本文主要是介绍半自动批量下载IEEE文献,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
因为一直在外边联合培养,无法使用学校的数据库,所以下载文献一下子从最简单的事情变成最复杂的事情。
首先想到的方法是学校放一台电脑,然后开teamviewer,远程操控,但公司和学校的双重烂网速让这件本来很简单的事情变得困难重重。
所以想到了绕个捷径通过http://sci-hub.cc/这个网站实现IEEE文献的下载。奔跑着歌颂一下这个俄罗斯大神搭建的网站,它可以让所有人通过该网站下载到大部分文献。
比如我要下载这篇文献,http://ieeexplore.ieee.org/document/6714990/,将网址复制到该网站,就会生成该论文的pdf,点击保存一下即可,仔细看一下,其实网址有了稍微一丁点变化,http://ieeexplore.ieee.org.sci-hub.cc/document/6714990/,加上了.sci-hub.cc,在网页审查一下元素发现下载地址(后缀名是.PDF)的那个就在这里摆着

这就简单了,首先将你在ieee官网上想要下载的多个文献的网址复制下来,每一个网址后面加上.sci-hub.cc,解析每一个新的网址,寻找.pdf的链接,获取真实的下载地址。
code:
#第一次变换地址
lines=open('d:/list.txt').readlines()
fp=open('D:/list.txt', 'w')
for s in lines:fp.write( s.replace('org','org.sci-hub.cc'))
fp.close()
#解析出真正的下载地址
import re
import urllib.request
# ------ 获取网页源代码的方法 ---
def getHtml(url):page = urllib.request.urlopen(url)html = page.read()return html
f=open('d:/list.txt')
for line in f:html = getHtml(line)html = html.decode('UTF-8')reg = r'src = "(.*?\.pdf)"'PDFre = re.compile(reg);PDFlist = re.findall(PDFre, html)print(PDFlist)
f.close()使用方法,新建一个txt文档,将要下载的文献地址复制过来
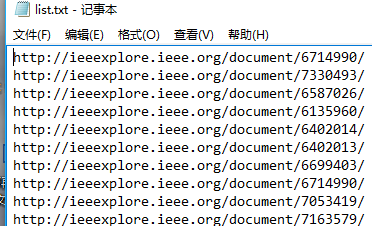
运行程序,就会生成真正的下载链接

复制一下打开迅雷,直接批量下载了
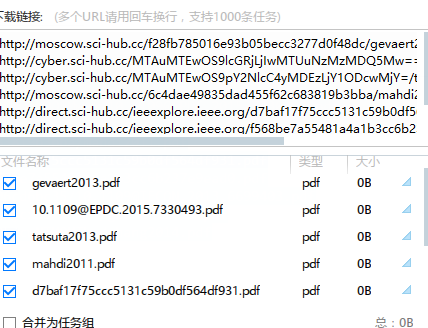
如果没有迅雷,可以使用python实现wget完成下载,加入代码
import sys,urllib
def reporthook(*a): print(a)
for url in sys.argv[1:]:i=url.rfind('/')file=url[i+1:]print(url,'-->',file)urllib.request.urlretrieve(url,file,reporthook)enjoy it!
最后借用互联网之子亚伦·斯沃茨的一句质疑:科研,如果用的是纳税人的钱,为什么最后的成果不能被我们纳税人自由地获取?获利的却是出版商呢?
这篇关于半自动批量下载IEEE文献的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







