本文主要是介绍大数据学习一之Linux知识,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
大数据学习第一篇(Linux)
文章目录
- 大数据学习第一篇(Linux)
- 前言
- 一、Linux入门
- 1.概述
- 2.Linux与Windows区别
- 3.CentOS下载地址
- 二、VM与Linux的安装
- 1.VMWare安装
- 1)VMware Workstation Pro安装向导
- 2)VMware Workstation安装的许可协议。
- 3)VMware Workstation安装路径。
- 4)VMware Workstation增强型键盘功能。
- 5)VMware Workstation软件检查更新和帮助完善
- 6)VMware Workstation快捷方式。
- 7)VMware Workstation 执行请求。
- 8)VMware Workstation 正在执行请求。
- 9)VMware Workstation 点击许可证。
- 10)VMware Workstation 输入许可证密钥。
- 11)VMware Workstation 安装向导完成
- 2.CentOS安装
- 1)检查BIOS虚拟化支持。
- 2)新建虚拟机
- 3)新建虚拟机向导
- 4)创建虚拟空白光盘
- 5)安装Linux系统对应的CentOS版
- 6)虚拟机命名和定位磁盘位置
- 7)处理器配置,看自己是否是双核、多核
- 8)设置内存为2GB
- 9)网络设置NAT
- 10)选择IO控制器类型
- 11)选择磁盘类型
- 12)新建虚拟磁盘
- 13)设置磁盘容量
- 14)你在哪里存储这个磁盘文件
- 15)新建虚拟机向导配置完成,可以点击自定义硬件配置虚拟机,或点击完成稍后再配置虚拟机。
- 16)VM设置
- 17)加载ISO
- 18)加电并安装配置CentOS
- 19)加电后进入倒计时页面
- 20)CentOS7欢迎页面
- 21)选择简体中文进行安装
- 22)选择语言键盘,日期和时间
- 23)软件选择
- 24)选择自动分区、不启用Kdump、打开以太网,安全方针默认不动
- 25)开始安装,设置root密码
- 26)设置root密码 (一定记住)
- 27)等待安装成功
- 28)安装成功,重启虚拟机
- 29)初始设置
- 30)同意许可协议
- 31)完成配置
- 32)进入欢迎界面
- 33)选择键盘布局
- 34)隐私设置,根据自己喜好选择即可
- 35)确定时区
- 36)跳过关联账号
- 37)CentOS7要求必须设置一个账户
- 38)设置账户密码
- 39)开始使用
- 40)直接关闭下面的界面
- 41)注销当前账户
- 42)使用root账户登录
- 43)登录成功页面
- 三、Linux文件与目录结构
- 1、Linux文件
- 2、Linux目录结构
- 1./bin
- 2./sbin
- 3./home
- 4./root
- 5./lib
- 6./lost+found
- 7./etc
- 8./usr
- 9./boot
- 10./proc
- 11./srv
- 12./sys
- 13./tmp
- 14./dev
- 15./media
- 16./mnt
- 17./opt
- 18./var
- 19./selinux
- 四、VI/VIM编辑器
- 1、VI/VIM编辑器是什么?
- 2、测试数据准备
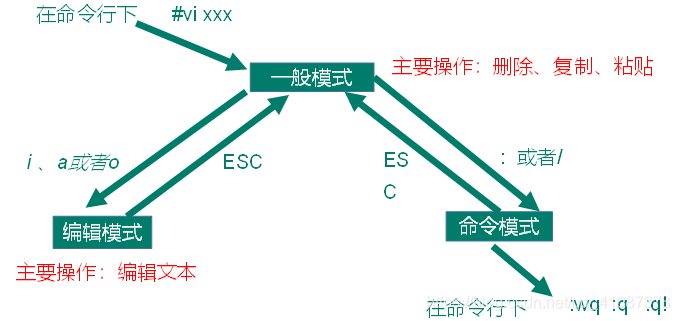
- 3、一般模式
- 4、编辑模式
- 5、命令模式
- 6、模式间转换
- 五、网络配置和系统管理操作
- 1、查看网络IP和网关
- 1)查看虚拟网络编辑器
- 2)修改ip地址
- 3)查看网关
- 4)查看windows环境的中VMnet8网络配置
- 2、配置网络ip地址
- 1)ifconfig 配置网络接口
- 2)ping 测试主机之间网络连通性
- 3)修改IP地址
- 3、配置主机名
- 3.1 hostname 显示和设置系统的主机名称
- 1)基本语法
- 2)案例实操
- 3.2 修改主机名称
- 1)修改linux的主机映射文件(hosts文件)
- 2)修改window7的主机映射文件(hosts文件)
- 3)修改window10的主机映射文件(hosts文件)
- 4、服务管理
- 4.1 临时后台服务管理
- 1)基本语法(CentOS 6)
- 2)基本语法(CentOS 7)
- 3)经验技巧
- 4)案例实操
- 4.2 设置后台服务的自启配置
- 1)基本语法(CentOS 6)
- 2)基本语法(CentOS 7)
- 3)案例实操
- 4.3 进程运行级别
- 5关机重启命令
- 1)基本语法
- 2)经验技巧
- 3)案例实操
- 6 克隆虚拟机
- 1)关闭要被克隆的虚拟机
- 2)找到克隆选项
- 3)欢迎页面
- 4)克隆虚拟机
- 5)设置创建完整克隆
- 6)设置克隆的虚拟机名称和存储位置
- 7)等待正在克隆
- 8)点击关闭,完成克隆
- 9)修改克隆后虚拟机的ip
- 10)修改IP地址
- 11)修改主机名称
- 12)重新启动服务器
- 六、远程登录
- 1 安装Xshell5
- Xshell5安装步骤
- 1)安装Xshell5
- 2)许可类型
- 3)接受许可协议
- 4)输入客户信息
- 5)选择安装路径
- 6)指定安装的目录名,默认即可
- 7)选择语言
- 8)安装进度
- 9)安装完成
- 10)运行界面
- 11)点击新建会话,输入虚拟机ip地址
- 12)点击连接即可通过远程连接虚拟机
- 13)接受并保存
- 14)输入用户名并记住用户名
- 15)输入密码并记住密码
- 16)连接成功
- 17)设置字体大小
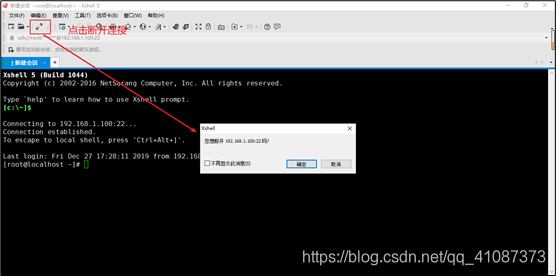
- 18)断开连接
- 19)配置通过Xshel快速连接虚拟机
- 七 常用基本命令
- 1 帮助命令
- 1.1 man 获得帮助信息
- 1.2 help 获得shell内置命令的帮助信息
- 1.3 常用快捷键
- 2 文件目录类
- 2.1 pwd 显示当前工作目录的绝对路径
- 2.2 ls 列出目录的内容
- 2.3 cd 切换目录
- 2.4 mkdir 创建一个新的目录
- 2.5 rmdir 删除一个空的目录
- 2.6 touch 创建空文件
- 2.7 cp 复制文件或目录
- 2.8 rm 移除文件或目录
- 2.9 mv 移动文件与目录或重命名
- 2.10 cat 查看文件内容
- 2.11 more 文件内容分屏查看器
- 2.12 less 分屏显示文件内容
- 2.15 tail 输出文件尾部内容
- 2.16 > 覆盖 和 >> 追加
- 2.17 ln 软链接
- 2.18 history 查看已经执行过历史命令
- 3 时间日期类
- 3.1 date 显示当前时间
- 3.2 date 显示非当前时间
- 3.4 cal 查看日历
- 4 用户管理命令
- 4.1 useradd 添加新用户
- 4.2 passwd 设置用户密码
- 4.3 id 查看用户是否存在
- 4.4 cat /etc/passwd 查看创建了哪些用户
- 4.5 su 切换用户
- 4.6 userdel 删除用户
- 4.7 who 查看登录用户信息
- 4.8 sudo 设置普通用户具有root权限
- 4.9 usermod 修改用户
- 5 用户组管理命令
- 5.1 groupadd 新增组
- 5.2 groupdel 删除组
- 5.3 groupmod 修改组
- 5.4 cat /etc/group 查看创建了哪些组
- 6 文件权限类
- 6.1 文件属性
- 1)从左到右的10个字符表示
- 2)rxw作用文件和目录的不同解释
- 3)案例实操
- 6.2 chmod 改变权限
- 1)基本语法
- 2)经验技巧
- 3)案例实操
- 6.3 chown 改变所有者
- 1)基本语法
- 2)选项说明
- 3)案例实操
- 6.4 chgrp 改变所属组
- 1)基本语法
- 2)案例实操
- 7 搜索查找类
- 7.1 find 查找文件或者目录
- 1)基本语法
- 2)选项说明
- 3)案例实操
- 7.2 grep 过滤查找及“|”管道符
- 1)基本语法
- 2)选项说明
- 3)案例实操
- 7.3 which 查找命令
- 1)基本语法
- 2)案例实操
- 8 压缩和解压类
- 8.1 gzip/gunzip 压缩
- 1)基本语法
- 2)经验技巧
- 3)案例实操
- 8.2 zip/unzip 压缩
- 1)基本语法
- 2)选项说明
- 3)经验技巧
- 4)案例实操
- 8.3 tar 打包
- 1)基本语法
- 2)选项说明
- 3)案例实操
- 9 磁盘分区类
- 9.1 df 查看磁盘空间使用情况
- 1)基本语法
- 2)选项说明
- 3)案例实操
- 9.2 fdisk 查看分区
- 1)基本语法
- 2)选项说明
- 3)经验技巧
- 4)功能说明
- 5)案例实操
- 9.3 mount/umount 挂载/卸载
- 1)挂载前准备(必须要有光盘或者已经连接镜像文件)
- 2)基本语法
- 3)参数说明
- 4)案例实操
- 5)设置开机自动挂载
- 10 进程线程类
- 10.1 ps 查看当前系统进程状态
- 1)基本语法
- 2)选项说明
- 3)功能说明
- 4)经验技巧
- 5)案例实操
- 10.2 kill 终止进程
- 1)基本语法
- 2)选项说明
- 3)案例实操
- 10.3 pstree 查看进程树
- 1)基本语法
- 2)选项说明
- 3)案例实操
- 10.4 top 查看系统健康状态
- 1)基本命令
- 2)选项说明
- 3)操作说明
- 4)查询结果字段解释
- 5)案例实操
- 10.5 netstat 显示网络统计信息和端口占用情况
- 1)基本语法
- 2)选项说明
- 3)案例实操
- 11 crond 系统定时任务
- 11.1 crond 服务管理
- 1)重新启动crond服务
- 11.2 crontab 定时任务设置
- 1)基本语法
- 2)选项说明
- 3)参数说明
- 4)案例实操
- 八 软件包管理
- 1 RPM
- 1.1 RPM概述
- 1.2 RPM查询命令(rpm -qa)
- 1)基本语法
- 2)经验技巧
- 3)案例实操
- 1.3 RPM卸载命令(rpm -e)
- 1)基本语法
- 2)选项说明
- 3)案例实操
- 1.4 RPM安装命令(rpm -ivh)
- 1)基本语法
- 2)选项说明
- 3)案例实操
- 2 YUM仓库配置
- 2.1 YUM概述
- 2.2 YUM的常用命令
- 1)基本语法
- 2)选项说明
- 3)参数说明
- 4)案例实操实操
- 2.3 修改网络YUM源
- 1)前期文件准备
- 2)替换本地yum文件
- 4)测试
- 九 常见错误及解决方案
- 总结
前言
为了伟大祖国的繁荣昌盛,为了提升自己的个人能力(本人菜鸡),所以想在工作的闲余时间把相关大数据的心得整理出来,若有不足的地方,请大家指点。。。一、Linux入门
1.概述
对于Linux操作系统,最初它的内核是由lin纳斯托瓦兹出于爱好编写的,我只能说牛,我什么时候也能写出一个系统。
长话短说吧,Linux是一套免费使用和自由传播的类Unix操作系统,是一个基于Posix和Unix的多用户、多任务、支持多线程和多Cpu的操作系统。Linux能运行主要的Unix工具软件、应用程序和网络协议。它支持32位和64位的硬件。Linux继承了以网络为核心的设计思想,是一个性能稳定的多用户网络操作系统。
目前市场上主要的知名发行版本主要有:Ubuntu、RedHat、CentOs、Debain等
2.Linux与Windows区别
该区别主要涉及到费用、软件与支持、安全性、使用习惯上、可定制性以及应用场景等方面来说
对于费用来说,大家都知道Windows是要收费的,但是也可以通过其他方式,嘿嘿,这边就不方便说了,如果想学习怎么安装比较纯净的,这边有相应的*视频链接*。而Linux呢免费的,但定制的肯定是要收取相应的费用的。
对于软件与支持,windows的数量和质量的优势,不过大部分为收费软件,由微软官方提供支持和服务。而Linux是开源的自由软件(当然大家也可以多为开源共享出一份力),用户可以修改定制和再发布,由于基本免费没有资金支持,部分软件质量和体验有所欠缺;由全球所有的Linux开发者和自由软件社区提供支持。
对于安全性,Linux相对于Windows来说更加安全点。
对于使用习惯上面来说,windows上手简单,满足普通用户的使用,而Linux相对而言比较难一点,但是工作效率比较高。
对于可定制性来说,windows系统封闭的,可定制性差,而Linux开源,可定制性高。
对于应用场景,桌面操作系统主要使用的是Window,而支持百度,淘宝等应用软件和服务的是成千上万台Linux服务器主机。
3.CentOS下载地址
网易镜像
搜狐镜像1
搜狐镜像2
二、VM与Linux的安装
1.VMWare安装
1)VMware Workstation Pro安装向导

