本文主要是介绍软件测试面试题分享,刷完这套八股文,你的offer就稳了,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
把最近朋友及自己遇到的面试题记录下来,并写上自己的答案仅供大家参考,看不懂的可以【点击文末小卡片】,大家一起交流学习。

另外,面试官的问题,大部分都是看你的简历提问,所以大家不用纠结为什么自己没有被问到这些问题,分享这些面试题,只是让大家对照下,自己简历当中是否提到类似的技术,做到有备无患。
在这我为大家准备了一份软件测试视频教程(含面试、接口、自动化、性能测试等),就在下方,需要的可以直接去观看,也可以直接【点击文末小卡片免费领取资料文档】
软件测试视频教程观看处:
2023最新【软件测试面试300问】面试八股文教程,涵盖自动化测试/接口测试/性能测试/测试开发等内容
面试题列表
1.liunx查询日志有哪些命令,筛选关键字怎么筛选?
答:cat、tail 、head、less等等 筛选关键字可以用grep,譬如cat 日志文件 | grep "关键字"。
2.sql删除有两种,知道有什么区别吗?
答:truncat、delete。
truncate和delete的主要区别:
delete是DML,执行delete操作时,每次从表中删除一行,并且同时将该行的的删除操作记录在redo和undo表空间中以便进行回滚(rollback)和重做操作,但要注意表空间要足够大,需要手动提交(commit)操作才能生效,可以通过rollback撤消操作。delete可根据条件删除表中满足条件的数据,如果不指定where子句,那么删除表中所有记录。delete语句不影响表所占用的extent,高水线(high watermark)保持原位置不变。truncate是DDL,会隐式提交,所以,不能回滚,不会触发触发器。truncate会删除表中所有记录,并且将重新设置高水线和所有的索引,缺省情况下将空间释放到minextents个extent,除非使用reuse storage。不会记录日志,所以执行速度很快,但不能通过rollback撤消操作(如果一不小心把一个表truncate掉,也是可以恢复的,只是不能通过rollback来恢复)。对于外键(foreignkey )约束引用的表,不能使用 truncate table,而应使用不带 where 子句的 delete 语句。truncatetable不能用于参与了索引视图的表。
3.sql里 having 和where条件有了解过吗?
having和where 区别
1)一般情况下,WHERE 用于过滤数据行,而 HAVING 用于过滤分组。
2)WHERE 查询条件中不可以使用聚合函数,而 HAVING 查询条件中可以使用聚合函数。
3)WHERE 在数据分组前进行过滤,而 HAVING 在数据分组后进行过滤 。
4)WHERE 针对数据库文件进行过滤,而 HAVING 针对查询结果进行过滤。也就是说,WHERE 根据数据表中的字段直接进行过滤,而 HAVING 是根据前面已经查询出的字段进行过滤。
5)WHERE 查询条件中不可以使用字段别名,而 HAVING 查询条件中可以使用字段别名
4.连表查询知道怎么做吗,左右表连接有什么区别?
左连接和右连接区别为:语法公式不同、基础表不同、结果集不同。
一、语法公式不同
1、左连接:左连接的关键字是left join,语法公式为select *from dave a left join bl b on a .id=b .id。
2、右连接:右连接的关键字是right join,语法公式为select *from dave a right join bl b on a .id=b .id。
二、基础表不同
1、左连接:左连接的基础表为left join左侧数据表。
2、右连接:右连接的基础表为right join右侧数据表。
三、结果集不同
1、左连接:左连接的结果集为left join左侧数据表中的数据,再加上left join左侧与右侧数据表之间匹配的数据。
2、右连接:右连接的结果集为rightjoin右侧数据表中的数据,再加上rightjoin左侧与右侧数据表之间匹配的数据。
5.python定位有哪几种方式?
