本文主要是介绍Redis哈希对象(listpack介绍),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
哈希对象的编码可以是ziplist或者hashtable。再redis5.0版本之后出现listpack,为了是代替ziplist。
一. 使用ziplist编码
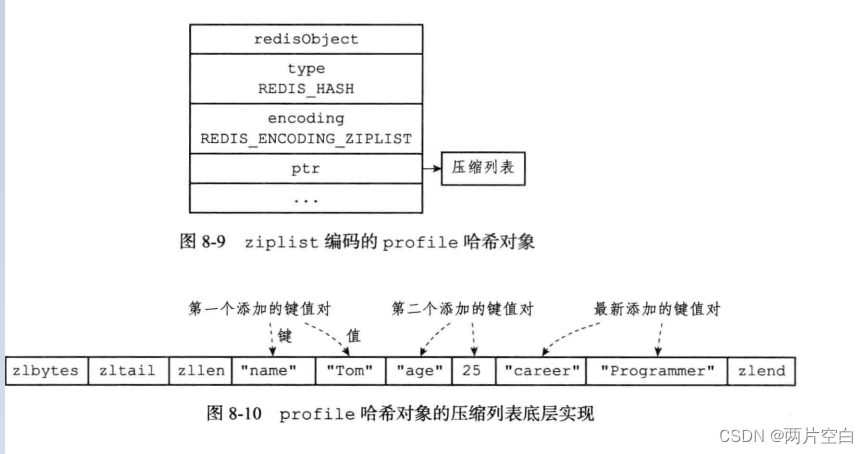
ziplist编码的哈希对象使用压缩列表作为底层实现,每当有新的键值对要加入到哈希对象时,程序都会先将保存了键值对的键的压缩列表节点推入到压缩列表表尾,再将保存了值的压缩列表节点推入到压缩列表表尾。
- 保存了同一键值对的两个节点总是紧挨在一起的,保存键的节点在前,保存值的节点在后。
- 先添加到哈希对象中的键值对会被放到压缩列表头方向,而后来添加到哈希对象中的键值对会被放在压缩列表的表尾方向。
127.0.0.1:6379> hset profile name "tom"
(integer) 1
127.0.0.1:6379> hset profile age 25
(integer) 1
127.0.0.1:6379> hset profile career "Programmer"
(integer) 1
127.0.0.1:6379> 如果Redis使用ziplist作为哈希对象的的编码,那么对象和对象使用的压缩列表会如下图:
二.使用hashtable编码
当使用hashtable编码的作为哈希对象的编码,是使用字典作为底层实现,哈希对象的每一个键值对都使用一个字典键值对来保存。
//字典节点结构
typedef struct dictEntry {//键void *key;//值union {void *val;uint64_t u64;int64_t s64;double d;} v;//指向下一个节点,形成链表struct dictEntry *next;
} dictEntry;- 字典每一个键都是一个字符串对象,对象中保存了键值对的键
- 字典每一个值都是一个字符串对象,对象中保存了键值对的值
举个例子,如果前面的profile键创建的不是ziplist编码的哈希对象,而是hashtable编码的哈希对象,那么这个哈希对象结构如下图:

三. 编码转换
当哈希对象可以同时满足以下两个条件时,哈希对象使用ziplist编码:
- 哈希对象保存的所有的键和值的字符串长度都小于64字节
- 哈希对象保存的键值对数量小于512个,不能满足这个条件的哈希对象需要使用hashtable编码。
四.哈希命令的实现

五. listpack编码
5.1 介绍
listpack(紧凑列表)时Redis5版本出现的,作用是为了代替ziplist。Redis7.0版本之后,listpack就完全替代了ziplist。
ziplist的缺点是,在极端的情况下,可能会出现连锁更新的情况,时间复杂度是O(N^2),会带来不小的性能消耗。ziplist介绍:Redis压缩列表-CSDN博客
虽然Redis在3.0版本后使用quicklist,通过quicklistNode来控制ziplist的大小和元素的个数,减少连锁更新带来的性能问题,但是它并没有避免连锁更新,使用的还是ziplist。
而listpack最大的特点是,每一个节点不再包含前一个节点的长度,而压缩列表正是因为节点中包含前一个节点的长度,所以存在连锁更新的隐患。
typedef struct {/* 当使用string时,它具有长度(slen)。 */unsigned char *sval;uint32_t slen;/* 当使用integer时,“sval”为 NULL,lval 保存该值。*/long long lval;
} listpackEntry;
listpackEntry中的slen属性记录的是当前节点的长度,而非前一个节点的长度。并且listpackEntry可以保存整数或者字符串。
- 当存储整数时,lval就是对应的整数值,sval为NULL,slen为0。
- 当存储字符串时,sval保存的时字符串的值,slen保存字符串的长度。
5.2 结构
通过创建一个listpack函数我们可以得到listpack的结构:
unsigned char *lpNew(size_t capacity) {unsigned char *lp = lp_malloc(capacity > LP_HDR_SIZE+1 ? capacity : LP_HDR_SIZE+1);if (lp == NULL) return NULL;lpSetTotalBytes(lp,LP_HDR_SIZE+1);lpSetNumElements(lp,0);lp[LP_HDR_SIZE] = LP_EOF;return lp;
}结构为:
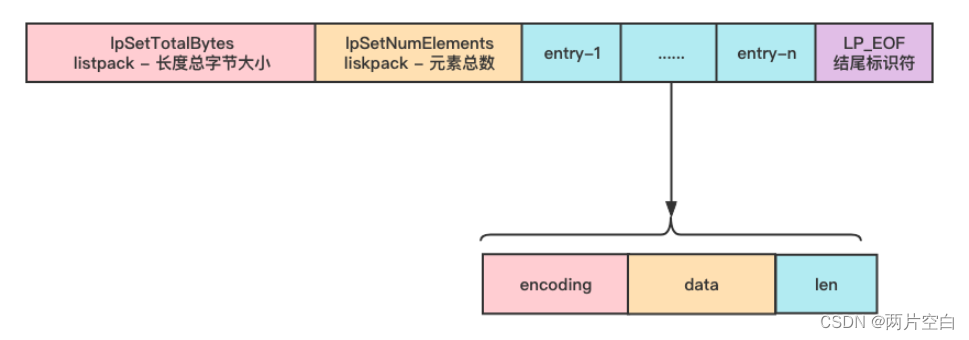
- encoding:编码,会对不同长度的整形和字符串进行编码
- data: 数据
- len:当前节点的长度。
5.3 与ziplist的区别
- listpack节点不包含前一个节点的长度,避免了连锁更新问题
- listpack结构没有指向末尾节点地址的偏移量,解决ziplist内存长度限制的问题,但是一个listpack最大内存使用不能超过1G。
这篇关于Redis哈希对象(listpack介绍)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