2)VMware Workstation安装的许可协议。
3)VMware Workstation安装路径。

4)VMware Workstation增强型键盘功能。

5)VMware Workstation软件检查更新和帮助完善

6)VMware Workstation快捷方式。

7)VMware Workstation 执行请求。

8)VMware Workstation 正在执行请求。

9)VMware Workstation 点击许可证。
10)VMware Workstation 输入许可证密钥。

11)VMware Workstation 安装向导完成
2.CentOS安装
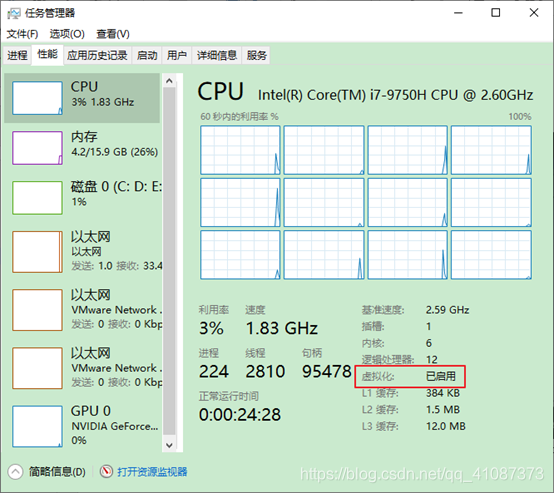
1)检查BIOS虚拟化支持。
2)新建虚拟机

3)新建虚拟机向导
4)创建虚拟空白光盘

5)安装Linux系统对应的CentOS版
6)虚拟机命名和定位磁盘位置
7)处理器配置,看自己是否是双核、多核

8)设置内存为2GB

9)网络设置NAT

10)选择IO控制器类型
11)选择磁盘类型

12)新建虚拟磁盘

13)设置磁盘容量

14)你在哪里存储这个磁盘文件
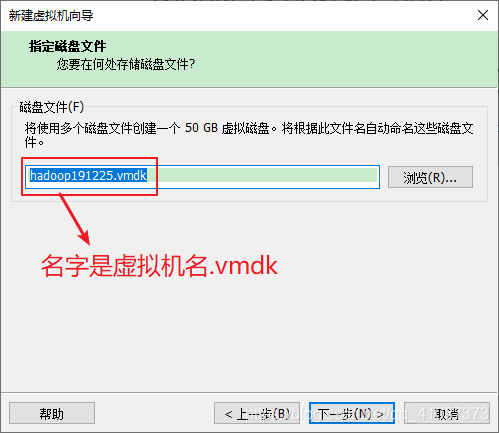
15)新建虚拟机向导配置完成,可以点击自定义硬件配置虚拟机,或点击完成稍后再配置虚拟机。

16)VM设置

17)加载ISO
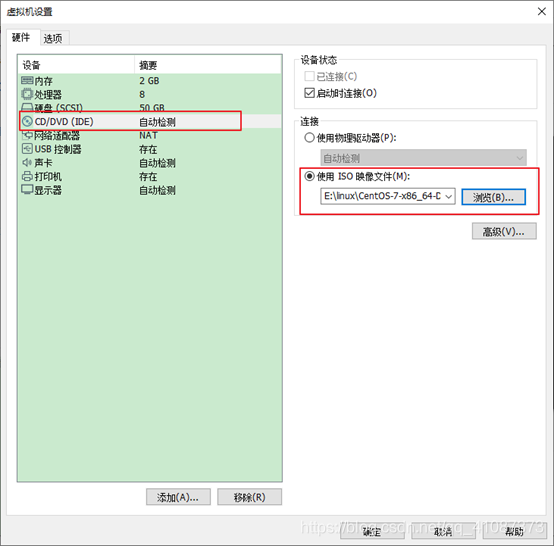
18)加电并安装配置CentOS
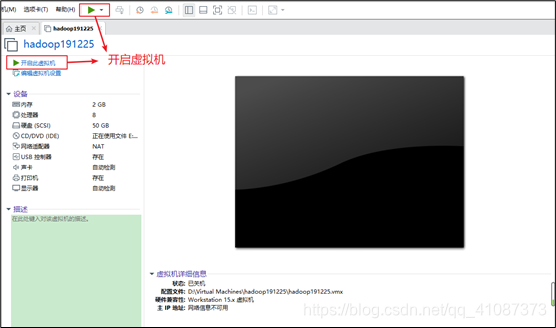
19)加电后进入倒计时页面