一,python 常用的8种定位方法1,使用 ID定位 driver.find_element_by _id('ID 值')driver.find_element(by ='id',value ='ID值')2,使用 name定位单个元素 driver.find_element_by_name('name值')driver.find_element(by='name',value='name值')定位多个元素 driver.find_elements_by_name('name值')driver.find_elements(by='name',value='name值')3,使用 class name定位单个元素 driver.find_element_by_class_name('class 属性值')driver.find_element(by='class name',value='class 属性值')定位多个元素 driver.find_elements_by_class_name('class 属性值')driver.find_elements(by='class name',value='class 属性值')4,使用 标签名称定位单个元素 driver.find_element_by_tag_name('标签名称')driver.find_element(by='tag name',value ='标签名称')定位多个元素 driver.find_elements_by_tag_name('标签名称')driver.find_elements(by='tag name',value ='标签名称')5,使用 链接的全部文字定位 driver.find_element_by_link_text('链接全部文字内容')driver.find_element(by='link text',value='链接全部文字内容')定位多个元素 driver.find_elements_by_link_text('链接全部文字内容')driver.find_elements(by='link text',value='链接全部文字内容')6,使用 部分链接文字定位 driver.find_element_by_partial_link_text('链接的部分文字')driver.find_element(by='partial link text',value ='链接的部分文字')定位多个元素 driver.find_elements_by_partial_link_text('链接的部分文字')driver.find_elements(by='partial link text',value ='链接的部分文字')7,使用 XPath 定位 driver.find_element_by_xpath('xpath 定位表达式')driver.find_element(by='xpath',value ='xpath定位表达式')定位多个元素 driver.find_elements_by_xpath('xpath 定位表达式')driver.find_elements(by='xpath',value ='xpath定位表达式')8,使用 CSS方式定位 driver.find_element_by_css_selector('CSS定位表达式')driver.find_elements(by='css selector',value='CSS定位表达式')定位多个元素 driver.find_elements_by_css_selector('CSS定位表达式')driver.find_elements_by_css_selector('CSS定位表达式')二,XPath 定位的必杀技 定位表达式1, 使用绝对路径定位元素 /html/body/div/input[@value = '查询'] 不建议使用2, 使用相对路径定位元素 //input[@value = '查询']3, 使用索引号定位元素 //input[2] //div[last()]/a 最后一个div元素下的a标签 //div[last()-1]/a 倒数第二个div元素下的a标签//div/input[position()<2] div元素下input的位置序列号小于2的input标签4, 使用页面元素多个属性值定位元素 //div[@name='div1' and @value = 'div2']/input[@name='div1input']5, 使用模糊属性值定位元素 //img[starts-with(@alt,'div1')] 查找属性alt的属性值以div1开始的页面元素//img[contains(@alt,'img')] 查找属性alt的属性值包含img 的页面元素6, 使用XPath轴定位元素 //div[@name='div1']/parent::input 查找name属性值为div1的div元素的父级input元素//div[@name='div1']/child::img 查找name属性值为div1的div元素的子级img元素//div[@name='div1']/following::img 查找name属性值为div1的div元素后面的所有img元素 //div[@name='div1']/following-sibling::img 查找name属性值为div1的div元素后面所有兄弟img元素//div[@name='div1']/preceding::img 查找name属性值为div1的div元素前面的所有img元素 //div[@name='div1']/preceding-sibling::img[1] 查找name属性值为div1的div元素前面的所有兄弟中的第一个img元素//div[@name='div1']/ancestor::img 查找name属性值为div1的div元素的所有上级的img元素//div[@name='div1']/descendant::img 查找name属性值为div1的div元素的所有下层的img元素7, 使用页面元素的文本定位元素 //a[contains(text(),'百度')] //a[text()='搜狐']8, 使用XPath 运算符定位元素 //div[a>9] 子元素中有a元素,文本值>9的div元素//div[a<10 and span =13] 子元素中有a元素,文本值>9 同时子元素span文本值=13的div元素6.python_UI自动化,有三个等待方式,知道有什么区别吗?
-
sleep():强制等待,设置固定休眠时间。后脚本的执行过程中执行 sleep()后线程休眠,而另外两种线程不休眠。
-
implicitly_wait():隐式等待,是设置的全局等待。设置等待时间,是对页面中的所有元素设置加载时间,如果超出了设置时间的则抛出异常。隐式等待可以理解成在规定的时间范围内,浏览器在不停的刷新页面,直到找到相关元素或者时间结束。
-
WebDriverWait():显示等待,是针对于某个特定的元素设置的等待时间,在设置时间内,默认每隔一段时间检测一次当前页面某个元素是否存在,如果在规定的时间内找到了元素,则直接执行,即找到元素就执行相关操作,如果超过设置时间检测不到则抛出异常。默认检测频率为0.5s,默认抛出异常为:NoSuchElementException。
7.python里的鼠标悬浮,知道怎么做吗?
