本文主要是介绍深潜Kotlin协程(十六):Channel,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
系列电子书:传送门
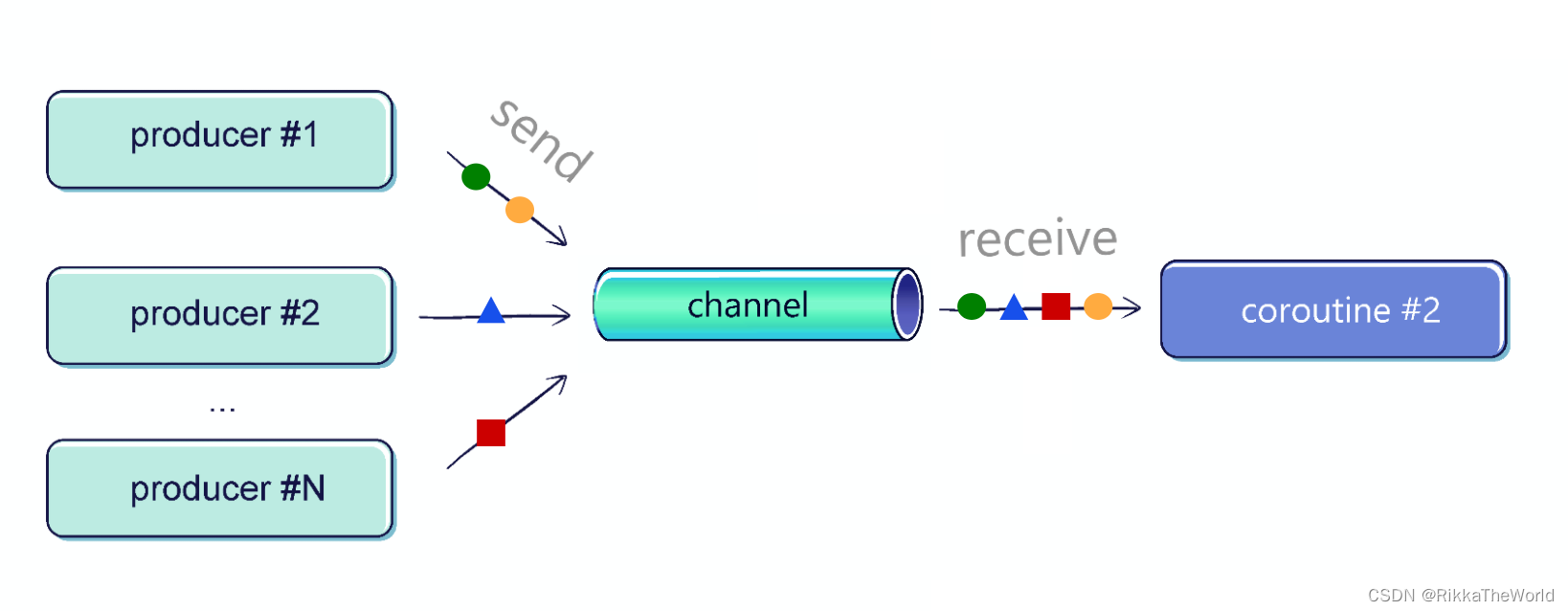
Channel API 用于在协程间的原语通信。许多人把 channel 想象成 pipe(管道)。但我更喜欢一个不同的比喻,你熟悉用于交换书籍的公共书柜吗?一个人会在里面放上另一个人所需要找的书,这与 kotlinx.coroutines 的 Channel 非常相似。

Channel 支持任意数量的发送方和接收方。并且发送到 Channel 的每个值只会被一个协程接收(一次)。
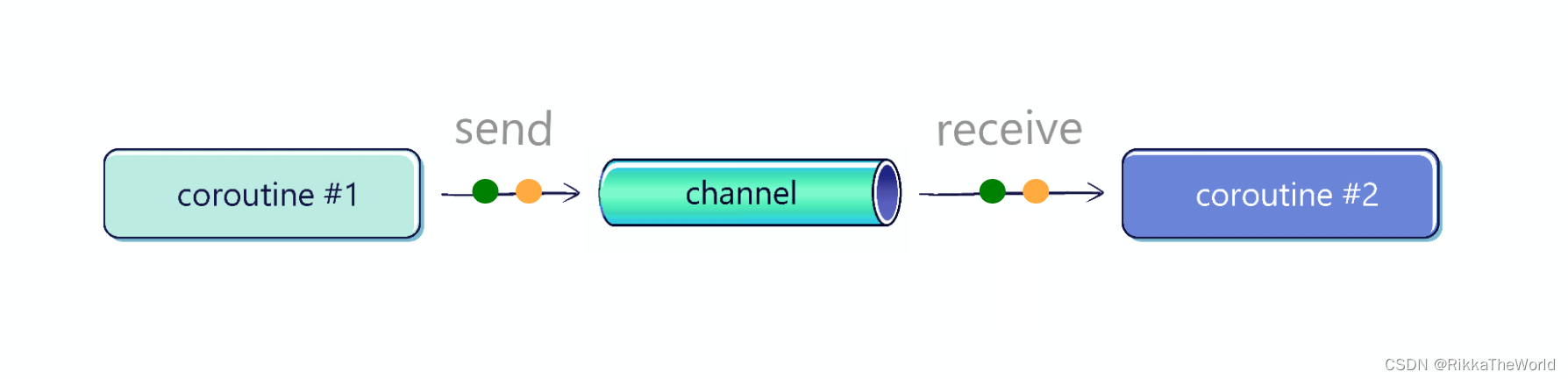
Channel 是一个接口,它实现了另外两个接口:
SendChannel: 用于发送(添加元素)和关闭管道ReceiveChannel: 用于接收元素
interface SendChannel<in E> {suspend fun send(element: E)fun close(): Boolean//...