点击进入虚拟机屏幕,回车。此外,在Ctrl+Alt可以实现Windows主机和VM之间窗口的切换
20)CentOS7欢迎页面

21)选择简体中文进行安装

22)选择语言键盘,日期和时间
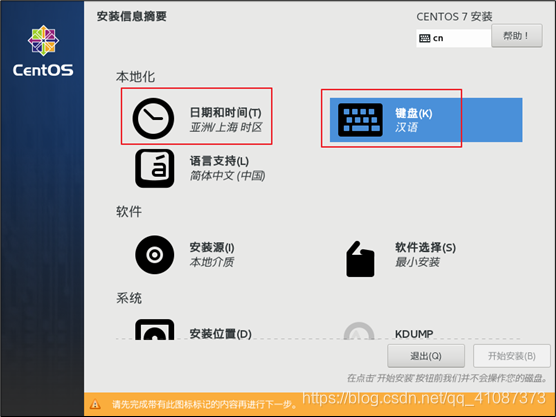
23)软件选择

当然你也可以选择最小安装,就没有图形话界面,这个会在后期文章补充
24)选择自动分区、不启用Kdump、打开以太网,安全方针默认不动

25)开始安装,设置root密码

26)设置root密码 (一定记住)
27)等待安装成功
28)安装成功,重启虚拟机
29)初始设置

30)同意许可协议

31)完成配置

32)进入欢迎界面

33)选择键盘布局
34)隐私设置,根据自己喜好选择即可

35)确定时区
36)跳过关联账号

37)CentOS7要求必须设置一个账户
38)设置账户密码
39)开始使用

40)直接关闭下面的界面
41)注销当前账户

42)使用root账户登录
43)登录成功页面

三、Linux文件与目录结构
1、Linux文件
Linux系统中一切皆文件。
2、Linux目录结构
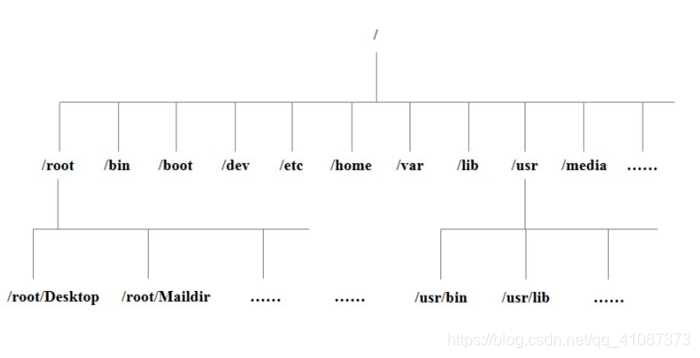
1./bin
是Binary的缩写,这个目录存放着经常使用的命令
2./sbin
s是Super User的意思,这里存放着系统管理员使用的系统管理程序
3./home
home存放普通用户的主目录,在Linux中每个用户都有一个自己的目录,一般该目录名是以用户的账号命名的
4./root
该目录为系统管理员,也称为超级权限者的用户主目录
5./lib
系统开机所需要最基本的动态连接共享库,他的作用类似于Windows里的dll文件。几乎所有的应用程序都需要用到这些共享库
6./lost+found
这个目录一般情况下是空的,当系统非法关机后,这里就存放了一些文件
7./etc
所有的系统管理所需要的配置文件和子目录
8./usr
这是一个非常重要的目录,用户的很多应用程序和文件都放在这个目录下,类似于windows下的Program files目录
9./boot
这里存放的是启动Linux时用到的一些核心文件,包括一些连接文件以及镜像文件,自己的安装不能放在这个里面
10./proc
这个目录是一个虚拟的目录,它是系统内存的映射,我们可以通过直接访问这个目录来获取系统信息
11./srv
service缩写,该目录存放一些服务启动之后需要提取的数据
12./sys
这是Linux2.6内核的一个很大的变化。该目录下安装了2.6内核中新出现的一个文件系统sysfs
13./tmp
这个目录是存放一些临时文件的
14./dev
类似于windows的设备管理器,把所有的硬件用文件的形式进行存储
15./media
Linux系统会自动识别一些设备,例如U盘,光驱等等,当识别后,Linux会把识别的设备挂载到该目录下
16./mnt
系统提供该目录是为了让用户临时挂载别的文件系统的,我们可以将外部的存储挂载在/mnt/上,然后进入该目录就可以查看里面的内容了
17./opt
这是给主机额外安装软件所摆放的目录。比如你安装了一个mysql数据库则就可以放到这个目录下。默认是空的
18./var
这个目录中存放着不断扩充着的东西,我们习惯将那些经常被修改的目录放在这个目录下。包括各种日志文件。
19./selinux
SELinux是一种安全子系统,它能控制程序只能访问特定文件
四、VI/VIM编辑器
1、VI/VIM编辑器是什么?
VI是Unix操作系统和类Unix操作系统中最通用的文本编辑器。
VIM编辑器是从VI发展出来的一个性能更强大的文本编辑器。可以主动的以字体颜色辨别语法的正确性,方便程序设计。VIM与VI编辑器完全不兼容。
2、测试数据准备
拷贝/etc/smartmontools/smartd.conf数据到/root目录下
代码如下(示例):
[root@hadoop100 桌面]# cp /etc/smartmontools/smartd.conf /root
[root@hadoop100 桌面]# cd /root/
3、一般模式
以vi/vim打开一个档案就直接进入一般模式了(这是默认的模式)。在这个模式中, 你可以使用『上下左右』按键来移动光标,你可以使用『删除字符』或『删除整行』来处理档案内容, 也可以使用『复制、贴上』来处理你的文件数据。
常用语法
1.yy
复制光标当前一行
2.y数字y
复制一段(从第几行到第几行)
3.p
箭头移动到目的行粘贴
4.u
撤销上一步
5.dd
删除光标当前行
6.d数字d
删除光标(含)后多少行
7.x
删除一个字母,相当于del,向后删
8.X
删除一个字母,相当于Backspace,向前删
9.yw
复制一个词
10.dw
删除一个词
11.^
移动到行头
12.$
移动到行尾
13.gg或者1+G
移动到页头
14.G
移动到页尾
15.数字+G(先输入数字,在按G)
移动到目标行
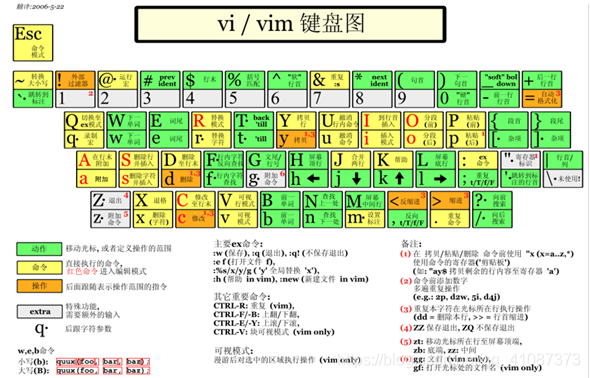
4、编辑模式
在一般模式中可以进行删除、复制、粘贴等的动作,但是无法编辑文件内容!要等到你按下『i, I, o, O, a, A』等任何一个字母之后才会进入编辑模式。
注意了!通常在Linux中,按下这些按键时,在画面的左下方会出现『INSERT或 REPLACE』的字样,此时才可以进行编辑。而如果要回到一般模式时, 则必须要按下『Esc』这个按键即可退出编辑模式。
1)进入编辑模式
1.i
当前光标前
2.a
当前光标后
3.o
当前光标行的下一行
4.I
光标所在行最前
5.A
光标所在行最后
6.O
当前光标行的上一行
2)退出编辑模式
按『Esc』键
5、命令模式
在一般模式当中,输入『 : / ?』3个中的任何一个按钮,就可以将光标移动到最底下那一行。
在这个模式当中, 可以提供你『搜寻资料』的动作,而读取、存盘、大量取代字符、离开 vi 、显示行号等动作是在此模式中达成的!
1)基本语法
- :w
保存 - :q
退出 - :!
强制执行 - : %s/old字符/new字符
批量替换 - / 要查找的词
n 查找下一个,N 往上查找 - ? 要查找的词
n是查找上一个,N是往下查找 - :set nu
显示行号 - :set nonu
关闭行号 - ZZ(shift+zz) :nohl
没有修改文件直接退出,如果修改了文件保存后退
去除高亮显示
2)案例实操
(1)强制保存退出
:wq!
6、模式间转换
五、网络配置和系统管理操作
1、查看网络IP和网关
1)查看虚拟网络编辑器
2)修改ip地址

3)查看网关
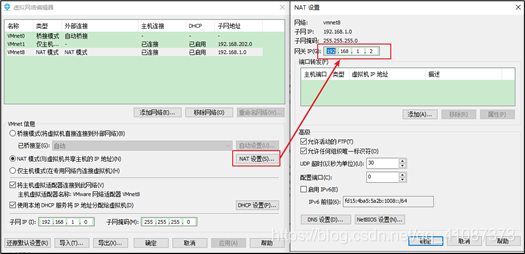
4)查看windows环境的中VMnet8网络配置
2、配置网络ip地址
1)ifconfig 配置网络接口
ifconfig :network interfaces configuring网络接口配置
<1>基本语法
ifconfig (功能描述:显示所有网络接口的配置信息)
<2>案例实操
(1)查看当前网络ip
[root@hadoop100 桌面]# ifconfig
2)ping 测试主机之间网络连通性
<1>基本语法
ping 目的主机 (功能描述:测试当前服务器是否可以连接目的主机)
<2>案例实操
(1)测试当前服务器是否可以连接百度
[root@hadoop100 桌面]# ping www.baidu.com
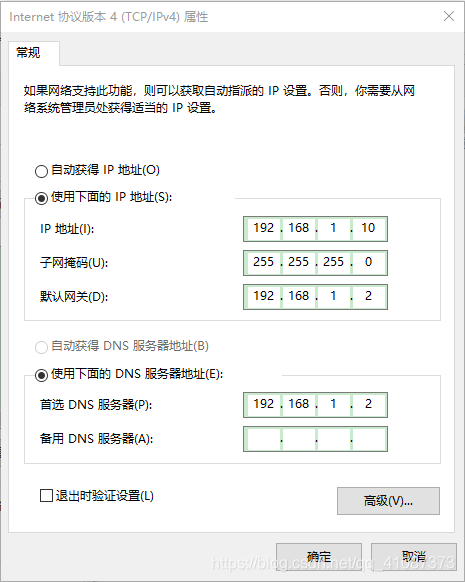
3)修改IP地址
<1>修改IP地址
[root@hadoop100 桌面]#
vim /etc/sysconfig/network-scripts/ifcfg-ens33
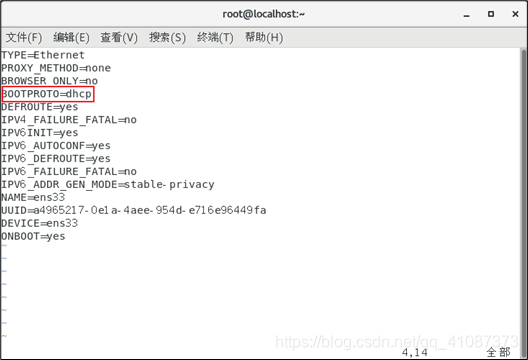
以下标红的项必须修改,有值的按照下面的值修改,没有该项的要增加。
#IP的配置方法[none|static|bootp|dhcp](引导时不使用协议|静态分配IP|BOOTP协议|DHCP协议)
BOOTPROTO=static
#IP地址
IPADDR=192.168.1.100
#网关
GATEWAY=192.168.1.2
#域名解析器
DNS1=192.168.1.2
修改后,如下图所示
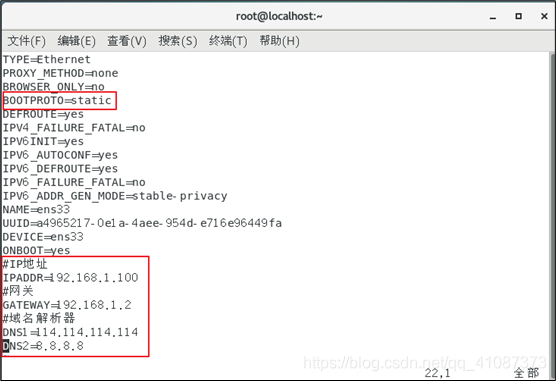
:wq 保存退出
<2>执行service network restart

