本文主要是介绍LevelDB SSTable,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 什么是SSTable
- SSTable 的基本部件
- block 的实现
- 插入操作
- 有趣的变长整型及实现
- 存储block的元信息:BlockHandle
- 过滤器Filter的实现
- Filter的插入
- Filter的读取
- 元数据管理 Footer的实现
- Footer写入
- 读取Footer
- SSTable的实现
- data_block
- 插入数据
- 读取数据
- index_block
- SSTable的逻辑构成
- Block
- Table
- 写入Table
- Cache
- TableCache
- 查找Table
- 删除Table
- BlockCache
- 参考文献
什么是SSTable
SSTable 全称是 sort string table,也叫有序字符串表。在LevelDB中用于存储KV结构的数据。
SSTable 的基本部件
SSTable的主要由一个个block构成。之后添加上这个block的压缩类型信息 type 和 CRC 校验信息就组成了这么一条记录。多个这样的block构成了一个SSTable:

block 的实现
每个block的物理构成如下:

const Options* options_; //选项控制std::string buffer_; // 存放key-value的数组std::vector<uint32_t> restarts_;//重启点数组,因为保存的key依赖上一个key,所以一旦中间有错误数据,就会影响后面的key的复原。//所以这里采用重启点来避免部分损失int counter_; // 自上一个重启点以来,目前存入block的数量bool finished_; // BlokcBuilder::Finish()是否被调用std::string last_key_; //存储上一个key
插入操作
对于block来说,最重要的插入操作逻辑。我们来看一下一条KV记录是怎么插入的:
-
首先,block里面会保存上一个插入的
last_key值(第一次插入当然没有),这里是为了节省空间 -
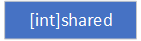
然后计算
last_key和此次key的重合字符数shared,并将shared添加至buffer中
-
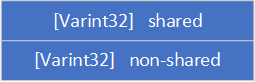
之后,计算
last_key和此次key不重合的字符数non-shared,并将non-shared添加至buffer中
-
计算
value的长度value_size,插入value_size至buffer

-
插入
key和last_key不同的地方以及value,至此完成一次KV插入

而对于多次的插入之中就需要重启点restart来做保证了,其存在也是因为保存的key依赖上一个key,所以一旦中间有错误数据,就会影响后面的key的复原。对于每个重启点来说,都可以看成last_key为空。

/*** @brief 存储key-value至buffer* * @param key key值* @param value value值*/
void BlockBuilder::Add(const Slice& key, const Slice& value) {Slice last_key_piece(last_key_);assert(!finished_);assert(counter_ <= options_->block_restart_interval);//buffer为空或者当前插入的key>上一次插入的keyassert(buffer_.empty() // No values yet?|| options_->comparator->Compare(key, last_key_piece) > 0);size_t shared = 0;if (counter_ < options_->block_restart_interval) {// 比较key和last_key 它们两个相同的地方const size_t min_length = std::min(last_key_piece.size(), key.size());while ((shared < min_length) && (last_key_piece[shared] == key[shared])) {shared++;}} else {// Restart compressionrestarts_.push_back(buffer_.size());counter_ = 0;}const size_t non_shared = key.size() - shared; //计算不是共享的部分字节数// Add "<shared><non_shared><value_size>" to buffer_PutVarint32(&buffer_, shared);PutVarint32(&buffer_, non_shared);PutVarint32(&buffer_, value.size());// Add string delta to buffer_ followed by valuebuffer_.append(key.data() + shared, non_shared);buffer_.append(value.data(), value.size());// Update statelast_key_.resize(shared);last_key_.append(key.data() + shared, non_shared);assert(Slice(last_key_) == key);counter_++;
}
有趣的变长整型及实现
刚刚我们看到插入中插入了变长32位整型,其目的也是为了省空间,因为很多整型都是1,3,12这种小数,明明一个Byte就能表示却浪费了4个Byte。所以在Google内部就大量使用变长整型。我们现在拿64位变长整型来举例:
变长整型的原理就是用每个字节的最高位来表示,这样对于整数1433223来说,其原本的二进制表示为:

这种情况下,我们就会浪费5字节的空间。空间利用率37.5%。
但是如果我们用变长整型来表示,其表示如下,空间利用率在这里例子中达到了100%

注:
这里我必须提及一句的是,变长64位整型最大是需要10字节来表示的。这个由来是7*9+1,所以说,变长整型在极端情况下是会浪费一定空间的。
其代码实现如下:
/*** @brief 转换value称为64位变成整型存放至dst中* * @param dst 存放数组* @param v 待转换的整数* @return char* 指向这个64位整型的结束位置*/
char* EncodeVarint64(char* dst, uint64_t v) {//一个字节所能表示的最大数,用来做终止标记static const int B = 128;uint8_t* ptr = reinterpret_cast<uint8_t*>(dst);while (v >= B) {*(ptr++) = v | B;v >>= 7;}*(ptr++) = static_cast<uint8_t>(v);return reinterpret_cast<char*>(ptr);
}
存储block的元信息:BlockHandle
如果说block负责存放具体的数据,那么BlockHandle就是用来存放每个block的元信息的。其只有两个变量,用来指明这个block存放的起始位置以及存放了多少数据:
,
private:uint64_t offset_; //偏移量uint64_t size_; //所占字节数
过滤器Filter的实现
Filter其实也是一个比较特殊的Block,其属性如下:

private:const FilterPolicy* policy_; // 过滤策略,目前是布隆过滤器std::string keys_; // 存储key的内容std::vector<size_t> start_; // 存储每个key在keys_中的下标索引std::string result_; // 存储迄今为止创建的所有过滤器信息std::vector<Slice> tmp_keys_; // 用于在GenerateFilter 计算时存储keysstd::vector<uint32_t>filter_offsets_; //每2kb数据创建一个bloom过滤器,这里面记录每个过滤器的偏移量
Filter的插入
Filter本质就是记录每个key所构成的过滤器,并对这个过滤器进行存储。这个具体是在AddKey函数中实现这个过程。这个函数会把key进行顺序存储,并通过start来记录每个key的索引用以区分。
/*** @brief 存储key至FilterBlock* * @param key key*/
void FilterBlockBuilder::AddKey(const Slice& key) {Slice k = key;//存放此时keys_的大小,可以看做每个key的索引start_.push_back(keys_.size());//存储key的内容keys_.append(k.data(), k.size());
}
那么假设我们现在要存储key:“gong”、“yan”、“qing”,那么内存中就会形成如下的布局:
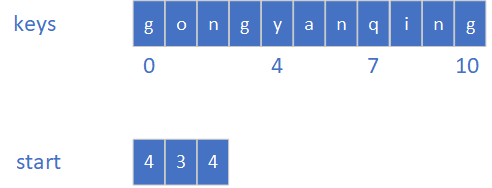
而这些块是什么时候生成过滤器的呢?当我们调用开启一个新block的函数StartBlock或者终止当前block的函数Finish,这两个函数最终都会调用函数GenerateFilter进行过滤器的生成。这个过程就会将过滤器添加至result之中并记录这个过滤器的偏移量到filter_offset之中,之后清空start和keys中的内容,开始下一轮的过滤器生成。这个过程和上面keys和start的插入过程相似,就不贴图了,直接放代码。
/*** @brief 清空当前存储的key并创建bloom过滤器来指向其* */
void FilterBlockBuilder::GenerateFilter() {const size_t num_keys = start_.size();if (num_keys == 0) {// Fast path if there are no keys for this filterfilter_offsets_.push_back(result_.size());return;}// Make list of keys from flattened key structurestart_.push_back(keys_.size()); // Simplify length computationtmp_keys_.resize(num_keys);for (size_t i = 0; i < num_keys; i++) {const char* base = keys_.data() + start_[i]; //base 指向这个keysize_t length = start_[i + 1] - start_[i]; //得到这个key的长度tmp_keys_[i] = Slice(base, length); //key 存储至tmp_keys_}// Generate filter for current set of keys and append to result_.filter_offsets_.push_back(result_.size());//创建bloom过滤器,并将其存储至result之中policy_->CreateFilter(&tmp_keys_[0], static_cast<int>(num_keys), &result_);tmp_keys_.clear();keys_.clear();start_.clear();
}
最后,当没有新的key添加的时候,就到了这个SSTable落盘的时候。这个时候会调用函数FilterBlockBuilder::Finish进行收尾工作,其会把所有的过滤器偏移量添加进去,然后添加4字节的过滤器起始偏移量和1字节的Baselg。