}interface ReceiveChannel<out E> {suspend fun receive(): Efun cancel(cause: CancellationException? = null)// ...
}interface Channel<E> : SendChannel<E>, ReceiveChannel<E>
由于这种区别,我们可以只暴露 ReceiveChannel 或 SendChannel 来限制 channel 的入口/出口点。
你可能注意到了,send 和 receive 都是挂起函数,这是一个基本特性:
- 当我们尝试
receive而 channel 中没有元素时,协程将被挂起,直到该元素可用。就像我们的“书柜”一样,当有人去书架上找一本书,而书架是空的时候,这个人就需挂起,直到有人在那里放了一个他要的书 - 另一方面,当 channel 达到了容量阈值时,
send将会被挂起。我们很快就会看到,大多数 channel 的容量都是有限的。就像我们的“书柜”一样,当有人想把一本书放在书架上,而书架已经放满了书时,这个人就得挂起,直到有人拿走一本书,从而腾出空间
如果需要从非挂起函数中发送或接收信息,可以使用 trySend 和 tryReceive。这两个操作都是即时的,并返回 ChannelResult,包含了有关操作成功或失败的结果信息。我们只能对容量有限的 channel 使用 trySend 和 tryReceive,因为它们不适用于交会的 channel。
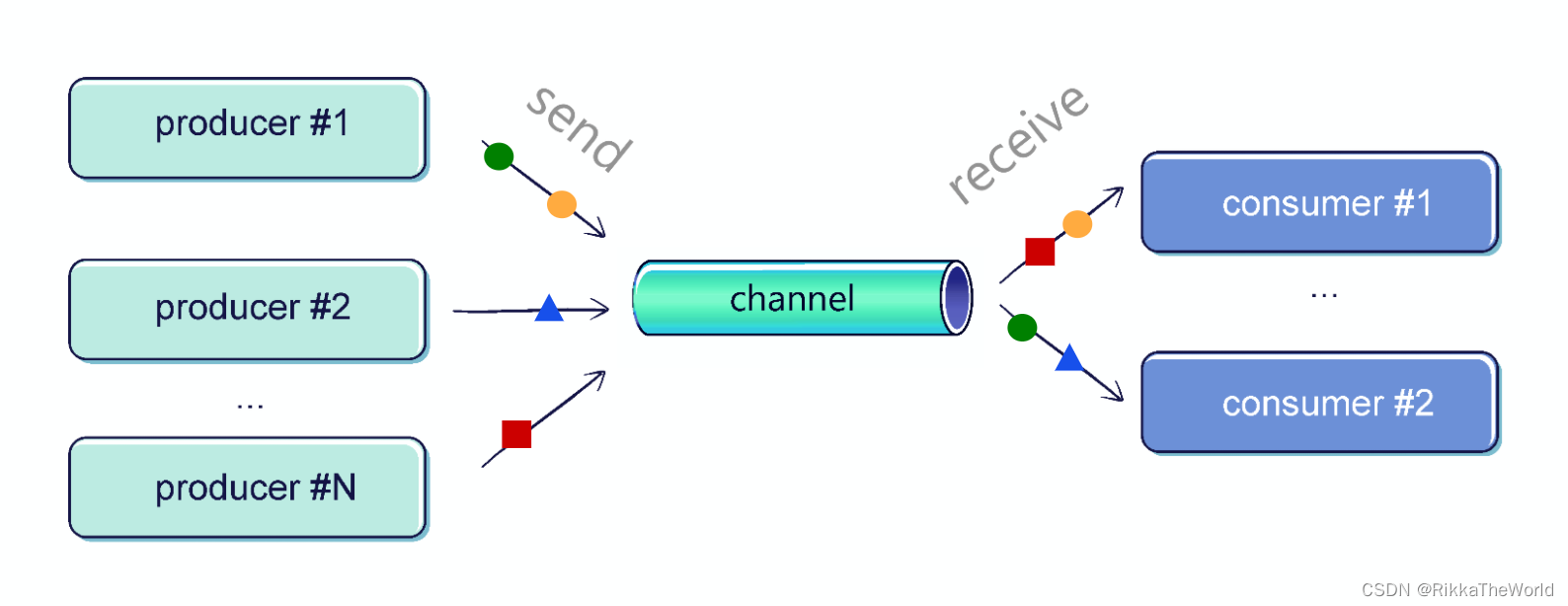
一个 channel 可以有任意数量的发送方和接收方,然而, channel 最常见的情况是两端只有一个协程。

想要看看 channel 的简单示例,我们需要在单独的协程中有一个生产者(发送方)和一个消费者(接收方)。生产者将发送元素,消费者将接收它们,以下是它们的实现方式:
suspend fun main(): Unit = coroutineScope {val channel = Channel<Int>()launch {repeat(5) { index ->delay(1000)println("Producing next one")channel.send(index * 2)}}launch {repeat(5) {val received = channel.receive()println(received)}}
}
// (1 sec)
// Producing next one
// 0
// (1 sec)
// Producing next one
// 2
// (1 sec)
// Producing next one
// 4
// (1 sec)
// Producing next one
// 6
// (1 sec
// Producing next one
// 8
这样的实现并不好。接收方需要知道发送方发送了多少个元素,所以上述的情况很少会发生,我们宁愿一直监听,直到发送者发送。要接收 channel 上的元素,可以使用 for循环 或 consumeEach 函数,它会一直监听发送直到 channel 关闭。