<3>如果报错,reboot,重启虚拟机
3、配置主机名
3.1 hostname 显示和设置系统的主机名称
1)基本语法
hostname (功能描述:查看当前服务器的主机名称)
2)案例实操
(1)查看当前服务器主机名称
[root@hadoop100 桌面]# hostname
3.2 修改主机名称
1)修改linux的主机映射文件(hosts文件)
(1)进入Linux系统查看本机的主机名。通过hostname命令查看
[root@hadoop100 桌面]# hostname
hadoop100
(2)如果感觉此主机名不合适,我们可以进行修改。通过编辑/etc/hostname文件
[root@hadoop100 桌面]# vim /etc/hostname
文件中内容
localhost.localdomain
(3)打开此文件后,可以看到主机名。修改此主机名为我们想要修改的主机名hadoop100。
(4)保存退出。
(5)打开/etc/hosts
[root@hadoop100 桌面]# vim /etc/hosts
添加如下内容
192.168.1.100 hadoop100
192.168.1.101 hadoop101
192.168.1.102 hadoop102
192.168.1.103 hadoop103
192.168.1.104 hadoop104
192.168.1.105 hadoop105
192.168.1.106 hadoop106
192.168.1.107 hadoop107
192.168.1.108 hadoop108
(6)并重启设备,重启后,查看主机名,已经修改成功
2)修改window7的主机映射文件(hosts文件)
(1)进入C:\Windows\System32\drivers\etc路径
(2)打开hosts文件并添加如下内容
192.168.1.100 hadoop100
192.168.1.101 hadoop101
192.168.1.102 hadoop102
192.168.1.103 hadoop103
192.168.1.104 hadoop104
192.168.1.105 hadoop105
192.168.1.106 hadoop106
192.168.1.107 hadoop107
192.168.1.108 hadoop108
3)修改window10的主机映射文件(hosts文件)
(1)进入C:\Windows\System32\drivers\etc路径
(2)拷贝hosts文件到桌面
(3)打开桌面hosts文件并添加如下内容
192.168.1.100 hadoop100
192.168.1.101 hadoop101
192.168.1.102 hadoop102
192.168.1.103 hadoop103
192.168.1.104 hadoop104
192.168.1.105 hadoop105
192.168.1.106 hadoop106
192.168.1.107 hadoop107
192.168.1.108 hadoop108
(4)将桌面hosts文件覆盖C:\Windows\System32\drivers\etc路径hosts文件
4、服务管理
4.1 临时后台服务管理
1)基本语法(CentOS 6)
service 服务名 start (功能描述:开启服务)
service 服务名 stop (功能描述:关闭服务)
service 服务名 restart (功能描述:重新启动服务)
service 服务名 status (功能描述:查看服务状态)
2)基本语法(CentOS 7)
systemctl start 服务名 (功能描述:开启服务)
systemctle stop 服务名 (功能描述:关闭服务)
systemctl restart 服务名 (功能描述:重新启动服务)
systemctl status 服务名 (功能描述:查看服务状态)
systemctl --type service (功能描述:查看正在运行的服务)
3)经验技巧
查看服务的方法:/usr/lib/systemd/system
4)案例实操
(1)查看网络服务的状态
[root@hadoop100 桌面]#systemctl status network
(2)停止网络服务
[root@hadoop100 桌面]#systemctl stop network
(3)启动网络服务
[root@hadoop100 桌面]#systemctl start network
(4)重启网络服务
[root@hadoop100 桌面]#systemctl restart network
4.2 设置后台服务的自启配置
1)基本语法(CentOS 6)
chkconfig (功能描述:查看所有服务器自启配置)
chkconfig 服务名 off (功能描述:关掉指定服务的自动启动)
chkconfig 服务名 on (功能描述:开启指定服务的自动启动)
chkconfig 服务名 --list (功能描述:查看服务开机启动状态)
2)基本语法(CentOS 7)
systemctl list-unit-files (功能描述:查看所有服务器自启配置)
systemctl disable 服务名 (功能描述:关掉指定服务的自动启动)
systemctl enable 服务名 (功能描述:开启指定服务的自动启动)
systemctl is-enabled 服务名(功能描述:查看服务开机启动状态)
3)案例实操
(1)关闭防火墙的自动启动
[root@hadoop100 桌面]#system disable firewalld
(2)开启防火墙的自动启动
[root@hadoop100 桌面]#system enable firewalld
(3)查看防火墙状态
[root@hadoop100桌面]#systemctl is-enabled firewalld
4.3 进程运行级别
运行级别:开机——》BIOS——》/boot——》init进程——》运行级别——》运行级别对应的服务
查看默认级别:vi/etc/inittab
Linux系统有7种运行级别(runlevel):常用的是级别3和5
运行级别0:系统停机状态,系统默认运行级别不能设为0,否则不能正常启动
运行级别1:单用户工作状态,root权限,用于系统维护,禁止远程登录
运行级别2:多用户状态(没有NFS),不支持网络
运行级别3:完全的多用户状态(有NFS),登陆后进入控制台命令行模式
运行级别4:系统未使用,保留
运行级别5:X11控制台,登陆后进入图形GUI模式
运行级别6:系统正常关闭和重启,默认运行级别不能设为6,否则不能正常启动
5关机重启命令
在linux领域内大多用在服务器上,很少遇到关机的操作。毕竟服务器上跑一个服务是永无止境的,除非特殊情况下,不得已才会关机。
正确的关机流程为:sync > shutdown > reboot >poweroff
1)基本语法
(1)sync (功能描述:将数据由内存同步到硬盘中)
(2)poweroff (功能描述:关闭系统,等同于shutdown -h now)
(3)reboot (功能描述:就是重启,等同于 shutdown -r now)
(4)shutdown [选项] 时间
表1-4
| 参数 | 功能 |
|---|---|
| -h | -h=halt关机 |
| -r | -r=reboot重启 |
表1-5
| 选项 | 功能 |
|---|---|
| now | 立刻关机 |
| 时间 | 等待多久后关机(时间单位是分钟) |
2)经验技巧
Linux系统中为了提高磁盘的读写效率,对磁盘采取了 “预读迟写”操作方式。当用户保存文件时,Linux核心并不一定立即将保存数据写入物理磁盘中,而是将数据保存在缓冲区中,等缓冲区满时再写入磁盘,这种方式可以极大的提高磁盘写入数据的效率。但是,也带来了安全隐患,如果数据还未写入磁盘时,系统掉电或者其他严重问题出现,则将导致数据丢失。使用sync指令可以立即将缓冲区的数据写入磁盘。
3)案例实操
(1)将数据由内存同步到硬盘中
[root@hadoop100桌面]#sync
(2)重启
[root@hadoop100桌面]# reboot
(3)关机
[root@hadoop100桌面]#poweroff
(4)计算机将在1分钟后关机,并且会显示在登录用户的当前屏幕中
[root@hadoop100桌面]#shutdown -h 1 ‘This server will shutdown after 1 mins’
(5)立马关机(等同于 halt)
[root@hadoop100桌面]# shutdown -h now
(6)系统立马重启(等同于 reboot)
[root@hadoop100桌面]# shutdown -r now
6 克隆虚拟机
1)关闭要被克隆的虚拟机
2)找到克隆选项

3)欢迎页面

4)克隆虚拟机

5)设置创建完整克隆

6)设置克隆的虚拟机名称和存储位置

7)等待正在克隆

8)点击关闭,完成克隆

9)修改克隆后虚拟机的ip
[root@hadoop101 /]#
vim /etc/udev/rules.d/70-persistent-net.rules
进入如下页面,删除eth0该行;将eth1修改为eth0,同时复制物理ip地址,如下图,修改网卡。

10)修改IP地址
[root@hadoop101 /]#vim /etc/sysconfig/network-scripts/ifcfg-eth0
(1)把复制的物理ip地址更新
HWADDR=00:0C:2x:6x:0x:xx #MAC地址
(2)修改成你想要的ip
IPADDR=192.168.1.101 #IP地址
11)修改主机名称
12)重新启动服务器
六、远程登录
1 安装Xshell5
Linux远程登录及相关工具介绍
Linux一般作为服务器使用,而服务器一般放在机房,你不可能在机房操作你的Linux服务器。这时我们就需要远程登录到Linux服务器来管理维护系统。
Linux系统中是通过SSH服务实现的远程登录功能,默认ssh服务端口号为 22。Window系统上 Linux 远程登录客户端有SecureCRT, Putty, SSH Secure Shell,XShell等
Xshell5安装步骤
1)安装Xshell5
2)许可类型