/*** @brief 最终调用,进行收尾工作* * @return Slice Filter中的聚合信息*/
Slice FilterBlockBuilder::Finish() {if (!start_.empty()) {GenerateFilter();}// Append array of per-filter offsetsconst uint32_t array_offset = result_.size();for (size_t i = 0; i < filter_offsets_.size(); i++) {PutFixed32(&result_, filter_offsets_[i]);}PutFixed32(&result_, array_offset);result_.push_back(kFilterBaseLg); // Save encoding parameter in resultreturn Slice(result_);
}
Filter的读取
读取过程这里单独包装了一个类:FilterBlockReader,其构造函数传入过滤策略和Filter字符串,然后其实就是进行一个反解析的过程。
/*** @brief Construct a new Filter Block Reader:: Filter Block Reader object* * @param policy 过滤策略* @param contents 包含Filter的字符串*/
FilterBlockReader::FilterBlockReader(const FilterPolicy* policy,const Slice& contents): policy_(policy), data_(nullptr), offset_(nullptr), num_(0), base_lg_(0) {size_t n = contents.size();if (n < 5) return; // 1字节BaseLg + 4字节的numsbase_lg_ = contents[n - 1];//得到最后一个过滤器的偏移量uint32_t last_word = DecodeFixed32(contents.data() + n - 5);if (last_word > n - 5) return;data_ = contents.data();offset_ = data_ + last_word;num_ = (n - 5 - last_word) / 4;
}
而真正进行key匹配的时候,首先就是把block_offset进行右移运算,因为是每2KB一个,这样做完之后就可以得到这个block_offset所对应的过滤器的index。由于每个过滤器的偏移量都是4字节,所以index*4就可以获得这个过滤器的偏移量,然后就可以判断了。
/*** @brief 过滤器的匹配过程* * @param block_offset 这个块的偏移量* @param key 这个块里面的key* @return true 匹配成功* @return false 匹配失败*/
bool FilterBlockReader::KeyMayMatch(uint64_t block_offset, const Slice& key) {//获得这个block_offset对应的是哪个过滤器uint64_t index = block_offset >> base_lg_;if (index < num_) {//每个过滤器的偏移量都是4字节,这里index*4就可以获得这个过滤器的偏移量uint32_t start = DecodeFixed32(offset_ + index * 4);uint32_t limit = DecodeFixed32(offset_ + index * 4 + 4);if (start <= limit && limit <= static_cast<size_t>(offset_ - data_)) {//获得过滤器字段Slice filter = Slice(data_ + start, limit - start);return policy_->KeyMayMatch(key, filter);} else if (start == limit) {// Empty filters do not match any keysreturn false;}}return true; // Errors are treated as potential matches
}
元数据管理 Footer的实现
Footer是SSTable中最上层的元数据管理模块,其属性表面有两个,分别用来描述meta_index_block和index_block这两个块的位置信息(后面会讲)。

private:BlockHandle metaindex_handle_; //记录meta_index的handleBlockHandle index_handle_; //记录index的handle
Footer写入
但是实际上,其被填充至SSTable的时候是会发生扩充的。再EncodeTo函数中,其会扩充至40字节,之后再添加上魔数信息,一起返回给上层存储的dst_buffer。