suspend fun main(): Unit = coroutineScope {val channel = Channel<Int>()launch {repeat(5) { index ->println("Producing next one")delay(1000)channel.send(index * 2)}channel.close()}launch {for (element in channel) {println(element)}// 或者// channel.consumeEach { element ->// println(element)// }}
}
使用这种方式发送元素的常见问题是:很容易忘记关闭 channel,特别是在异常情况下。如果一个协程因为异常而停止生产,另一个协程将会永远的等待元素。使用 produce 函数要方便的多,它是一个返回 ReceiveChannel 的协程构建器。
// 这个函数将会创建一个 channel,并且一直在
// 上面生产正整数,直至输入的最大值
fun CoroutineScope.produceNumbers(max: Int
): ReceiveChannel<Int> = produce {var x = 0while (x < max) send(x++)
}
当协程以任何方式结束(完成、停止、取消)时, produce 函数都会关闭通道。多亏了这一点,我们永远不会忘记调用 close。produce 构建器是一个非常受欢迎创建 channel 的方式,理由很充分:它提供了很多安全保障,并且方便。
suspend fun main(): Unit = coroutineScope {val channel = produce {repeat(5) { index ->println("Producing next one")delay(1000)send(index * 2)}}for (element in channel) {println(element)}
}
Channel 的类型
根据 channel 设置的容量大小,我们区分了四种类型的 channel:
- 无限制 —— 容量设置为
Channel.UNLIMITED的 channel,拥有一个无限的缓冲区,并且send永远不会挂起 - 缓冲 —— 有一个具体数量的缓冲区,或者设置为
Channel.BUFFERED(默认为64,可以通过在 JVM 中设置 kotlinx.coruoutines.channels.defaultBuffer 系统属性来重写)的 channel - 交会(默认) —— 容量为0,或者设置为
Channel.RENDEZVOUS(等于0) 的 channel。这意味着只有在发送者和接收者相遇时,才会发生数据通信。(所以它像一个图书交换点,而不是一个书柜) - 合并 —— 容量为1,或者设置为
Channel.CONFLATED的缓冲区,每个新元素会替换前一个元素
现在让我们来看看这些能力的实际应用。我们可以在 Channel 上设置它们,也可以在调用 produce 时设置。
我们将生产者快起来,接收者慢起来。在无限容量的情况下,channel 应该可以容纳所有的元素,然后让它们一个个的被接收处理。
