本文主要是介绍Oracle的学习心得和知识总结(十三)|Oracle数据库Real Application Testing之Database Replay实操(一),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录结构
注:提前言明 本文借鉴了以下博主、书籍或网站的内容,其列表如下:
1、参考书籍:《Oracle Database SQL Language Reference》
2、参考书籍:《PostgreSQL中文手册》
3、EDB Postgres Advanced Server User Guides,点击前往
4、PostgreSQL数据库仓库链接,点击前往
5、PostgreSQL中文社区,点击前往
6、Oracle Real Application Testing 官网首页,点击前往
7、Oracle 21C RAT Testing Guide,点击前往
1、本文内容全部来源于开源社区 GitHub和以上博主的贡献,本文也免费开源(可能会存在问题,评论区等待大佬们的指正)
2、本文目的:开源共享 抛砖引玉 一起学习
3、本文不提供任何资源 不存在任何交易 与任何组织和机构无关
4、大家可以根据需要自行 复制粘贴以及作为其他个人用途,但是不允许转载 不允许商用 (写作不易,还请见谅 💖)
Oracle数据库Real Application Testing之Database Replay实操
- 文章快速说明索引
- 数据库回放的演示
- 负载捕获
- 负载处理
- 负载重放
- 分析报告

文章快速说明索引
学习目标:
目的:接下来这段时间我想做一些兼容Oracle数据库Real Application Testing (即:RAT)上的一些功能开发,本专栏这里主要是学习以及介绍Oracle数据库功能的使用场景、原理说明和注意事项等,基于PostgreSQL数据库的功能开发等之后 由新博客进行介绍和分享!
学习内容:(详见目录)
1、Oracle数据库Real Application Testing之Database Replay实操(一)
学习时间:
2023年03月23日 21:48:11
学习产出:
1、Oracle数据库Real Application Testing之Database Replay实操(一)
2、CSDN 技术博客 1篇
注:下面我们所有的学习环境是Centos7+PostgreSQL15.0+Oracle19c+MySQL5.7
postgres=# select version();version
-----------------------------------------------------------------------------PostgreSQL 15.0 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 7.1.0, 64-bit