3)接受许可协议
4)输入客户信息
5)选择安装路径
6)指定安装的目录名,默认即可
7)选择语言

8)安装进度
9)安装完成
10)运行界面

11)点击新建会话,输入虚拟机ip地址
12)点击连接即可通过远程连接虚拟机
13)接受并保存

14)输入用户名并记住用户名

15)输入密码并记住密码

16)连接成功

17)设置字体大小

18)断开连接
19)配置通过Xshel快速连接虚拟机
(1)修改/etc/ssh/sshd_config的配置文件

(2)将122行的#号去掉,将yes改为no
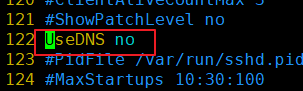
(3)重启虚拟机
reboot
七 常用基本命令
1 帮助命令
1.1 man 获得帮助信息
1)基本语法
man [命令或配置文件] (功能描述:获得帮助信息)
2)显示说明
表1-6
| 信息 | 功能 |
|---|---|
| NAME | 命令的名称和单行描述 |
| SYNOPSIS | 怎样使用命令 |
| DESCRIPTION | 命令功能的深入讨论 |
| EXAMPLES | 怎样使用命令的例子 |
| SEE ALSO | 相关主题(通常是手册页) |
3)案例实操
(1)查看ls命令的帮助信息
[root@hadoop101 ~]# man ls
1.2 help 获得shell内置命令的帮助信息
1)基本语法
help 命令 (功能描述:获得shell内置命令的帮助信息)
2)案例实操
(1)查看cd命令的帮助信息
[root@hadoop101 ~]# help cd
1.3 常用快捷键
表1-7 常用快捷键
| 常用快捷键 | 功能 |
|---|---|
| ctrl + c | 停止进程 |
| ctrl+l | 清屏;彻底清屏是:reset |
| ctrl + q | 退出 |
| 善于用tab键 | 提示(更重要的是可以防止敲错) |
| 上下键 | 查找执行过的命令 |
| ctrl +alt | linux和Windows之间切换 |
2 文件目录类
2.1 pwd 显示当前工作目录的绝对路径
pwd:print working directory 打印工作目录
1)基本语法
pwd (功能描述:显示当前工作目录的绝对路径)
2)案例实操
(1)显示当前工作目录的绝对路径
[root@hadoop101 ~]# pwd
/root
2.2 ls 列出目录的内容
ls:list 列出目录内容
1)基本语法
ls [选项] [目录或是文件]
2)选项说明
表1-8 选项说明
| 选项 | 功能 |
|---|---|
| -a | 全部的文件,连同隐藏档( 开头为 . 的文件) 一起列出来(常用) |
| -l | 长数据串列出,包含文件的属性与权限等等数据;(常用) |
3)显示说明
每行列出的信息依次是: 文件类型与权限 链接数 文件属主 文件属组 文件大小用byte来表示 建立或最近修改的时间 名字
4)案例实操
(1)查看当前目录的所有内容信息
[doubi@hadoop101 ~]$ ls -al
总用量 44
drwx------. 5 doubi doubi 4096 5月 27 15:15 .
drwxr-xr-x. 3 root root 4096 5月 27 14:03 ..
drwxrwxrwx. 2 root root 4096 5月 27 14:14 hello
-rwxrw-r--. 1 doubi doubi 34 5月 27 14:20 test.txt
2.3 cd 切换目录
cd:Change Directory切换路径
1)基本语法
cd [参数]
2)参数说明
表1-9 参数说明
| 参数 | 功能 |
|---|---|
| cd 绝对路径 | 切换路径 |
| cd相对路径 | 切换路径 |
| cd ~或者cd | 回到自己的家目录 |
| cd - | 回到上一次所在目录 |
| cd … | 回到当前目录的上一级目录 |
| cd -P | 跳转到实际物理路径,而非快捷方式路径 |
3)案例实操
(1)使用绝对路径切换到root目录
[root@hadoop101 ~]# cd /root/
(2)使用相对路径切换到“公共的”目录
[root@hadoop101 ~]# cd 公共的/
(3)表示回到自己的家目录,亦即是 /root 这个目录
[root@hadoop101 公共的]# cd ~
(4)cd- 回到上一次所在目录
[root@hadoop101 ~]# cd -
(5)表示回到当前目录的上一级目录,亦即是 “/root/公共的”的上一级目录的意思;
[root@hadoop101 公共的]# cd ..
2.4 mkdir 创建一个新的目录
mkdir:Make directory 建立目录
1)基本语法
mkdir [选项] 要创建的目录
2)选项说明
表1-10 选项说明
| 选项 | 功能 |
|---|---|
| -p | 创建多层目录 |
3)案例实操
(1)创建一个目录
[root@hadoop101 ~]# mkdir xiyou
[root@hadoop101 ~]# mkdir xiyou/mingjie
(2)创建一个多级目录
[root@hadoop101 ~]# mkdir -p xiyou/dssz/meihouwang
2.5 rmdir 删除一个空的目录
rmdir:Remove directory 移动目录
1)基本语法:
rmdir 要删除的空目录
2)案例实操
(1)删除一个空的文件夹
[root@hadoop101 ~]# rmdir xiyou/dssz/meihouwang
2.6 touch 创建空文件
1)基本语法
touch 文件名称
2)案例实操
[root@hadoop101 ~]# touch xiyou/dssz/sunwukong.txt
2.7 cp 复制文件或目录
1)基本语法
cp [选项] source dest (功能描述:复制source文件到dest)
2)选项说明
表1-11 选项说明
| 选项 | 功能 |
|---|---|
| -r | 递归复制整个文件夹 |
3)参数说明
表1-12 参数说明
| 参数 | 功能 |
|---|---|
| source | 源文件 |
| dest | 目标文件 |
4)经验技巧
强制覆盖不提示的方法:\cp
5)案例实操
(1)复制文件
[root@hadoop101 ~]# cp xiyou/dssz/suwukong.txt xiyou/mingjie/
(2)递归复制整个文件夹
[root@hadoop101 ~]# cp -r xiyou/dssz/ ./
2.8 rm 移除文件或目录
1)基本语法
rm [选项] deleteFile (功能描述:递归删除目录中所有内容)
2)选项说明
表1-13 选项说明
| 选项 | 功能 |
|---|---|
| -r | 递归删除目录中所有内容 |
| -f | 强制执行删除操作,而不提示用于进行确认。 |
| -v | 显示指令的详细执行过程 |
3)案例实操
(1)删除目录中的内容
[root@hadoop101 ~]# rm xiyou/mingjie/sunwukong.txt
(2)递归删除目录中所有内容
[root@hadoop101 ~]# rm -rf dssz/
2.9 mv 移动文件与目录或重命名
1)基本语法
(1)mv oldNameFile newNameFile (功能描述:重命名)
(2)mv /temp/movefile /targetFolder (功能描述:移动文件)
2)案例实操
(1)重命名
[root@hadoop101 ~]# mv xiyou/dssz/suwukong.txt xiyou/dssz/houge.txt
(2)移动文件
[root@hadoop101 ~]# mv xiyou/dssz/houge.txt ./
2.10 cat 查看文件内容
查看文件内容,从第一行开始显示。
1)基本语法
cat [选项] 要查看的文件
2)选项说明
表1-14
| 选项 | 功能描述 |
|---|---|
| -n | 显示所有行的行号,包括空行。 |
3)经验技巧
一般查看比较小的文件,一屏幕能显示全的。
4)案例实操
(1)查看文件内容并显示行号
[doubi@hadoop101 ~]$ cat -n houge.txt
2.11 more 文件内容分屏查看器
more指令是一个基于VI编辑器的文本过滤器,它以全屏幕的方式按页显示文本文件的内容。more指令中内置了若干快捷键,详见操作说明。
1)基本语法
more 要查看的文件
2)操作说明
表1-15 操作说明
| 操作 | 功能说明 |
|---|---|
| 空白键 (space) | 代表向下翻一页; |
| Enter | 代表向下翻『一行』; |
| q | 代表立刻离开 more ,不再显示该文件内容。 |
| Ctrl+F | 向下滚动一屏 |
| Ctrl+B | 返回上一屏 |
| = | 输出当前行的行号 |
| :f | 输出文件名和当前行的行号 |
3)案例实操
(1)采用more查看文件
[root@hadoop101 ~]# more smartd.conf
2.12 less 分屏显示文件内容
less指令用来分屏查看文件内容,它的功能与more指令类似,但是比more指令更加强大,支持各种显示终端。less指令在显示文件内容时,并不是一次将整个文件加载之后才显示,而是根据显示需要加载内容,对于显示大型文件具有较高的效率。
1)基本语法
less 要查看的文件
2)操作说明
表1-16 操作说明
| 操作 | 功能说明 |
|---|---|
| 空白键 | 向下翻动一页; |
| [pagedown] | 向下翻动一页 |
| [pageup] | 向上翻动一页; |
| /字串 | 向下搜寻『字串』的功能;n:向下查找;N:向上查找; |
| ?字串 | 向上搜寻『字串』的功能;n:向上查找;N:向下查找; |
| q | 离开 less 这个程序; |
3)案例实操
(1)采用less查看文件
[root@hadoop101 ~]# less smartd.conf
7.2.13 echo
echo输出内容到控制台
1)基本语法
echo [选项] [输出内容]
选项:
-e: 支持反斜线控制的字符转换
| 控制字符 | 作用 |
|---|---|
| \\ | 输出\本身 |
| \n | 换行符 |
| \t | 制表符,也就是Tab键 |
2)案例实操
[doubi@hadoop101 ~]$ echo "hello\tworld"
hello\tworld
[doubi@hadoop101 ~]$ echo -e "hello\tworld"
hello world
7.2.14 head 显示文件头部内容
head用于显示文件的开头部分内容,默认情况下head指令显示文件的前10行内容。
1)基本语法
head 文件 (功能描述:查看文件头10行内容)
head -n 5 文件 (功能描述:查看文件头5行内容,5可以是任意行数)
2)选项说明
表1-18
| 选项 | 功能 |
|---|---|
| -n <行数> | 指定显示头部内容的行数 |
3)案例实操
(1)查看文件的头2行
[root@hadoop101 ~]# head -n 2 smartd.conf
2.15 tail 输出文件尾部内容
tail用于输出文件中尾部的内容,默认情况下tail指令显示文件的后10行内容。
1)基本语法
(1)tail 文件 (功能描述:查看文件后10行内容)
(2)tail -n 5 文件 (功能描述:查看文件后5行内容,5可以是任意行数)
(3)tail -f 文件 (功能描述:实时追踪该文档的所有更新)
2)选项说明
表1-19
| 选项 | 功能 |
|---|---|
| -n<行数> | 输出文件尾部n行内容 |
| -f | 显示文件最新追加的内容,监视文件变化 |
3)案例实操
(1)查看文件头1行内容
[root@hadoop101 ~]# tail -n 1 smartd.conf
(2)实时追踪该档的所有更新
[root@hadoop101 ~]# tail -f houge.txt
2.16 > 覆盖 和 >> 追加
1)基本语法
(1)ll >文件 (功能描述:列表的内容写入文件a.txt中(覆盖写))
(2)ll >>文件 (功能描述:列表的内容追加到文件aa.txt的末尾)
(3)cat 文件1 > 文件2 (功能描述:将文件1的内容覆盖到文件2)
(4)echo “内容” >> 文件
2)案例实操
(1)将ls查看信息写入到文件中
[root@hadoop101 ~]# ls -l>houge.txt
(2)将ls查看信息追加到文件中
[root@hadoop101 ~]# ls -l>>houge.txt
(3)采用echo将hello单词追加到文件中
[root@hadoop101 ~]# echo hello>>houge.txt
2.17 ln 软链接
软链接也成为符号链接,类似于windows里的快捷方式,有自己的数据块,主要存放了链接其他文件的路径。
1)基本语法
ln -s [原文件或目录] [软链接名] (功能描述:给原文件创建一个软链接)
2)经验技巧
删除软链接: rm -rf 软链接名,而不是rm -rf 软链接名/
查询:通过ll就可以查看,列表属性第1位是l,尾部会有位置指向。
3)案例实操
(1)创建软连接
[root@hadoop101 ~]# mv houge.txt xiyou/dssz/
[root@hadoop101 ~]# ln -s xiyou/dssz/houge.txt ./houzi
[root@hadoop101 ~]# ll
lrwxrwxrwx. 1 root root 20 6月 17 12:56 houzi -> xiyou/dssz/houge.txt
(2)删除软连接
[root@hadoop101 ~]# rm -rf houzi
(3)进入软连接实际物理路径
[root@hadoop101 ~]# ln -s xiyou/dssz/ ./dssz
[root@hadoop101 ~]# cd -P dssz/
2.18 history 查看已经执行过历史命令
1)基本语法
history (功能描述:查看已经执行过历史命令)
2)案例实操
(1)查看已经执行过的历史命令
[root@hadoop101 test1]# history
3 时间日期类
1)基本语法
date [OPTION]… [+FORMAT]
2)选项说明
表1-20
| 选项 | 功能 |
|---|---|
| -d<时间字符串> | 显示指定的“时间字符串”表示的时间,而非当前时间 |
| -s<日期时间> | 设置系统日期时间 |
3)参数说明
表1-21
| 参数 | 功能 |
|---|---|
| <+日期时间格式> | 指定显示时使用的日期时间格式 |
3.1 date 显示当前时间
1)基本语法
(1)date (功能描述:显示当前时间)
(2)date +%Y (功能描述:显示当前年份)
(3)date +%m (功能描述:显示当前月份)
(4)date +%d (功能描述:显示当前是哪一天)
(5)date “+%Y-%m-%d %H:%M:%S” (功能描述:显示年月日时分秒)
2)案例实操
(1)显示当前时间信息
[root@hadoop101 ~]# date
2017年 06月 19日 星期一 20:53:30 CST
(2)显示当前时间年月日
[root@hadoop101 ~]# date +%Y%m%d
20170619
(3)显示当前时间年月日时分秒
[root@hadoop101 ~]# date "+%Y-%m-%d %H:%M:%S"
2017-06-19 20:54:58
3.2 date 显示非当前时间
1)基本语法
(1)date -d ‘1 days ago’ (功能描述:显示前一天时间)
(2)date -d ‘-1 days ago’ (功能描述:显示明天时间)
2)案例实操
(1)显示前一天
[root@hadoop101 ~]# date -d '1 days ago'
2017年 06月 18日 星期日 21:07:22 CST
(2)显示明天时间
[root@hadoop101 ~]#date -d '-1 days ago'
2017年 06月 20日 星期日 21:07:22 CST
7.3.3 date 设置系统时间
1)基本语法
date -s 字符串时间
2)案例实操
(1)设置系统当前时间
[root@hadoop101 ~]# date -s "2017-06-19 20:52:18"
3.4 cal 查看日历
1)基本语法
cal [选项] (功能描述:不加选项,显示本月日历)
2)选项说明
表1-22
| 选项 | 功能 |
|---|---|
| 具体某一年 | 显示这一年的日历 |
3)案例实操
(1)查看当前月的日历
[root@hadoop101 ~]# cal
(2)查看2017年的日历
[root@hadoop101 ~]# cal 2017
4 用户管理命令
4.1 useradd 添加新用户
1)基本语法
useradd 用户名 (功能描述:添加新用户)
useradd -g 组名 用户名 (功能描述:添加新用户到某个组)
2)案例实操
(1)添加一个用户
[root@hadoop101 ~]# useradd tangseng
[root@hadoop101 ~]#ll /home/
4.2 passwd 设置用户密码
1)基本语法
passwd 用户名 (功能描述:设置用户密码)
2)案例实操
(1)设置用户的密码
[root@hadoop101 ~]# passwd tangseng
4.3 id 查看用户是否存在
1)基本语法
id 用户名
2)案例实操
(1)查看用户是否存在
[root@hadoop101 ~]#id tangseng
4.4 cat /etc/passwd 查看创建了哪些用户
1)基本语法
[root@hadoop101 ~]# cat /etc/passwd
4.5 su 切换用户
su: swith user 切换用户
1)基本语法
su 用户名称 (功能描述:切换用户,只能获得用户的执行权限,不能获得环境变量)
su - 用户名称 (功能描述:切换到用户并获得该用户的环境变量及执行权限)
2)案例实操
(1)切换用户
[root@hadoop101 ~]#su tangseng
[root@hadoop101 ~]#echo $PATH
/usr/lib64/qt-3.3/bin:/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin
[root@hadoop101 ~]#exit
[root@hadoop101 ~]#su - tangseng
[root@hadoop101 ~]#echo $PATH
/usr/lib64/qt-3.3/bin:/usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/sbin:/home/tangseng/bin
4.6 userdel 删除用户
1)基本语法
(1)userdel 用户名 (功能描述:删除用户但保存用户主目录)
(2)userdel -r 用户名 (功能描述:用户和用户主目录,都删除)
2)选项说明
表1-23
| 选项 | 功能 |
|---|---|
| -r | 删除用户的同时,删除与用户相关的所有文件。 |
3)案例实操
(1)删除用户但保存用户主目录
[root@hadoop101 ~]#userdel tangseng
[root@hadoop101 ~]#ll /home/
(2)删除用户和用户主目录,都删除
[root@hadoop101 ~]#useradd zhubajie
[root@hadoop101 ~]#ll /home/
[root@hadoop101 ~]#userdel -r zhubajie
[root@hadoop101 ~]#ll /home/
4.7 who 查看登录用户信息
1)基本语法
(1)whoami (功能描述:显示自身用户名称)
(2)who am i (功能描述:显示登录用户的用户名)
2)案例实操
(1)显示自身用户名称
[root@hadoop101 opt]# whoami
(2)显示登录用户的用户名
[root@hadoop101 opt]# who am i
4.8 sudo 设置普通用户具有root权限
1)添加doubi用户,并对其设置密码。
[root@hadoop101 ~]#useradd doubi
[root@hadoop101 ~]#passwd doubi
2)修改配置文件
[root@hadoop101 ~]#vi /etc/sudoers
修改 /etc/sudoers 文件,找到下面一行(91行),在root下面添加一行,如下所示:
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
doubi ALL=(ALL) ALL
或者配置成采用sudo命令时,不需要输入密码
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
doubi ALL=(ALL) NOPASSWD:ALL
修改完毕,现在可以用doubi帐号登录,然后用命令 sudo ,即可获得root权限进行操作。
3)案例实操
(1)用普通用户在/opt目录下创建一个文件夹
[doubi@hadoop101 opt]$ sudo mkdir module
[root@hadoop101 opt]# chown doubi:doubi module/
4.9 usermod 修改用户
1)基本语法
usermod -g 用户组 用户名
2)选项说明
表1-24
| 选项 | 功能 |
|---|---|
| -g | 修改用户的初始登录组,给定的组必须存在 |
3)案例实操
(1)将用户加入到用户组
[root@hadoop101 opt]#usermod -g root zhubajie
5 用户组管理命令
每个用户都有一个用户组,系统可以对一个用户组中的所有用户进行集中管理。不同Linux 系统对用户组的规定有所不同,
如Linux下的用户属于与它同名的用户组,这个用户组在创建用户时同时创建。
用户组的管理涉及用户组的添加、删除和修改。组的增加、删除和修改实际上就是对/etc/group文件的更新。
5.1 groupadd 新增组
1)基本语法
groupadd 组名
2)案例实操
(1)添加一个xitianqujing组
[root@hadoop101 opt]#groupadd xitianqujing
5.2 groupdel 删除组
1)基本语法
groupdel 组名
2)案例实操
(1)删除xitianqujing组
[root@hadoop101 opt]# groupdel xitianqujing
5.3 groupmod 修改组
1)基本语法
groupmod -n 新组名 老组名
2)选项说明
表1-25
| 选项 | 功能描述 |
|---|---|
| -n<新组名> | 指定工作组的新组名 |
3)案例实操
(1)修改doubi组名称为doubi1
[root@hadoop101 ~]#groupadd xitianqujing
[root@hadoop101 ~]# groupmod -n xitian xitianqujing
5.4 cat /etc/group 查看创建了哪些组
1)基本操作
[root@hadoop101 doubi]# cat /etc/group
6 文件权限类
6.1 文件属性
Linux系统是一种典型的多用户系统,不同的用户处于不同的地位,拥有不同的权限。为了保护系统的安全性,Linux系统对不同的用户访问同一文件(包括目录文件)的权限做了不同的规定。在Linux中我们可以使用ll或者ls -l命令来显示一个文件的属性以及文件所属的用户和组。
1)从左到右的10个字符表示