suspend fun main(): Unit = coroutineScope {val channel = produce(capacity = Channel.UNLIMITED) {repeat(5) { index ->send(index * 2)delay(100)println("发送")}}delay(1000)for (element in channel) {println(element)delay(1000)}
}
// 发送
// (0.1 sec)
// 发送
// (0.1 sec)
// 发送
// (0.1 sec)
// 发送
// (0.1 sec)
// 发送
// (1 - 4 * 0.1 = 0.6 sec)
// 0
// (1 sec)
// 2
// (1 sec)
// 4
// (1 sec)
// 6
// (1 sec)
// 8
// (1 sec)
如果 channel 有具体的容量,我们首先生产到缓冲区满了,之后生产者将开始等待接收。
suspend fun main(): Unit = coroutineScope {val channel = produce(capacity = 3) {repeat(5) { index ->send(index * 2)delay(100)println("发送")}}delay(1000)for (element in channel) {println(element)delay(1000)}
}
// 发送
// (0.1 sec)
// 发送
// (0.1 sec)
// 发送
// (1 - 2 * 0.1 = 0.8 sec)
// 0
// 发送
// (1 sec)
// 2
// 发送
// (1 sec)
// 4
// (1 sec)
// 6
// (1 sec)
// 8
// (1 sec)
对于默认容量(Channel.RENDEZVOUS)的 channel,生产者将始终等待接收者。
suspend fun main(): Unit = coroutineScope {val channel = produce {// 或者 produce(capacity = Channel.RENDEZVOUS) {repeat(5) { index ->send(index * 2)delay(100)println("发送")}}delay(1000)for (element in channel) {println(element)delay(1000)}
}// 发送
// (1 sec)
// 2
// 发送
// (1 sec)
// 4
// 发送
// (1 sec)
// 6
// 发送
// (1 sec)
// 8
// 发送
// (1 sec)
最后,在使用 Channel.CONFLATED 时,我们不会存储过去的元素。新元素将会替换之前的元素,因此我们将只能接收最后一个元素,丢失之前发送的元素。
suspend fun main(): Unit = coroutineScope {val channel = produce(capacity = Channel.CONFLATED) {repeat(5) { index ->send(index * 2)delay(100)println("发送")}}delay(1000)for (element in channel) {println(element)delay(1000)}