定位到要悬停的元素
move = driver.find_element_by_id("xx")
对定位到的元素执行悬停操作
ActionChains(driver).move_to_element(move).perform()8.之前的接口自动化是用什么做的?
9.给你一个普通接口,你会怎么测?
如图:
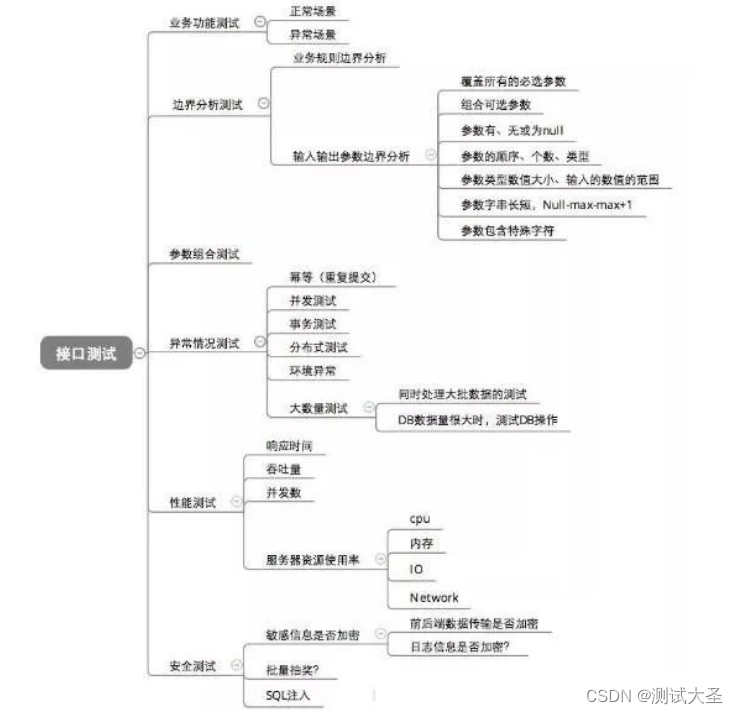
10.第二个项目,说说一下你在里面的工作内容?
基本的功能测试必须说,如果做过自动化、性能或开发提效工具的工作,那就详细说下细节,这是你区别其他应聘者的闪光点,也是你征服面试官,谈薪的资本,即使没有,编也要编一个。
11.你python和java哪个个熟悉一点?
看自己对哪个熟悉吧,建议大家在学习语言的同时,多看看相关的八股文
12.你觉得你有什么优势?
因人而异,特别说明一点,很多人说到自己的优势,无非就是,细心、负责、有耐心,沟通能力好,巴拉巴拉一大堆,我是面试官,我都觉得很假,很恶心。
所以个人建议,大家在说自己的优势的同时,尽量举例说明,而不是干巴巴的猛夸自己。
例如:我个人具备一定的开发水平,特别善于总结项目痛点,运用自己的代码知识,开发过几款提效工具,比如在某某项目中,某某某业务前置流程较长,只能通过模拟用户页面操作,走完前置流程需要10分钟左右,效率比较低。为此,我通过抓包的方式,梳理了这条业务线涉及到的接口、接口之间关联关系、数据流转和相应的数据库、表。通过py或java开发出一款可以自动造数据的工具,测试小伙伴只要调用我的测试工具接口,传入相关的参数,在1分钟左右,就可以造出符合条件的测试数据,大大提高了测试人员造数据的效率。
你看夸自己的同时,还能举例说明,这样才有说服力,才能征服面试官。
最后
PS:这里分享一套软件测试的自学教程合集。对于在测试行业发展的小伙伴们来说应该会很有帮助。除了基础入门的资源,博主也收集不少进阶自动化的资源,从理论到实战,知行合一才能真正的掌握。全套内容已经打包到网盘,内容总量接近500个G。【点击文末小卡片免费领取】

这些资料,对于做【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴我走过了最艰难的路程,希望也能帮助到你!凡事要趁早,特别是技术行业,一定要提升技术功底。
这篇关于软件测试面试题分享,刷完这套八股文,你的offer就稳了的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