图 文件属性
如果没有权限,就会出现减号[ - ]而已。从左至右用0-9这些数字来表示:
(1)0首位表示类型
在Linux中第一个字符代表这个文件是目录、文件或链接文件等等
- 代表文件
d 代表目录
l 链接文档(link file);
(2)第1-3位确定属主(该文件的所有者)拥有该文件的权限。—User
(3)第4-6位确定属组(所有者的同组用户)拥有该文件的权限,—Group
(4)第7-9位确定其他用户拥有该文件的权限 —Other
2)rxw作用文件和目录的不同解释
(1)作用到文件:
[ r ]代表可读(read): 可以读取,查看
[ w ]代表可写(write): 可以修改,但是不代表可以删除该文件,删除一个文件的前提条件是对该文件所在的目录有写权限,才能删除该文件.
[ x ]代表可执行(execute):可以被系统执行
(2)作用到目录:
[ r ]代表可读(read): 可以读取,ls查看目录内容
[ w ]代表可写(write): 可以修改,目录内创建+删除+重命名目录
[ x ]代表可执行(execute):可以进入该目录
3)案例实操
[root@hadoop101 ~]# ll
总用量 104
-rw-------. 1 root root 1248 1月 8 17:36 anaconda-ks.cfg
drwxr-xr-x. 2 root root 4096 1月 12 14:02 dssz
lrwxrwxrwx. 1 root root 20 1月 12 14:32 houzi -> xiyou/dssz/houge.tx
文件基本属性介绍

(1)如果查看到是文件:链接数指的是硬链接个数。创建硬链接方法
ln [原文件] [目标文件]
[root@hadoop101 ~]# ln xiyou/dssz/houge.txt ./hg.txt
(2)如果查看的是文件夹:链接数指的是子文件夹个数。
[root@hadoop101 ~]# ls -al xiyou/
总用量 16
drwxr-xr-x. 4 root root 4096 1月 12 14:00 .
dr-xr-x---. 29 root root 4096 1月 12 14:32 ..
drwxr-xr-x. 2 root root 4096 1月 12 14:30 dssz
drwxr-xr-x. 2 root root 4096 1月 12 14:04 mingjie
6.2 chmod 改变权限
1)基本语法

第一种方式变更权限
chmod [{ugoa}{±=}{rwx}] 文件或目录
第二种方式变更权限
chmod [mode=421 ] [文件或目录]
2)经验技巧
u:所有者 g:所有组 o:其他人 a:所有人(u、g、o的总和)
r=4 w=2 x=1 rwx=4+2+1=7
3)案例实操
(1)修改文件使其所属主用户具有执行权限
[root@hadoop101 ~]# cp xiyou/dssz/houge.txt ./
[root@hadoop101 ~]# chmod u+x houge.txt
(2)修改文件使其所属组用户具有执行权限
[root@hadoop101 ~]# chmod g+x houge.txt
(3)修改文件所属主用户执行权限,并使其他用户具有执行权限
[root@hadoop101 ~]# chmod u-x,o+x houge.txt
(4)采用数字的方式,设置文件所有者、所属组、其他用户都具有可读可写可执行权限。
[root@hadoop101 ~]# chmod 777 houge.txt
(5)修改整个文件夹里面的所有文件的所有者、所属组、其他用户都具有可读可写可执行权限。
[root@hadoop101 ~]# chmod -R 777 xiyou/
6.3 chown 改变所有者
1)基本语法
chown [选项] [最终用户] [文件或目录] (功能描述:改变文件或者目录的所有者)
2)选项说明
表1-26
| 选项 | 功能 |
|---|---|
| -R | 递归操作 |
3)案例实操
(1)修改文件所有者
[root@hadoop101 ~]# chown doubi houge.txt
[root@hadoop101 ~]# ls -al
-rwxrwxrwx. 1 doubi root 551 5月 23 13:02 houge.txt
(2)递归改变文件所有者和所有组
[root@hadoop101 xiyou]# ll
drwxrwxrwx. 2 root root 4096 9月 3 21:20 xiyou
[root@hadoop101 xiyou]# chown -R doubi:doubi xiyou/
[root@hadoop101 xiyou]# ll
drwxrwxrwx. 2 doubi doubi 4096 9月 3 21:20 xiyou
6.4 chgrp 改变所属组
1)基本语法
chgrp [最终用户组] [文件或目录] (功能描述:改变文件或者目录的所属组)
2)案例实操
(1)修改文件的所属组
[root@hadoop101 ~]# chgrp root houge.txt
[root@hadoop101 ~]# ls -al
-rwxrwxrwx. 1 doubi root 551 5月 23 13:02 houge.txt
7 搜索查找类
7.1 find 查找文件或者目录
find指令将从指定目录向下递归地遍历其各个子目录,将满足条件的文件显示在终端。
1)基本语法
find [搜索范围] [选项]
2)选项说明
表1-27
| 选项 | 功能 |
|---|---|
| -name<查询方式> | 按照指定的文件名查找模式查找文件 |
| -user<用户名> | 查找属于指定用户名所有文件 |
| -size<文件大小> | 按照指定的文件大小查找文件。 |
3)案例实操
(1)按文件名:根据名称查找/目录下的filename.txt文件。
[root@hadoop101 ~]# find xiyou/ -name “*.txt”
(2)按拥有者:查找/opt目录下,用户名称为-user的文件
[root@hadoop101 ~]# find opt/ -user doubi
(3)按文件大小:在/home目录下查找大于200m的文件(+n 大于 -n小于 n等于)
[root@hadoop101 ~]find /home -size +204800
7.2 grep 过滤查找及“|”管道符
管道符,“|”,表示将前一个命令的处理结果输出传递给后面的命令处理
1)基本语法
grep 选项 查找内容 源文件
2)选项说明
表1-28
| 选项 | 功能 |
|---|---|
| -n | 显示匹配行及行号。 |
3)案例实操
(1)查找某文件在第几行
[root@hadoop101 ~]# ls | grep -n test
7.3 which 查找命令
查找命令在那个目录下
1)基本语法
which 命令
2)案例实操
[root@hadoop101 ~]# which ll
8 压缩和解压类
8.1 gzip/gunzip 压缩
1)基本语法
gzip 文件 (功能描述:压缩文件,只能将文件压缩为*.gz文件)
gunzip 文件.gz (功能描述:解压缩文件命令)
2)经验技巧
(1)只能压缩文件不能压缩目录
(2)不保留原来的文件
3)案例实操
(1)gzip压缩
[root@hadoop101 ~]# ls
test.java
[root@hadoop101 ~]# gzip houge.txt
[root@hadoop101 ~]# ls
houge.txt.gz
(2)gunzip解压缩文件
[root@hadoop101 ~]# gunzip houge.txt.gz
[root@hadoop101 ~]# ls
houge.txt
8.2 zip/unzip 压缩
1)基本语法
zip [选项] XXX.zip 将要压缩的内容 (功能描述:压缩文件和目录的命令)
unzip [选项] XXX.zip (功能描述:解压缩文件)
2)选项说明
表1-29
| zip选项 | 功能 |
|---|---|
| -r | 压缩目录 |
表1-30
| unzip选项 | 功能 |
|---|---|
| -d<目录> | 指定解压后文件的存放目录 |
3)经验技巧
zip 压缩命令在window/linux都通用,可以压缩目录且保留源文件。
4)案例实操
(1)压缩 1.txt 和2.txt,压缩后的名称为mypackage.zip
[root@hadoop101 opt]# touch bailongma.txt
[root@hadoop101 ~]# zip houma.zip houge.txt bailongma.txt adding: houge.txt (stored 0%)adding: bailongma.txt (stored 0%)
[root@hadoop101 opt]# ls
houge.txt bailongma.txt houma.zip
(2)解压 mypackage.zip
[root@hadoop101 ~]# unzip houma.zip
Archive: houma.zipextracting: houge.txt extracting: bailongma.txt
[root@hadoop101 ~]# ls
houge.txt bailongma.txt houma.zip
(3)解压mypackage.zip到指定目录-d
[root@hadoop101 ~]# unzip houma.zip -d /opt
[root@hadoop101 ~]# ls /opt/
8.3 tar 打包
1)基本语法
tar [选项] XXX.tar.gz 将要打包进去的内容 (功能描述:打包目录,压缩后的文件格式.tar.gz)
2)选项说明
表1-31
| 选项 | 功能 |
|---|---|
| -z | 打包同时压缩 |
| -c | 产生.tar打包文件 |
| -v | 显示详细信息 |
| -f | 指定压缩后的文件名 |
| -x | 解包.tar文件 |
3)案例实操
(1)压缩多个文件
[root@hadoop101 opt]# tar -zcvf houma.tar.gz houge.txt bailongma.txt
houge.txt
bailongma.txt
[root@hadoop101 opt]# ls
houma.tar.gz houge.txt bailongma.txt
(2)压缩目录
[root@hadoop101 ~]# tar -zcvf xiyou.tar.gz xiyou/
xiyou/
xiyou/mingjie/
xiyou/dssz/
xiyou/dssz/houge.txt
(3)解压到当前目录
[root@hadoop101 ~]# tar -zxvf houma.tar.gz
(4)解压到指定目录
[root@hadoop101 ~]# tar -zxvf xiyou.tar.gz -C /opt
[root@hadoop101 ~]# ll /opt/
9 磁盘分区类
9.1 df 查看磁盘空间使用情况
df: disk free 空余硬盘
1)基本语法
df 选项 (功能描述:列出文件系统的整体磁盘使用量,检查文件系统的磁盘空间占用情况)
2)选项说明
表1-32
| 选项 | 功能 |
|---|---|
| -h | 以人们较易阅读的 GBytes, MBytes, KBytes 等格式自行显示; |
3)案例实操
(1)查看磁盘使用情况
[root@hadoop101 ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda2 15G 3.5G 11G 26% /
tmpfs 939M 224K 939M 1% /dev/shm
/dev/sda1 190M 39M 142M 22% /boot
9.2 fdisk 查看分区
1)基本语法
fdisk -l (功能描述:查看磁盘分区详情)
2)选项说明
表1-33
| 选项 | 功能 |
|---|---|
| -l | 显示所有硬盘的分区列表 |
3)经验技巧
该命令必须在root用户下才能使用
4)功能说明
(1)Linux分区
Device:分区序列
Boot:引导
Start:从X磁柱开始
End:到Y磁柱结束
Blocks:容量
Id:分区类型ID
System:分区类型
(2)Win7分区

