本文主要是介绍卡方检验Excel、Python、R计算过程详解案例实战说明,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Excel Python R卡方检验
1 声明
本文的数据来自网络,部分代码也有所参照,这里做了注释和延伸,旨在技术交流,如有冒犯之处请联系博主及时处理。
2 卡方简介
针对分类变量,考察实际观测值与理论推断值之间的偏离程度,即卡方值的大小,如果卡方值越大,二者偏差程度越大;反之,二者偏差越小。
卡方检验的思想在于比较期望频数和实际频数的吻合程度,这里的原假设是期望频数等于实际频数, 即两个分类变量无关, 备择假设为期望频 数不等于实际频数,即两个变量有关。
统计量计算公示见下:

卡方分布:

3 卡方检验
纯Excel版
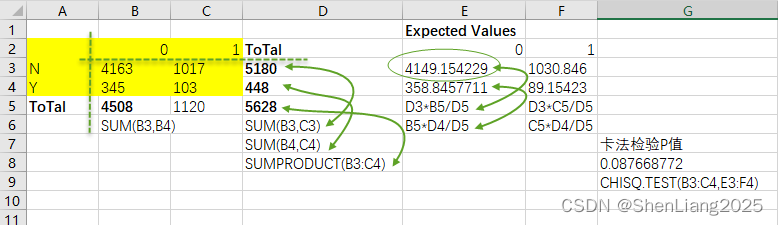
注:纯Excel版可计算p值,但期望值需要自己预先计算好。这里P值等于0.087大于α(0.05),所以接受原假设,即两个分类变量无关。
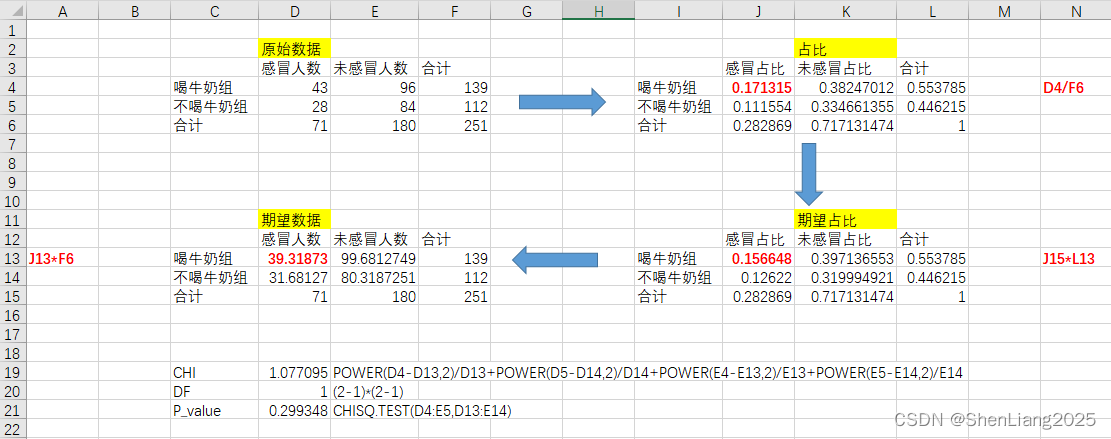
案例2:(数据源于网络,计算过程见红色高亮处):这里p值等于0.2993大于α(0.05),所以接受原假设,即感冒和喝牛奶无关。
Python版
import pandas as pd
from scipy.stats import chi2_contingency
pd1 = pd.DataFrame({"0": [4163,345],"1":[1017,103]},index=['N','Y'])
print(pd1)
print(chi2_contingency((pd1)))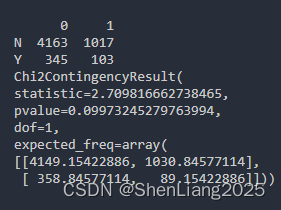
R版
tableR<- matrix(c(4163,345,1017,103),nrow=2,ncol=2)
chisq.test(tableR)
![]()
Real Statistics Excel插件版
(借助real Statistics Excel统计分析插件):
安装参考官网https://www.real-statistics.com/
Step1:找到Misc,卡方检验。

Step2 准备数据
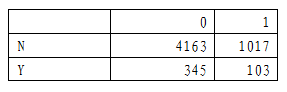
Step3 数据格式勾选excel format,假设类型选择None,选择输入区、设定输出区域后点确定按钮。

Step3 输出卡方检验结果

4 问题总结
无
这篇关于卡方检验Excel、Python、R计算过程详解案例实战说明的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






