本文主要是介绍明明服务化了,为啥耦合更加严重了?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
什么是耦合?
耦合,是架构中,本来不相干的代码、模块、服务、系统因为某些原因联系在一起,各自独立性差,影响则相互影响,变动则相互变动的一种架构状态。
感官上,怎么发现系统中的耦合?
作为技术人,每每在心中骂上下游,骂兄弟部门,“这个东西跟我有什么关系?为什么需要我来配合做这个事情?”。明明不应该联动,却要被动配合,就可能有潜在的耦合。
但如果服务化不合理,将部分个性化业务下沉到了底层,就是一个耦合的典型案例。
场景还原
业务1,业务2,业务3,因为join导致数据库实例耦合在了一起。
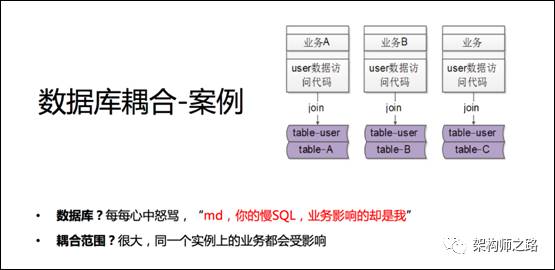
为了实现通用数据库table-user的解耦,实施了服务化,将通用user数据的访问抽象出了服务。
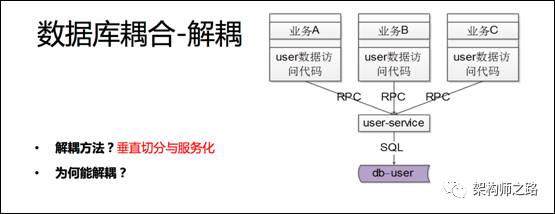
由于服务化不合理,会有很少很少的个性化业务逻辑,实现在底层的服务中,典型的伪代码是:
switch(biz_type){
case(1) : exec_logic1();
case(2) : exec_logic2();
case(3) : exec_logic3();
default : exec_default();
}
为什么会引发耦合呢?
不妨设,业务1来了一个新的个性化需求,这个需求本来实现在业务1自己的代码里是合理的,但工程师S想到,底层的通用服务里也有业务1的一小撮个性化代码,评估后,发现实现在底层新的需求改动的代码最小,时间最短,于是来找底层服务的负责人工程师B。
- 业务1工程师S:“有个小需求,帮个忙呗”
- 底层工程师B:“个性化实现在底层不合理”
- 业务1工程师S:“反正都有switch case的代码了,再改一点也不麻烦,在我这边实现特别复杂,要xxoo这么搞”
- 底层工程师B:“确实很复杂,那我来吧”
- …
遗留了不合理的代码,就会有第一次妥协,妥协了业务1,就会妥协业务2,随着时间的推移,底层服务越来越复杂:
(1)业务1,业务2,业务3的个性化代码越来越多;
(2)业务1,业务2,业务3的需求越来越多提给底层工程师;
(3)底层工程师慢慢成了项目瓶颈,业务1,业务2,业务3的项目逐步delay,但逐步都怪到了底层工程师的头上;
直到有一天,底层服务出了一个小bug,影响了业务1,业务2,业务3,历史总是惊人的相似:
- 业务1的大boss在群里首先发飙:“技术都干啥了,怎么系统挂了”
- 业务1的工程师S一脸无辜:“底层系统改造,工程师S的bug”
额,然而,这个理由,好像在大boss那解释不通…
- 底层服务工程师B一脸委屈:“...”。明明需求是业务方的,为什么修改代码的是我底层呢,业务代码出了问题,为什么责怪的是我底层呢,每每心中骂娘,系统中很可能就存在耦合。
如何解耦呢?
业务代码上浮,通用代码下沉,服务化彻底。
解决方案并不复杂,分层架构中,每一层都有自己的职责,每一层都应该守住自己的底线。
你在做技术方案时,碰到过这种场景吗?
“放在你那边做代码少”
“放在你那边做时间短”
作为设计折衷的理由,而要多问:
“怎么做合理”
业务代码上浮,通用代码下沉,服务化彻底,只是一个很小的优化点,但对于底层服务解耦却是非常的有效。
希望大家每天收获一点点,这样架构就能美好一点点。
你在负责底层基础服务时,遇见过
switch case(biz_type)
走不同分支的代码吗?
相关文章:
《我C,一个库里几百个表,这谁受得了?》
《我去,拷贝代码,居然还有这等好处?》
《真的痛,小小的IP,大大的耦合》
《没钱就是没钱,那不是吃苦》
这篇关于明明服务化了,为啥耦合更加严重了?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