/*** @brief 转换meta_handle以及index_handle至dst,这个过程会把这两个handle填充至40 Bytes并再添加8 Bytes的魔数* * @param dst 存放转换后编码数据的字符串*/
void Footer::EncodeTo(std::string* dst) const {const size_t original_size = dst->size();metaindex_handle_.EncodeTo(dst);index_handle_.EncodeTo(dst);dst->resize(2 * BlockHandle::kMaxEncodedLength); // PaddingPutFixed32(dst, static_cast<uint32_t>(kTableMagicNumber & 0xffffffffu));PutFixed32(dst, static_cast<uint32_t>(kTableMagicNumber >> 32));assert(dst->size() == original_size + kEncodedLength);(void)original_size; // Disable unused variable warning.
}
读取Footer
读取Footer的过程在Table::Open函数中进行的(Table可以看成SSTable的内存映射)。这里就会按照SSTable的格式,从 偏移量-48字节(Footer的大小)的地方开始读取,之后反解析信息就能得到meta_index_block和index_block的信息。
/*** @brief 从内存中读取SSTable* * @param[in] options 环境选项信息* @param[in] file 要读取的文件指针* @param[in] size 要读取的字节数* @param[out] table 存储读取的数据* @return Status 执行状态 */
Status Table::Open(const Options& options, RandomAccessFile* file,uint64_t size, Table** table) {*table = nullptr;if (size < Footer::kEncodedLength) {return Status::Corruption("file is too short to be an sstable");}char footer_space[Footer::kEncodedLength];Slice footer_input;Status s = file->Read(size - Footer::kEncodedLength, Footer::kEncodedLength,&footer_input, footer_space);if (!s.ok()) return s;Footer footer;s = footer.DecodeFrom(&footer_input);...//解析index_handles = ReadBlock(file, opt, footer.index_handle(), &index_block_contents);...
}
SSTable的实现
SSTable的属性如下:

Options options; //环境控制信息Options index_block_options; // index_block环境控制信息WritableFile* file; //要写入的文件uint64_t offset; //当前基于这个table的偏移量Status status; //函数执行状态BlockBuilder data_block; //存储数据的blockBlockBuilder index_block; //块的索引信息std::string last_key; //上一个插入的keyint64_t num_entries; //每个块的key计数信息bool closed; // Either Finish() or Abandon() has been called.FilterBlockBuilder* filter_block; //过滤块
data_block
我们现在来介绍几个重要的块,首先就是data_block,这个块用于真正的存储KV数据。
插入数据
主要逻辑存在于TableBuilder::Add 函数之中,其首先会把这个KV数据存入data_block,之后如果data_block的容量达到环境控制中的block_size,其就会进行Flush,将数据落地到磁盘之中。
void TableBuilder::Add(const Slice& key, const Slice& value) {...r->last_key.assign(key.data(), key.size());r->num_entries++;r->data_block.Add(key, value); //添加到磁盘// 刷新到磁盘const size_t estimated_block_size = r->data_block.CurrentSizeEstimate();if (estimated_block_size >= r->options.block_size) {Flush();}
}
而调用Flush则是会触发两个操作:
- 准备压缩数据以及crc校验创建
- 为新的block创建过滤器
/*** @brief 信息刷新至磁盘**/
void TableBuilder::Flush() {Rep* r = rep_;assert(!r->closed);if (!ok()) return;if (r->data_block.empty()) return;assert(!r->pending_index_entry);//准备压缩数据以及crc校验创建WriteBlock(&r->data_block, &r->pending_handle);if (ok()) {r->pending_index_entry = true;r->status = r->file->Flush();}//为新的block创建过滤器if (r->filter_block != nullptr) {r->filter_block->StartBlock(r->offset);}
}
第二步我们之前剖析过了,现在我们来看一下是如何压缩和进行crc校验的。这个过程主要存在于函数WriteBlock之中,其会根据环境信息读取当前所采取的压缩算法。目前来说LevelDB只内置了一个压缩算法snappy。
case kSnappyCompression: {std::string* compressed = &r->compressed_output;if (port::Snappy_Compress(raw.data(), raw.size(), compressed) &&compressed->size() < raw.size() - (raw.size() / 8u)) {block_contents = *compressed;} else {// Snappy not supported, or compressed less than 12.5%, so just// store uncompressed formblock_contents = raw;type = kNoCompression;}
之后,会把这个类型信息添加到被压缩过后的block后面。这个过程在WriteRawBlock函数中得到实现,当前是WriteBlock函数调用的。做完这个时候就是计算出CRC校验码并添加到type之后。
/*** @brief* 这里将记录偏移量信息到handle同时将type和crc信息记录在block内容块后面,将内容写入到file中(这个file也在内存之中)** @param block_contents block块内容* @param type 压缩方法* @param handle block的句柄,包含位置信息*/
void TableBuilder::WriteRawBlock(const Slice& block_contents,CompressionType type, BlockHandle* handle) {Rep* r = rep_;//这里记录这个block的位置信息handle->set_offset(r->offset);handle->set_size(block_contents.size());r->status = r->file->Append(block_contents);if (r->status.ok()) {char trailer[kBlockTrailerSize];trailer[0] = type;// crc校验数据uint32_t crc = crc32c::Value(block_contents.data(), block_contents.size());crc = crc32c::Extend(crc, trailer, 1); // Extend crc to cover block typeEncodeFixed32(trailer + 1, crc32c::Mask(crc));r->status = r->file->Append(Slice(trailer, kBlockTrailerSize));if (r->status.ok()) {//偏移量后移r->offset += block_contents.size() + kBlockTrailerSize;}}
}
这样就形成了Table中的一条信息了。

