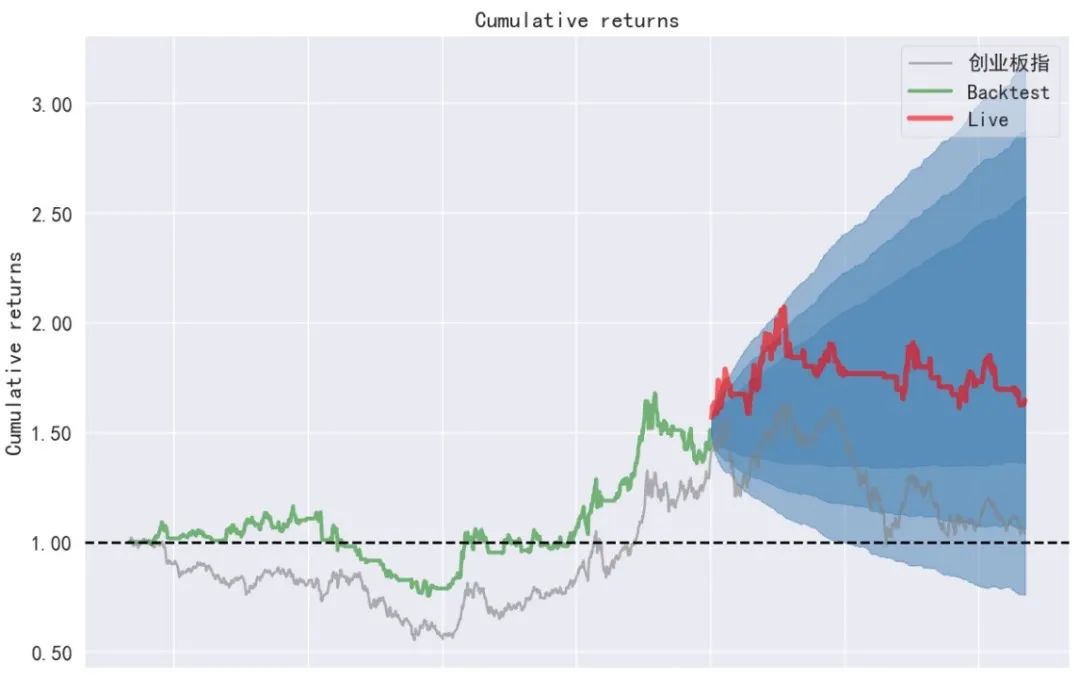
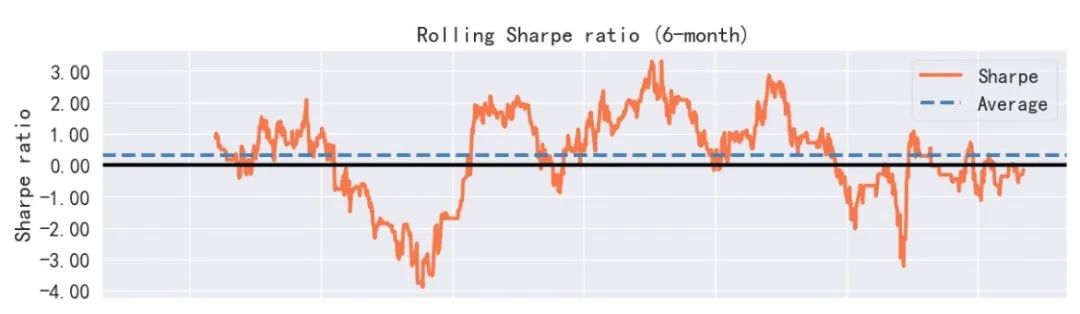
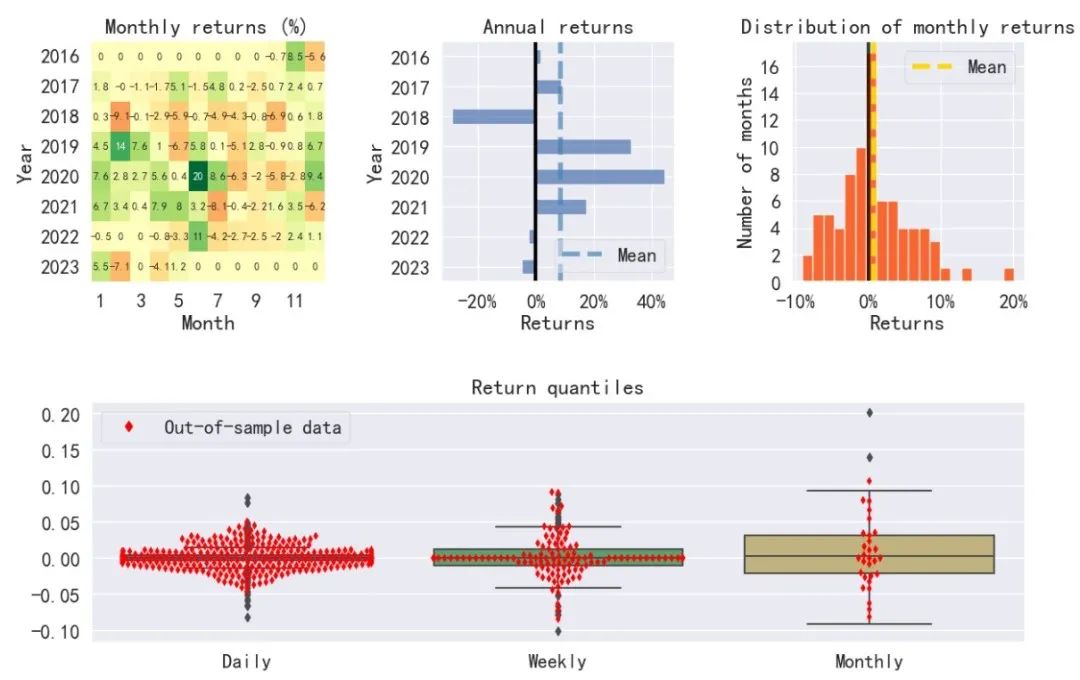
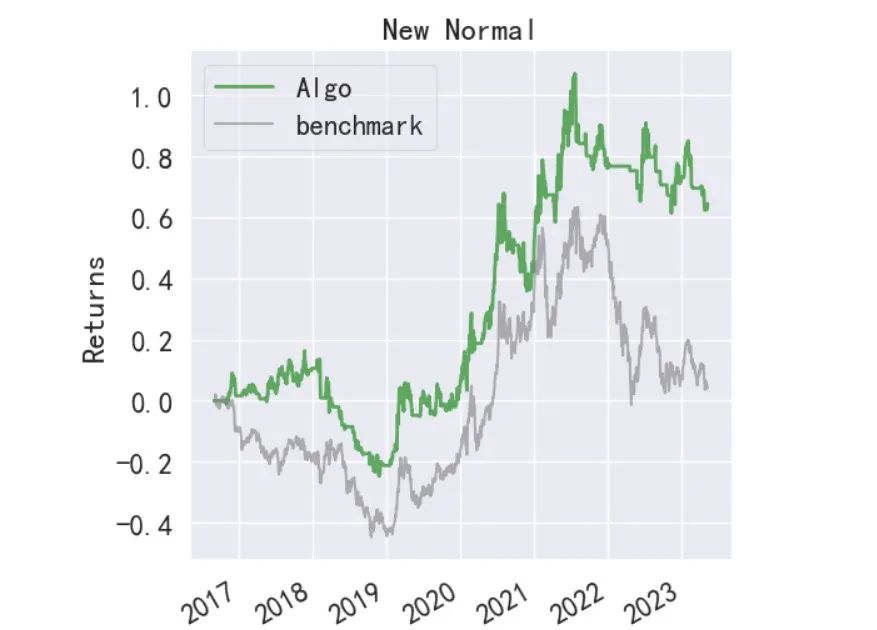
向量化回测和基于事件驱动的回测方法各有优缺点。向量化回测在计算速度上具有优势,但它假设在一个交易日内可以同时买卖,这在实际交易中是不现实的。相反,事件驱动回测会更接近现实交易环境,因为它是基于时间序列的,每个交易日的操作都会受到前一个交易日操作的影响。在本例中,backtrader回测结果表明年化收益率为8%,累计收益率64.48%,最大回撤35%,均低于向量化回测结果。这可能是因为向量化回测在计算收益时存在一定程度的偏差,导致收益被高估,而事件驱动回测则更接近实际交易情况。
3
结语
通过上述的大小盘指数ETF动量轮动交易策略,本文尝试在不同市场环境下捕捉相对强势的投资标的,以实现超额收益。策略关注上证50ETF(510050,代表大盘股)和创业板50ETF(159949,代表小盘股),并根据它们的均线比例动态调整持仓。然而,在实际操作中应谨慎对待此类策略,因为历史表现并不能确保未来的成功。在实际应用中,还需要关注风险管理、资金管理和交易成本等多个方面,确保策略的可持续性。同时,投资者可以尝试结合其他技术指标、市场情绪等因素,进一步优化策略,以适应不断变化的市场环境。总而言之,大小盘指数ETF动量轮动交易策略为我们提供了一个有趣的思路,有助于在市场波动中发现投资机会。但在实践中,大家应关注多种风险因素,不断完善和优化策略,以实现长期稳健的投资回报。

关于Python金融量化

专注于分享Python在金融量化领域的应用。加入知识星球,可以免费获取qstock源代码、30多g的量化投资视频资料、量化金融相关PDF资料、公众号文章Python完整源码、与博主直接交流、答疑解惑等。添加个人微信sky2blue2可获取八五折优惠。

这篇关于大小盘轮动策略:如何在上证50ETF与创业板50ETF之间实现高效投资的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