}
// 发送
// (0.1 sec)
// 发送
// (0.1 sec)
// 发送
// (0.1 sec)
// 发送
// (0.1 sec)
// 发送
// (1 - 4 * 0.1 = 0.6 sec)
// 8
onBufferOverflow
为了进一步定制 channel,我们可以控制缓冲区堆满时发生的情况(onBufferOverflow 参数),有以下选项:
SUSPEND(默认) —— 当缓冲区塞满时,send函数挂起DROP_OLDEST—— 当缓冲区塞满时,删除最老的元素DROP_LATEST—— 当缓冲区塞满时,删除最新的元素
正如你所想那样,channel 设置容量为 Channel.CONFLATED 的效果就等于设置容量数为1并且 onBufferOverFlow 为 DROP_OLDEST。目前, produce 函数不允许我们自定义 onBufferOverflow,因此要设置它,我们需要使用 Channel 函数来定义一个 channel。
suspend fun main(): Unit = coroutineScope {val channel = Channel<Int>(capacity = 2,onBufferOverflow = BufferOverflow.DROP_OLDEST)launch {repeat(5) { index ->channel.send(index * 2)delay(100)println("发送")}channel.close()}delay(1000)for (element in channel) {println(element)delay(1000)}
}
// 发送
// (0.1 sec)
// 发送
// (0.1 sec)
// 发送
// (0.1 sec)
// 发送
// (0.1 sec)
// 发送
// (1 - 4 * 0.1 = 0.6 sec)
// 6
// (1 sec)
// 8
onUndeleliveredElement
我们应该知道的另一个 Channel 函数的参数是 onUndeleliveredElement。当某个元素由于某些原因无法处理时会调用它。大多数情况下,它意味着 channel 被关闭或者取消后,有可能在 send、receive、receiveOrNull 或 hasNext 抛出错误时发生。我们通常使用它来关闭由该通道发送的资源。
val channel = Channel<Resource>(capacity) { resource ->resource.close()
}
// 或者
// val channel = Channel<Resource>(
// capacity,
// onUndeliveredElement = { resource ->
// resource.close()
// }
// )// 生产者代码
val resourceToSend = openResource()
channel.send(resourceToSend)// 消费者代码