值得注意的是,这里记录了这个插入的block的位置信息到变量pending_handle之中,这个主要用于下面的index_block之中。
读取数据
读取数据则是根据index_block里面存储的位置信息,从file中读取一条记录。之后校验CRC并进行解压缩。
/*** @brief 从file中读取根据handle记录的偏移量读数据到result* * @param file 文件* @param options 读取选项,主要的就是压缩信息* @param handle block的句柄* @param result 存储读取结果* @return Status 执行状态*/
Status ReadBlock(RandomAccessFile* file, const ReadOptions& options,const BlockHandle& handle, BlockContents* result) {result->data = Slice();result->cachable = false;result->heap_allocated = false;//从file中读取数据到contentssize_t n = static_cast<size_t>(handle.size());char* buf = new char[n + kBlockTrailerSize];Slice contents;Status s = file->Read(handle.offset(), n + kBlockTrailerSize, &contents, buf);if (!s.ok()) {delete[] buf;return s;}if (contents.size() != n + kBlockTrailerSize) {delete[] buf;return Status::Corruption("truncated block read");}// CRC校验const char* data = contents.data(); // Pointer to where Read put the dataif (options.verify_checksums) {const uint32_t crc = crc32c::Unmask(DecodeFixed32(data + n + 1));const uint32_t actual = crc32c::Value(data, n + 1);if (actual != crc) {delete[] buf;s = Status::Corruption("block checksum mismatch");return s;}}//解压缩数据switch (data[n]) {case kNoCompression:if (data != buf) {// File implementation gave us pointer to some other data.// Use it directly under the assumption that it will be live// while the file is open.delete[] buf;result->data = Slice(data, n);result->heap_allocated = false;result->cachable = false; // Do not double-cache} else {result->data = Slice(buf, n);result->heap_allocated = true;result->cachable = true;}// Okbreak;case kSnappyCompression: {size_t ulength = 0;if (!port::Snappy_GetUncompressedLength(data, n, &ulength)) {delete[] buf;return Status::Corruption("corrupted compressed block contents");}char* ubuf = new char[ulength];if (!port::Snappy_Uncompress(data, n, ubuf)) {delete[] buf;delete[] ubuf;return Status::Corruption("corrupted compressed block contents");}delete[] buf;result->data = Slice(ubuf, ulength);result->heap_allocated = true;result->cachable = true;break;}default:delete[] buf;return Status::Corruption("bad block type");}return Status::OK();
}
index_block
index_block则是data_block的索引数据。当data_block调用Flush函数的时候,pending_index_entry变量就会被置为true,这个时候就会给data_block创建索引。创建索引的规则如下:
假设last_key为"abc",此次的key为"abh",其就会产生一个最短距离的shortest_key,这个key满足条件last_key<=shortest_key<key。假设我们现在找到的shortest_key是"abd",那么其就会把data_block的handle信息和这个"abc"插入到index_block之中。