图 Win7分区
5)案例实操
(1)查看系统分区情况
[root@hadoop101 /]# fdisk -l
Disk /dev/sda: 21.5 GB, 21474836480 bytes
255 heads, 63 sectors/track, 2610 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x0005e654Device Boot Start End Blocks Id System
/dev/sda1 * 1 26 204800 83 Linux
Partition 1 does not end on cylinder boundary.
/dev/sda2 26 1332 10485760 83 Linux
/dev/sda3 1332 1593 2097152 82 Linux swap / Solaris
9.3 mount/umount 挂载/卸载
对于Linux用户来讲,不论有几个分区,分别分给哪一个目录使用,它总归就是一个根目录、一个独立且唯一的文件结构。
Linux中每个分区都是用来组成整个文件系统的一部分,它在用一种叫做“挂载”的处理方法,它整个文件系统中包含了一整套的文件和目录,并将一个分区和一个目录联系起来,要载入的那个分区将使它的存储空间在这个目录下获得。
1)挂载前准备(必须要有光盘或者已经连接镜像文件)
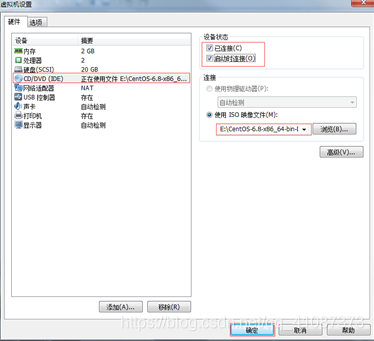
图 挂载镜像文件
2)基本语法
mount [-t vfstype] [-o options] device dir (功能描述:挂载设备)
umount 设备文件名或挂载点 (功能描述:卸载设备)
3)参数说明
表1-34
| 参数 | 功能 |
|---|---|
| -t vfstype | 指定文件系统的类型,通常不必指定。mount 会自动选择正确的类型。常用类型有:光盘或光盘镜像:iso9660DOS fat16文件系统:msdos Windows 9x fat32文件系统:vfat Windows NT ntfs文件系统:ntfs Mount Windows文件网络共享:smbfsUNIX(LINUX) 文件网络共享:nfs |
| -o options | 主要用来描述设备或档案的挂接方式。常用的参数有:loop:用来把一个文件当成硬盘分区挂接上系统 ro:采用只读方式挂接设备 rw:采用读写方式挂接设备 iocharset:指定访问文件系统所用字符集 |
| device | 要挂接(mount)的设备 |
| dir | 设备在系统上的挂接点(mount point) |
4)案例实操
(1)挂载光盘镜像文件
[root@hadoop101 ~]# mkdir /mnt/cdrom/ 建立挂载点
[root@hadoop101 ~]# mount -t iso9660 /dev/cdrom /mnt/cdrom/ 设备/dev/cdrom挂载到 挂载点 : /mnt/cdrom中
[root@hadoop101 ~]# ll /mnt/cdrom/
(2)卸载光盘镜像文件
[root@hadoop101 ~]# umount /mnt/cdrom
5)设置开机自动挂载
[root@hadoop101 ~]# vi /etc/fstab
添加红框中内容,保存退出。

10 进程线程类
进程是正在执行的一个程序或命令,每一个进程都是一个运行的实体,都有自己的地址空间,并占用一定的系统资源。
10.1 ps 查看当前系统进程状态
ps:process status 进程状态
1)基本语法
ps -aux | grep xxx (功能描述:查看系统中所有进程)
ps -ef | grep xxx (功能描述:可以查看子父进程之间的关系)
2)选项说明
表1-35
| 选项 | 功能 |
|---|---|
| -a | 选择所有进程 |
| -u | 显示所有用户的所有进程 |
| -x | 显示没有终端的进程 |
3)功能说明
(1)ps -aux显示信息说明
USER:该进程是由哪个用户产生的
PID:进程的ID号
%CPU:该进程占用CPU资源的百分比,占用越高,进程越耗费资源;
%MEM:该进程占用物理内存的百分比,占用越高,进程越耗费资源;
VSZ:该进程占用虚拟内存的大小,单位KB;
RSS:该进程占用实际物理内存的大小,单位KB;
TTY:该进程是在哪个终端中运行的。其中tty1-tty7代表本地控制台终端,tty1-tty6是本地的字符界面终端,tty7是图形终端。pts/0-255代表虚拟终端。
STAT:进程状态。常见的状态有:R:运行、S:睡眠、T:停止状态、s:包含子进程、+:位于后台
START:该进程的启动时间
TIME:该进程占用CPU的运算时间,注意不是系统时间
COMMAND:产生此进程的命令名
(2)ps -ef显示信息说明
UID:用户ID
PID:进程ID
PPID:父进程ID
C:CPU用于计算执行优先级的因子。数值越大,表明进程是CPU密集型运算,执行优先级会降低;数值越小,表明进程是I/O密集型运算,执行优先级会提高
STIME:进程启动的时间
TTY:完整的终端名称
TIME:CPU时间
CMD:启动进程所用的命令和参数
4)经验技巧
如果想查看进程的CPU占用率和内存占用率,可以使用aux;
如果想查看进程的父进程ID可以使用ef;
5)案例实操
[root@hadoop101 datas]# ps aux