val resourceReceived = channel.receive()
try {// 接收工作
} finally {resourceReceived.close()
}
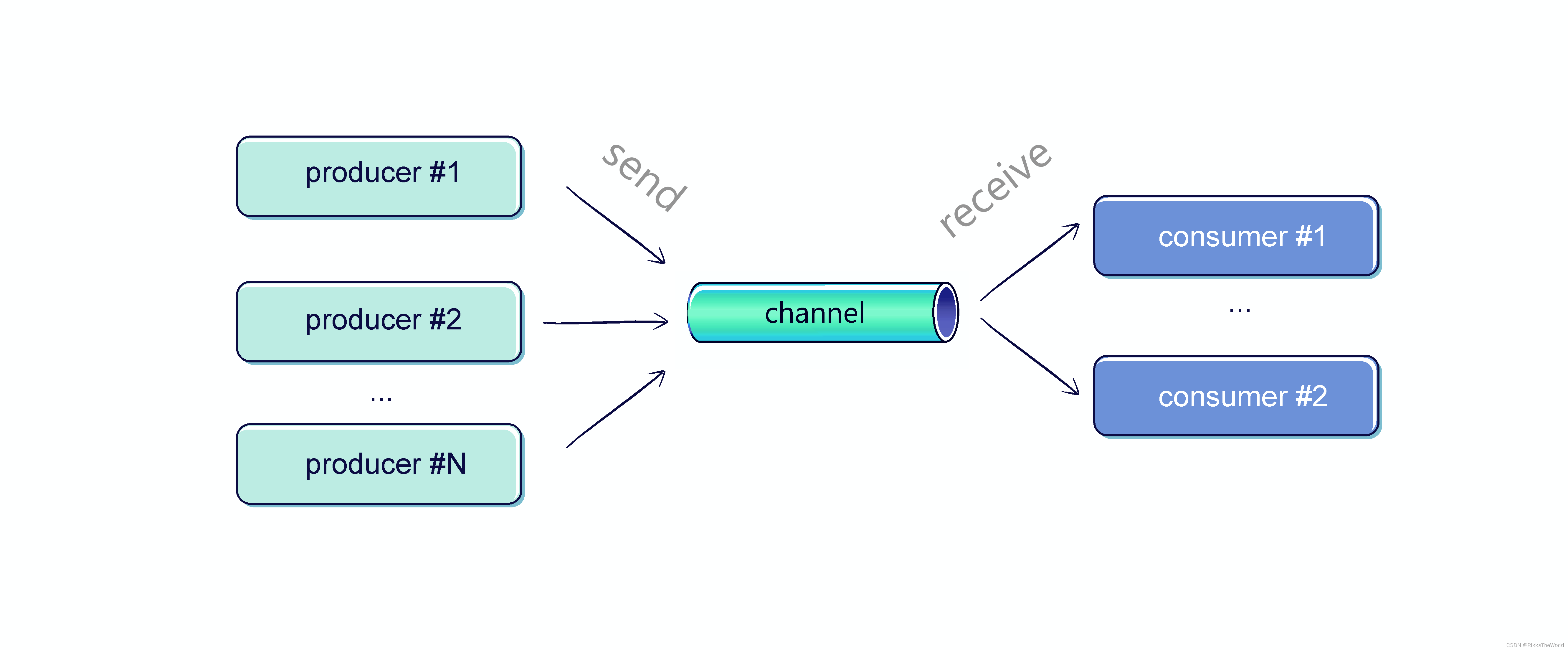
Fan-out
多个协程可以从单个 channel 接收元素,然而,为了正确地接收它们,我们应该使用 for 循环(多个协程使用 consumeEach 是不安全的)。
fun CoroutineScope.produceNumbers() = produce {repeat(10) {delay(100)send(it)}
}fun CoroutineScope.launchProcessor(id: Int,channel: ReceiveChannel<Int>
) = launch {for (msg in channel) {println("#$id received $msg")}
}suspend fun main(): Unit = coroutineScope {val channel = produceNumbers()repeat(3) { id ->delay(10)launchProcessor(id, channel)}
}
// #0 received 0
// #1 received 1
// #2 received 2
// #0 received 3
// #1 received 4
// #2 received 5
// #0 received 6
// ...
元素均匀分布。 channel 有一个 FIFO(先进先出)的协程队列等待一个元素。这就是为什么在上面的例子中,可以看到每个元素被下一个协程接收(0,1,2,0,1,2…)。
为了更好地理解为什么,想象一下幼儿园的孩子们在排队买糖果,一旦他们得到一些,他们就会立即吃掉它们,然后走到队列的最后一个位置。这样的分配是公平的(假设糖果的数量是孩子数量的倍数,并且假设他们的父母对孩子吃糖果没有什么意见)。
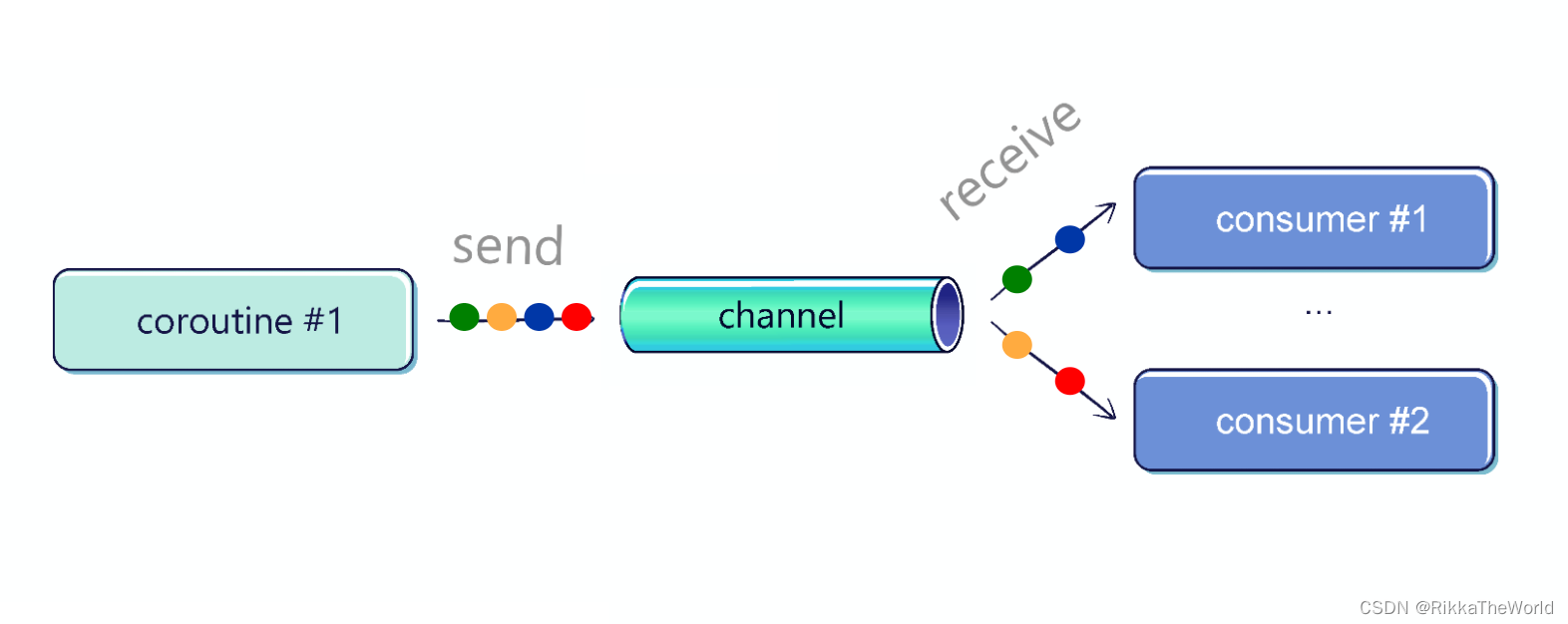
Fan-in
多个协程可以发送到同一个 channel。在下面的例子中,你可以看到两个协程将元素发送到同一个 channel。
suspend fun sendString(channel: SendChannel<String>,text: String,time: Long
) {while (true) {delay(time)channel.send(text)}
}fun main() = runBlocking {val channel = Channel<String>()launch { sendString(channel, "foo", 200L) }launch { sendString(channel, "BAR!", 500L) }repeat(50) {println(channel.receive())}coroutineContext.cancelChildren()
}
有时候,我们需要将多个渠道合并为一个渠道,为此,你可能会发现下面的函数很有用,因为它使用 produce 合并多个 channel。