这个过程也在函数Table Builder::Add中得到实现,这也是Add函数的两大逻辑之一,这里我们就放出完整代码。
/*** @brief 添加key-value至磁盘** @param key key* @param value value*/
void TableBuilder::Add(const Slice& key, const Slice& value) {Rep* r = rep_;assert(!r->closed);if (!ok()) return;if (r->num_entries > 0) {assert(r->options.comparator->Compare(key, Slice(r->last_key)) > 0);}//上一个数据的block刚刷新到磁盘if (r->pending_index_entry) {assert(r->data_block.empty());//找到最短距离最近的key存储下来r->options.comparator->FindShortestSeparator(&r->last_key, key);std::string handle_encoding;r->pending_handle.EncodeTo(&handle_encoding);// index 存储last_key 和这个偏移量信息r->index_block.Add(r->last_key, Slice(handle_encoding));r->pending_index_entry = false;}if (r->filter_block != nullptr) {r->filter_block->AddKey(key);}r->last_key.assign(key.data(), key.size());r->num_entries++;r->data_block.Add(key, value);const size_t estimated_block_size = r->data_block.CurrentSizeEstimate();if (estimated_block_size >= r->options.block_size) {Flush();}
}
SSTable的逻辑构成
之后插入的数据会不断重复上面那个过程,直到最后调用TableBuilder::Finish函数。这个函数会把block一个个添加至file之中。在调用Finish函数之前,其实已经添加了若干个data_block了,现在的内存布局如下:

之后,将这些data_block组成的过滤器filter_block也添加至这个file之中。这个块是不进行压缩的,只是会添加CRC校验信息。

// Write filter blockif (ok() && r->filter_block != nullptr) {WriteRawBlock(r->filter_block->Finish(), kNoCompression,&filter_block_handle);}
下一步添加的就是存储filter_block元信息的meta_index_block,其会根据过滤器的名称生成一个key,加入我们用的是bloom过滤器,那么生成的key就是filter.bloom,而value则是filter_block的偏移量。
注:
强调一下,这个偏移量是基于此Table来说的


// Write metaindex blockif (ok()) {BlockBuilder meta_index_block(&r->options);if (r->filter_block != nullptr) {// Add mapping from "filter.Name" to location of filter datastd::string key = "filter.";key.append(r->options.filter_policy->Name()); // key:filter.bloom | value:filter_block_handlestd::string handle_encoding;filter_block_handle.EncodeTo(&handle_encoding);meta_index_block.Add(key, handle_encoding);}// TODO(postrelease): Add stats and other meta blocksWriteBlock(&meta_index_block, &metaindex_block_handle);}
之后,再写入data_block的索引信息index_block:

// Write index blockif (ok()) {if (r->pending_index_entry) {r->options.comparator->FindShortSuccessor(&r->last_key);std::string handle_encoding;r->pending_handle.EncodeTo(&handle_encoding);r->index_block.Add(r->last_key, Slice(handle_encoding));r->pending_index_entry = false;}WriteBlock(&r->index_block, &index_block_handle);}
最后,将footer信息写入Table中,这样就完成了一个表的创建。

// Write footerif (ok()) {Footer footer;footer.set_metaindex_handle(metaindex_block_handle);footer.set_index_handle(index_block_handle);std::string footer_encoding;footer.EncodeTo(&footer_encoding);r->status = r->file->Append(footer_encoding);if (r->status.ok()) {r->offset += footer_encoding.size();}}
Block
block就是磁盘中block的内存映射。其属性如下:

const char* data_; //数据size_t size_; //数据长度uint32_t restart_offset_; // Offset in data_ of restart arraybool owned_; // Block owns data_[]
Block类需要存放Block的中转类BlockContent来进行构造:
Block::Block(const BlockContents& contents): data_(contents.data.data()),size_(contents.data.size()),owned_(contents.heap_allocated) {if (size_ < sizeof(uint32_t)) {size_ = 0; // Error marker} else {size_t max_restarts_allowed = (size_ - sizeof(uint32_t)) / sizeof(uint32_t);if (NumRestarts() > max_restarts_allowed) {// The size is too small for NumRestarts()size_ = 0;} else {//计算重启点偏移量restart_offset_ = size_ - (1 + NumRestarts()) * sizeof(uint32_t);}}
}
而为了更好的遍历Block,则可以通过NewIterator来生成一个迭代器。
/*** @brief 生成迭代器** @param comparator 排序器* @return Iterator* 迭代器,指向数据的起始位置*/
Iterator* Block::NewIterator(const Comparator* comparator) {if (size_ < sizeof(uint32_t)) {return NewErrorIterator(Status::Corruption("bad block contents"));}const uint32_t num_restarts = NumRestarts();if (num_restarts == 0) {return NewEmptyIterator();} else {return new Iter(comparator, data_, restart_offset_, num_restarts);}
}
Table
Table可以看成是SSTable的内存映射,其支持以下特性:
- 不可更改
- 持久
- 外部支持多个线程访问
属性如下:

Options options; // table相关参数信息Status status; // table状态信息RandomAccessFile* file; // table本身所映射的文件uint64_t cache_id; // table对应的缓存idFilterBlockReader* filter; //负责filterBlock的读取const char* filter_data; //对应的filter数据BlockHandle metaindex_handle; // Handle to metaindex_block: saved from footerBlock* index_block; // index_block数据
写入Table
- Table的构建最初始于
DBImpl::WriteLevel0Table,其会把内存中的MemTable写入LSM的第0层,在这个函数里面会调用BuildTable的构造函数。
Status DBImpl::WriteLevel0Table(MemTable* mem, VersionEdit* edit,Version* base) {...//构建SSTable的文件名,即file_numberFileMetaData meta;meta.number = versions_->NewFileNumber();pending_outputs_.insert(meta.number);Iterator* iter = mem->NewIterator();Log(options_.info_log, "Level-0 table #%llu: started",(unsigned long long)meta.number);Status s;{mutex_.Unlock();//调用BuildTables = BuildTable(dbname_, env_, options_, table_cache_, iter, &meta);mutex_.Lock();}...return s;
}
- 其他的我们先不管,我们先进入BuildTable的构造函数之中,看看这之中做了什么。这里会根据传入的
file_number创建SSTable在磁盘上的文件名称并打开这个文件。之后把immtable的数据不断的写入SSTable,最后刷盘。
/*** @brief 将imemtable的数据刷到磁盘中的SSTable* * @param dbname db名称* @param env 环境信息* @param options db的选项信息* @param table_cache table_cache* @param iter memtable的迭代器* @param meta 这个文件的元数据信息* @return Status */
Status BuildTable(const std::string& dbname, Env* env, const Options& options,TableCache* table_cache, Iterator* iter, FileMetaData* meta) {Status s;meta->file_size = 0;iter->SeekToFirst(); //偏移到迭代器的起始位置//得到memtable应该在磁盘上对应的SSTable名称std::string fname = TableFileName(dbname, meta->number);if (iter->Valid()) {WritableFile* file;//打开并创建这个files = env->NewWritableFile(fname, &file);if (!s.ok()) {return s;}TableBuilder* builder = new TableBuilder(options, file);meta->smallest.DecodeFrom(iter->key());Slice key;//不断地把imemtable的数据复制到sstable中for (; iter->Valid(); iter->Next()) {key = iter->key();builder->Add(key, iter->value());}if (!key.empty()) {meta->largest.DecodeFrom(key);}// sstable落盘s = builder->Finish();if (s.ok()) {meta->file_size = builder->FileSize();assert(meta->file_size > 0);}delete builder;// Finish and check for file errorsif (s.ok()) {s = file->Sync();}if (s.ok()) {s = file->Close();}delete file;file = nullptr;if (s.ok()) {// Verify that the table is usableIterator* it = table_cache->NewIterator(ReadOptions(), meta->number,meta->file_size);s = it->status();delete it;}}// Check for input iterator errorsif (!iter->status().ok()) {s = iter->status();}if (s.ok() && meta->file_size > 0) {// Keep it} else {env->RemoveFile(fname);}return s;
}
Cache
之前一篇文章我们介绍过LevelDB中Cache的原理:LevelDB的缓存机制。
这篇则是主要介绍缓存在LevelDB中的应用:
- 一是一SSTable为基本单位的
TableCahe - 二则是以字节为单位的
BlockCache
无论是哪种Cache,其最终的作用都是:提升性能!!
TableCache
TableCache主要就是对Cache类的一个封装,我们可以看一下它的属性。