图 查看进程的CPU占用率和内存占用率
[root@hadoop101 datas]# ps -ef
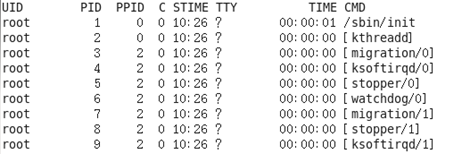
图 查看进程的父进程ID
10.2 kill 终止进程
1)基本语法
kill [选项] 进程号 (功能描述:通过进程号杀死进程)
killall 进程名称 (功能描述:通过进程名称杀死进程,也支持通配符,这在系统因负载过大而变得很慢时很有用)
2)选项说明
表1-36
| 选项 | 功能 |
|---|---|
| -9 | 表示强迫进程立即停止 |
3)案例实操
(1)杀死浏览器进程
[root@hadoop101 桌面]# kill -9 5102
(2)通过进程名称杀死进程
[root@hadoop101 桌面]# killall firefox
10.3 pstree 查看进程树
1)基本语法
pstree [选项]
2)选项说明
表1-37
| 选项 | 功能 |
|---|---|
| -p | 显示进程的PID |
| -u | 显示进程的所属用户 |
3)案例实操
(1)显示进程pid
[root@hadoop101 datas]# pstree -p
(2)显示进程所属用户
[root@hadoop101 datas]# pstree -u
10.4 top 查看系统健康状态
1)基本命令
top [选项]
2)选项说明
表1-38
| 选项 | 功能 |
|---|---|
| -d 秒数 | 指定top命令每隔几秒更新。默认是3秒在top命令的交互模式当中可以执行的命令: |
| -i | 使top不显示任何闲置或者僵死进程。 |
| -p | 通过指定监控进程ID来仅仅监控某个进程的状态。 |
3)操作说明
表1-39
| 操作 | 功能 |
|---|---|
| P | 以CPU使用率排序,默认就是此项 |
| M | 以内存的使用率排序 |
| N | 以PID排序 |
| q | 退出top |
4)查询结果字段解释
第一行信息为任务队列信息
表1-40
| 内容 | 说明 |
|---|---|
| 12:26:46 | 系统当前时间 |
| up 1 day, 13:32 | 系统的运行时间,本机已经运行1天 13小时32分钟 |
| 2 users | 当前登录了两个用户 |
| load average: 0.00, 0.00, 0.00 | 系统在之前1分钟,5分钟,15分钟的平均负载。一般认为小于1时,负载较小。如果大于1,系统已经超出负荷。 |
第二行为进程信息
表1-41
| Tasks: 95 total | 系统中的进程总数 |
| 1 running | 正在运行的进程数 |
| 94 sleeping | 睡眠的进程 |
| 0 stopped | 正在停止的进程 |
| 0 zombie | 僵尸进程。如果不是0,需要手工检查僵尸进程 |
第三行为CPU信息
表1-42
| Cpu(s): 0.1%us | 用户模式占用的CPU百分比 |
| 0.1%sy | 系统模式占用的CPU百分比 |
| 0.0%ni | 改变过优先级的用户进程占用的CPU百分比 |
| 99.7%id | 空闲CPU的CPU百分比 |
| 0.1%wa | 等待输入/输出的进程的占用CPU百分比 |
| 0.0%hi | 硬中断请求服务占用的CPU百分比 |
| 0.1%si | 软中断请求服务占用的CPU百分比 |
| 0.0%st | st(Steal time)虚拟时间百分比。就是当有虚拟机时,虚拟CPU等待实际CPU的时间百分比。 |
第四行为物理内存信息
表1-43
| Mem: 625344k total | 物理内存的总量,单位KB |
| 571504k used | 已经使用的物理内存数量 |
| 53840k free | 空闲的物理内存数量,我们使用的是虚拟机,总共只分配了628MB内存,所以只有53MB的空闲内存了 |
| 65800k buffers | 作为缓冲的内存数量 |
第五行为交换分区(swap)信息
表1-44
| Swap: 524280k total | 交换分区(虚拟内存)的总大小 |
| 0k used | 已经使用的交互分区的大小 |
| 524280k free | 空闲交换分区的大小 |
| 409280k cached | 作为缓存的交互分区的大小 |
5)案例实操
[root@hadoop101 doubi]# top -d 1
[root@hadoop101 doubi]# top -i
[root@hadoop101 doubi]# top -p 2575
执行上述命令后,可以按P、M、N对查询出的进程结果进行排序。
10.5 netstat 显示网络统计信息和端口占用情况
1)基本语法
netstat -anp |grep 进程号 (功能描述:查看该进程网络信息)
netstat -nlp | grep 端口号 (功能描述:查看网络端口号占用情况)
2)选项说明
表1-45
| 选项 | 功能 |
|---|---|
| -n | 拒绝显示别名,能显示数字的全部转化成数字 |
| -l | 仅列出有在listen(监听)的服务状态 |
| -p | 表示显示哪个进程在调用 |
3)案例实操
(1)通过进程号查看该进程的网络信息
[root@hadoop101 hadoop-2.7.2]# netstat -anp | grep 火狐浏览器进程号
unix 2 [ ACC ] STREAM LISTENING 20670 3115/firefox /tmp/orbit-root/linc-c2b-0-5734667cbe29
unix 3 [ ] STREAM CONNECTED 20673 3115/firefox /tmp/orbit-root/linc-c2b-0-5734667cbe29
unix 3 [ ] STREAM CONNECTED 20668 3115/firefox
unix 3 [ ] STREAM CONNECTED 20666 3115/firefox
(2)查看某端口号是否被占用
[root@hadoop101 桌面]# netstat -nlp | grep 20670
unix 2 [ ACC ] STREAM LISTENING 20670 3115/firefox /tmp/orbit-root/linc-c2b-0-5734667cbe29
11 crond 系统定时任务
11.1 crond 服务管理
1)重新启动crond服务
[root@hadoop101 ~]# service crond restart
11.2 crontab 定时任务设置
1)基本语法
crontab [选项]
2)选项说明
表1-46
| 选项 | 功能 |
|---|---|
| -e | 编辑crontab定时任务 |
| -l | 查询crontab任务 |
| -r | 删除当前用户所有的crontab任务 |
3)参数说明
[root@hadoop101 ~]# crontab -e
(1)进入crontab编辑界面。会打开vim编辑你的工作。
-
-
-
-
- 执行的任务
表1-47
- 执行的任务
-
-
-
| 项目 | 含义 | 范围 |
|---|---|---|
| 第一个“*” | 一小时当中的第几分钟 | 0-59 |
| 第二个“*” | 一天当中的第几小时 | 0-23 |
| 第三个“*” | 一个月当中的第几天 | 1-31 |
| 第四个“*” | 一年当中的第几月 | 1-12 |
| 第五个“*” | 一周当中的星期几 | 0-7(0和7都代表星期日) |
(2)特殊符号
表1-48
| 特殊符号 | 含义 |
|---|---|
| * | 代表任何时间。比如第一个“*”就代表一小时中每分钟都执行一次的意思。 |
| , | 代表不连续的时间。比如“0 8,12,16 * * * 命令”,就代表在每天的8点0分,12点0分,16点0分都执行一次命令 |
| - | 代表连续的时间范围。比如“0 5 * * 1-6命令”,代表在周一到周六的凌晨5点0分执行命令 |
| */n | 代表每隔多久执行一次。比如“*/10 * * * * 命令”,代表每隔10分钟就执行一遍命令 |
(3)特定时间执行命令
表1-49
| 时间 | 含义 |
|---|---|
| 45 22 * * * 命令 | 在22点45分执行命令 |
| 0 17 * * 1 命令 | 每周1 的17点0分执行命令 |
| 0 5 1,15 * * 命令 | 每月1号和15号的凌晨5点0分执行命令 |
| 40 4 * * 1-5 命令 | 每周一到周五的凌晨4点40分执行命令 |
| */10 4 * * * 命令 | 每天的凌晨4点,每隔10分钟执行一次命令 |
| 0 0 1,15 * 1 命令 | 每月1号和15号,每周1的0点0分都会执行命令。注意:星期几和几号最好不要同时出现,因为他们定义的都是天。非常容易让管理员混乱。 |
4)案例实操
(1)每隔1分钟,向/root/bailongma.txt文件中添加一个11的数字
*/1 * * * * /bin/echo ”11” >> /root/bailongma.txt
八 软件包管理
1 RPM
1.1 RPM概述
RPM(RedHat Package Manager),RedHat软件包管理工具,类似windows里面的setup.exe
是Linux这系列操作系统里面的打包安装工具,它虽然是RedHat的标志,但理念是通用的。
RPM包的名称格式
Apache-1.3.23-11.i386.rpm
- “apache” 软件名称
- “1.3.23-11”软件的版本号,主版本和此版本
- “i386”是软件所运行的硬件平台,Intel 32位微处理器的统称
- “rpm”文件扩展名,代表RPM包
1.2 RPM查询命令(rpm -qa)
1)基本语法
rpm -qa (功能描述:查询所安装的所有rpm软件包)
2)经验技巧
由于软件包比较多,一般都会采取过滤。rpm -qa | grep rpm软件包
3)案例实操
(1)查询firefox软件安装情况
[root@hadoop101 Packages]# rpm -qa |grep firefox
firefox-45.0.1-1.el6.centos.x86_64
1.3 RPM卸载命令(rpm -e)
1)基本语法
(1)rpm -e RPM软件包
(2) rpm -e --nodeps 软件包
2)选项说明
表1-50
| 选项 | 功能 |
|---|---|
| -e | 卸载软件包 |
| –nodeps | 卸载软件时,不检查依赖。这样的话,那些使用该软件包的软件在此之后可能就不能正常工作了。 |
3)案例实操
(1)卸载firefox软件
[root@hadoop101 Packages]# rpm -e firefox
1.4 RPM安装命令(rpm -ivh)
1)基本语法
rpm -ivh RPM包全名
2)选项说明
表1-51
| 选项 | 功能 |
|---|---|
| -i | -i=install,安装 |
| -v | -v=verbose,显示详细信息 |
| -h | -h=hash,进度条 |
| –nodeps | –nodeps,不检测依赖进度 |
3)案例实操
(1)安装firefox软件
[root@hadoop101 Packages]# pwd
/media/CentOS_6.8_Final/Packages
[root@hadoop101 Packages]# rpm -ivh firefox-45.0.1-1.el6.centos.x86_64.rpm
warning: firefox-45.0.1-1.el6.centos.x86_64.rpm: Header V3 RSA/SHA1 Signature, key ID c105b9de: NOKEY
Preparing... ########################################### [100%]1:firefox ########################################### [100%]
2 YUM仓库配置
2.1 YUM概述
YUM(全称为 Yellow dog Updater, Modified)是一个在Fedora和RedHat以及CentOS中的Shell前端软件包管理器。基于RPM包管理,能够从指定的服务器自动下载RPM包并且安装,可以自动处理依赖性关系,并且一次安装所有依赖的软件包,无须繁琐地一次次下载、安装。
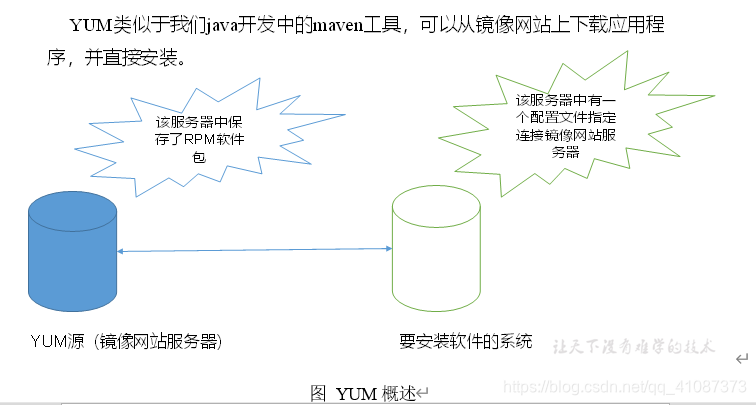
2.2 YUM的常用命令
1)基本语法
yum [选项] [参数]
2)选项说明
表1-52
| 选项 | 功能 |
|---|---|
| -y | 对所有提问都回答“yes” |
3)参数说明
表1-53
| 参数 | 功能 |
|---|---|
| install | 安装rpm软件包 |
| update | 更新rpm软件包 |
| check-update | 检查是否有可用的更新rpm软件包 |
| remove | 删除指定的rpm软件包 |
| list | 显示软件包信息 |
| clean | 清理yum过期的缓存 |
| deplist | 显示yum软件包的所有依赖关系 |
4)案例实操实操
(1)采用yum方式安装firefox
[root@hadoop101 ~]#yum -y install firefox.x86_64
2.3 修改网络YUM源
默认的系统YUM源,需要连接国外apache网站,网速比较慢,可以修改关联的网络YUM源为国内镜像的网站,比如网易163。
1)前期文件准备
(1)前提条件linux系统必须可以联网
(2)在Linux环境中访问该网络地址:http://mirrors.163.com/.help/centos.html,在使用说明中点击CentOS6->再点击保存

图 下载CentOS6
(3)查看文件保存的位置。
图1-165
图1-166
在打开的终端中输入如下命令,就可以找到文件的保存位置。
[doubi@hadoop101 下载]$ pwd
/home/doubi/下载
2)替换本地yum文件
(1)把下载的文件移动到/etc/yum.repos.d/目录
[root@hadoop101 下载]# mv CentOS6-Base-163.repo /etc/yum.repos.d/
(2)进入到/etc/yum.repos.d/目录
[root@hadoop101 yum.repos.d]# pwd
/etc/yum.repos.d
(3)用CentOS6-Base-163.repo替换CentOS-Base.repo
[root@hadoop101 yum.repos.d]# mv CentOS6-Base-163.repo CentOS-Base.repo
3)安装命令
(1)
[root@hadoop101 yum.repos.d]#yum clean all
(2)
[root@hadoop101 yum.repos.d]#yum makecache
yum makecache就是把服务器的包信息下载到本地电脑缓存起来
4)测试
[root@hadoop101 yum.repos.d]#yum list | grep firefox
[root@hadoop101 ~]#yum -y install firefox.x86_64
九 常见错误及解决方案
虚拟化支持异常情况如下几种情况

图1-168

图1-169
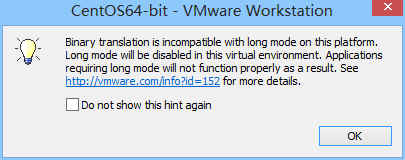
图1-170

问题原因:宿主机BIOS设置中的硬件虚拟化被禁用了
解决办法:需要打开笔记本BIOS中的IVT对虚拟化的支持

图1-172
总结
对于Linux内容的整理就到这边了,写了这么多,有点累,对于后面的大数据内容,会出一系列的,希望大家关注!!!!!这篇关于大数据学习一之Linux知识的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