fun <T> CoroutineScope.fanIn(channels: List<ReceiveChannel<T>>
): ReceiveChannel<T> = produce {for (channel in channels) {launch {for (elem in channel) {send(elem)}}}
}
Pipelines
有时我们设置两个 channel,其中一个产生的元素是基于从另一个接收到元素。在这种情况下,我们称之为管道。
// 一个 Channel 发送从 1 到 3
fun CoroutineScope.numbers(): ReceiveChannel<Int> =produce {repeat(3) { num ->send(num + 1)}}fun CoroutineScope.square(numbers: ReceiveChannel<Int>) =produce {for (num in numbers) {send(num * num)}}suspend fun main() = coroutineScope {val numbers = numbers()val squared = square(numbers)for (num in squared) {println(num)}
}
// 1
// 4
// 9
Channel 是原语通信的
当不同的协程需要互相通信时, Channel 很有用,它们保证没有冲突(例如,共享状态没有问题)并且公平。
想象一下不同的咖啡师正在冲咖啡。每个咖啡师都应该是独立工作的协程。不同的咖啡类型需要不同准备时间,但我们希望按照顺序处理订单。解决这个问题最简单的方案是在 Channel 中同时发送订单和生成的咖啡结果,可以使用 produce 生成器定义咖啡师:
suspend fun CoroutineScope.serveOrders(orders: ReceiveChannel<Order>,baristaName: String
): ReceiveChannel<CoffeeResult> = produce {for (order in orders) {val coffee = prepareCoffee(order.type)send(CoffeeResult(coffee = coffee,customer = order.customer,baristaName = baristaName))}
}
当我们设置一个管道时,我们可以使用前面定义的 fanIn 函数将不同的咖啡师产生的结果合并为一个:
val coffeeResults = fanIn(serveOrders(ordersChannel, "Alex"),serveOrders(ordersChannel, "Bob"),serveOrders(ordersChannel, "Celine"),
)
在下一章中,你将会看到更多实际的例子。
Practical usage
实际使用情况
我们使用 channel 的一个典型情况是:一端产生值,另一端处理。这些例子包括响应用户点击、来自服务器的新通知或随着时间推移更新搜索结果(一个很好的例子是 SkyScanner,它通过查询多个航空公司网站来搜索最便宜的航班)。然而,在大多数情况下,最好使用 channelFlow 或 callbackFlow,它们都是 Channel 和 Flow 的混合体(我们将在构建 Flow 的章节中介绍它们)。