private:Env* const env_; //环境信息句柄const std::string dbname_; // SST名字const Options& options_; // Cache参数配置Cache* cache_; // Cache句柄
一开始的时候,会根据外部传入的信息entries指定cache的容量:
/*** @brief Construct a new Table Cache:: Table Cache object* * @param dbname SST名称* @param options Cache选项信息* @param entries cache容量*/
TableCache::TableCache(const std::string& dbname, const Options& options,int entries): env_(options.env),dbname_(dbname),options_(options),cache_(NewLRUCache(entries)) {}
查找Table
查找的过程传入两个参数file_number 和 file_size,这两个信息标识了我们要找的是哪个file。
首先,会在内存的Cache中寻找key,找不到key的话就会从磁盘中将这个文件打开。假设我们的dbname="hello",file_number=123,那么这个file在磁盘中的名称就是"hello.123.ldb",这样我们就能根据file_number来定位到磁盘中的文件。
打开文件之后,就是反解析的过程,这个过程主要通过Table::Open来实现。做的主要工作就是根据SSTable的文件格式反解析。
/*** @brief 根据file_number找到SSTable** @param[in] file_number file的标识信息* @param[in] file_size file的大小* @param[out] handle 指向缓存中的这个Table* @return Status 执行状态*/
Status TableCache::FindTable(uint64_t file_number, uint64_t file_size,Cache::Handle** handle) {//在当前Cache中找Table,file_number就是Table的keyStatus s;char buf[sizeof(file_number)];EncodeFixed64(buf, file_number);Slice key(buf, sizeof(buf));*handle = cache_->Lookup(key);if (*handle == nullptr) {//得到文件名std::string fname = TableFileName(dbname_, file_number);RandomAccessFile* file = nullptr;Table* table = nullptr;//创建一个RandomAccessFile,这一步会从磁盘打开文件s = env_->NewRandomAccessFile(fname, &file);if (!s.ok()) {//这里是为了版本兼容,老版本使用.sst 新版本使用.ldbstd::string old_fname = SSTTableFileName(dbname_, file_number);if (env_->NewRandomAccessFile(old_fname, &file).ok()) {s = Status::OK();}}if (s.ok()) {//这一步是解析这个文件的格式,让table指向解析后的文件数据s = Table::Open(options_, file, file_size, &table);}if (!s.ok()) {assert(table == nullptr);delete file;// We do not cache error results so that if the error is transient,// or somebody repairs the file, we recover automatically.} else {TableAndFile* tf = new TableAndFile;tf->file = file;tf->table = table;*handle = cache_->Insert(key, tf, 1, &DeleteEntry);}}return s;
}
删除Table
刚刚的查找操作其实暗含了插入,所以我们这里就跳过其,直接来介绍删除table操作TableCache::Evict,删除操作其实调用的就是cache的Earse函数。
/*** @brief 删除缓存中的file* * @param file_number file的id号*/
void TableCache::Evict(uint64_t file_number) {char buf[sizeof(file_number)];EncodeFixed64(buf, file_number);cache_->Erase(Slice(buf, sizeof(buf)));
}
至此,我们不难看出其实TableCache就是cache的一个封装。
BlockCache
block_cache是一个全局唯一的cache,并用于存储block,并没有被封装成类,其在DBImpl::SanitizeOptions函数中得到调用。
Options SanitizeOptions(const std::string& dbname,const InternalKeyComparator* icmp,const InternalFilterPolicy* ipolicy,const Options& src) {...if (result.block_cache == nullptr) {//创建block_cacheresult.block_cache = NewLRUCache(8 << 20);}return result;
}
而其他的插入场景则是更多的在Table::BlockReader之中:
cache_handle = block_cache->Insert(key, block, block->size(),&DeleteCachedBlock);
参考文献
[1] leveldb 源码
这篇关于LevelDB SSTable的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