纯粹形式而言,我发现 channel 在一些更复杂的情况下很有用。例如,假设我们正在维护一个线上商店,比如亚马逊。让我们假设你的服务器收到了大量卖家的更改产品信息的提交。对于每个更改,我们首先需要找到最新的报价列表,然后逐个更新它们。
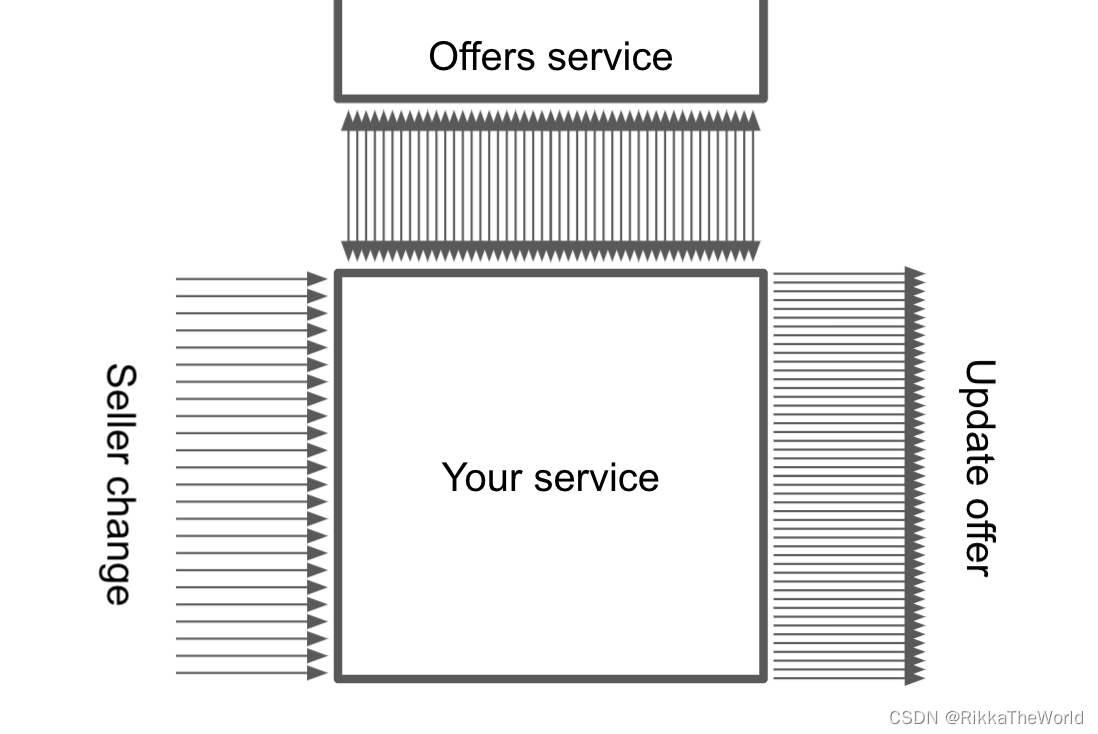
传统方法并不是最佳的,一个卖家甚至可能有成千上万的售价更改。在一个漫长的过程中完成这一切并不是一个好的主意。
首先,内部异常或服务器重启可能会让我们不知道停在哪里。其次,一个大卖家可能会阻塞服务器很长一段时间,从而让小卖家等待它们的更改被应用。此外,我们不应该同时发送太多的网络请求,以避免需要处理这些请求的服务(以及我们的网络接口)过载。
这个问题的解决方法可能是建立一个管道。第一个通道包含要处理的卖家,而第二个通道包含要更新的报价。这些通道会有一个缓冲区。当已经有太多的提交在等待时,第二个提交的缓冲区可以防止我们的服务有得更多的提交。因此,我们的服务器将能够平衡我们在同一时间更新的报价数量。
我们还可以很容易地添加一些中间步骤,例如删除重复项。通过定义在每个通道上监听的协程的数量,我们可以决定服务发送多少并发请求。控制这些参数给了我们很大的自由。还可以很容易地添加许多改进,如持久性(用于服务器重启的情况)或元素唯一性(用于卖家在前一个更改被处理之前进行另一个更改的情况)。
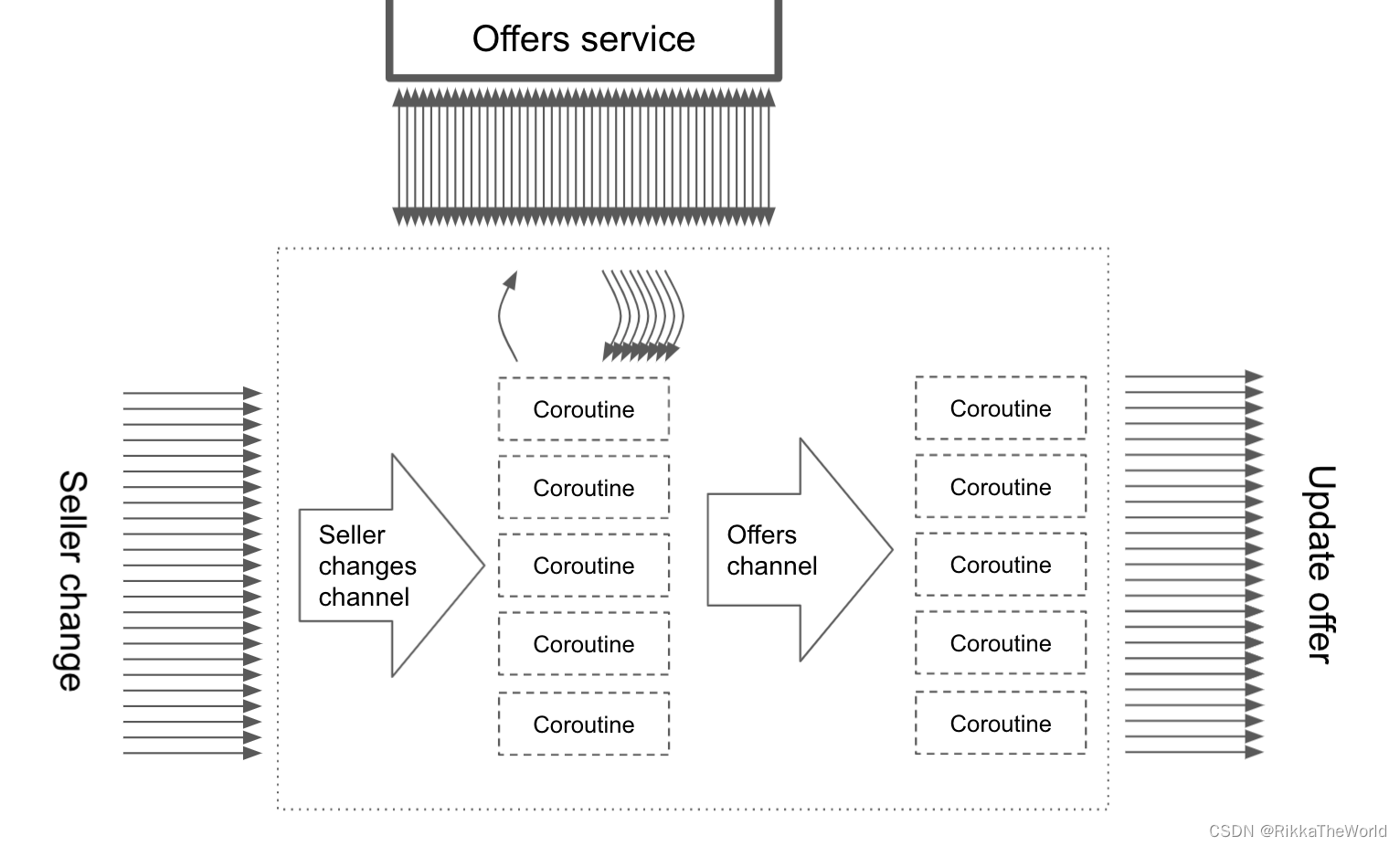
// 一个简单的实现
suspend fun handleOfferUpdates() = coroutineScope {val sellerChannel = listenOnSellerChanges()val offerToUpdateChannel = produce(capacity = UNLIMITED) {repeat(NUMBER_OF_CONCURRENT_OFFER_SERVICE_REQUESTS) {launch {for (seller in sellerChannel) {val offers = offerService.requestOffers(seller.id)offers.forEach { send(it) }}}}}repeat(NUMBER_OF_CONCURRENT_UPDATE_SENDERS) {launch {for (offer in offerToUpdateChannel) {sendOfferUpdate(offer)}}}
}
总结
Channel 是一个强大的协程间原语通信的工具。它支持任意数量的发送方和接收方,并且发送到通道的每个值只能被接收一次。我们通常使用 produce 构建器来创建 channel,在 channel 中可以控制处理某些任务的协程数量。入金,我们最常用的是与 Flow 相关的 channel,这将在本书的后面介绍。
这篇关于深潜Kotlin协程(十六):Channel的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