(1 row)postgres=##-----------------------------------------------------------------------------#SQL> select * from v$version; BANNER BANNER_FULL BANNER_LEGACY CON_ID
--------------------------------------------------------------------------- --------------------------------------------------------------------------- --------------------------------------------------------------------------- ----------
Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production 0Version 19.3.0.0.0SQL>
#-----------------------------------------------------------------------------#mysql> select version();
+-----------+
| version() |
+-----------+
| 5.7.19 |
+-----------+
1 row in set (0.06 sec)mysql>
数据库回放的演示
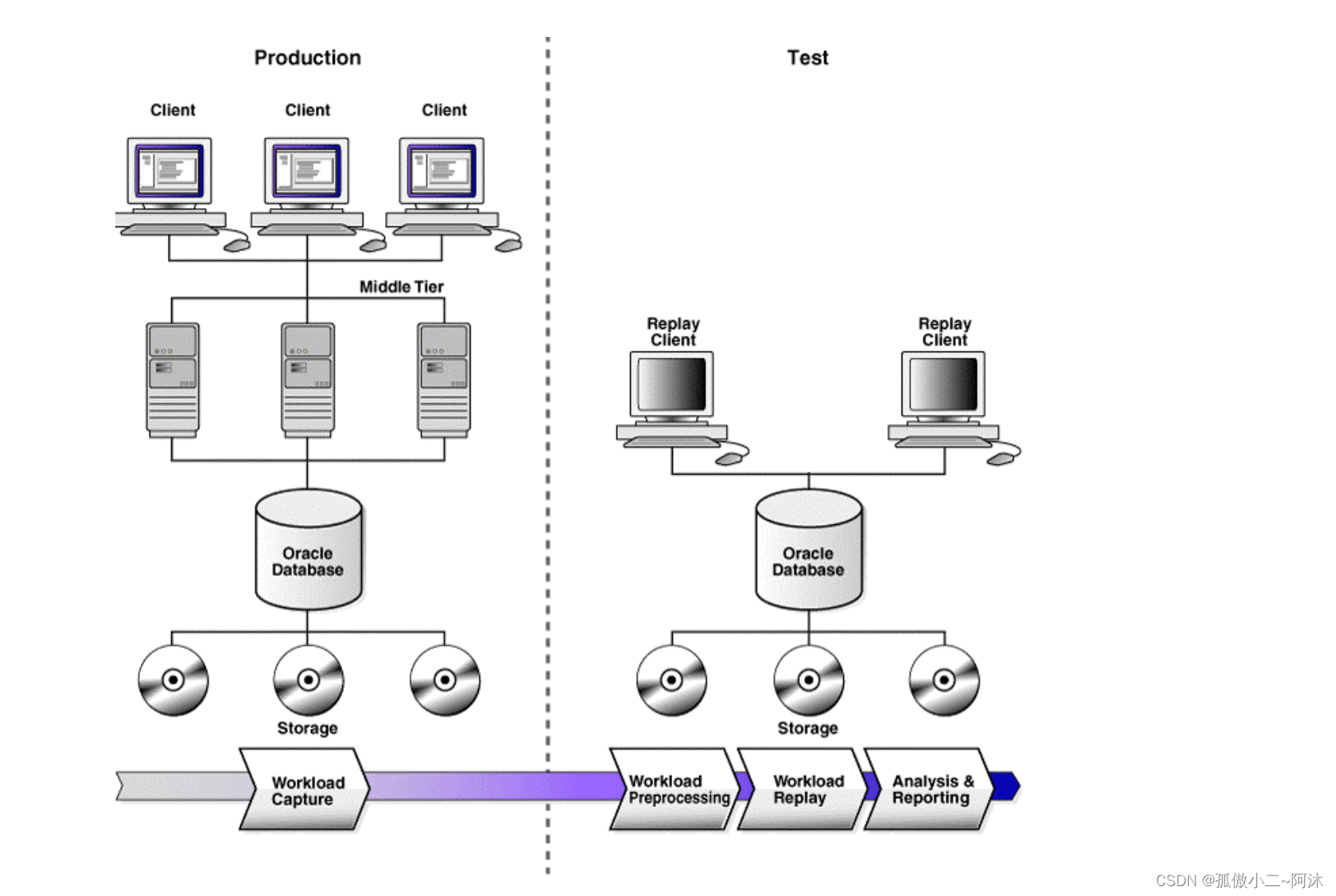
数据库重放由四个主要步骤组成,如上图所示,如下所述:
-
工作负载捕获
启用工作负载捕获后,所有指向 Oracle 数据库的外部客户端请求都将被跟踪并存储在数据库服务器主机文件系统上的二进制文件(称为捕获文件)中。Oracle 建议在捕获负载之前对整个数据库进行备份。用户指定捕获文件的位置以及工作负载捕获的开始和结束时间。在此过程中,与外部数据库调用有关的所有信息都将写入捕获文件
-
工作负载处理
捕获工作负载后,必须处理捕获文件中的信息。此处理将捕获的数据转换为重放文件,并创建重放工作负载所需的所有必要元数据。捕获文件通常会被复制到另一个系统进行处理。在重放之前,必须为每个捕获的工作负载执行一次此操作。捕获的工作负载处理后,可以在重放系统上重复重放。由于工作负载处理可能非常耗时且资源密集,因此通常建议在将重放工作负载的测试系统上执行此步骤
-
工作负载回放
处理完捕获的工作负载后,就可以重放了。然后,名为 Replay Client 的客户端程序处理重播文件,并以与捕获系统完全相同的时间和并发性将调用提交给数据库。根据捕获的工作负载,您可能需要一个或多个重放客户端才能正确重放工作负载。提供了一个校准工具来帮助确定工作负载所需的重播客户端数量。应该注意的是,由于重放了整个工作负载,包括 DML 和 SQL 查询,因此重放系统中的数据必须与捕获其工作负载的生产系统中的数据相同,以便能够为报告目的进行可靠的分析
-
分析和报告
提供了广泛的报告,以便对捕获和重放进行详细分析。报告重放期间遇到的任何错误。显示 DML 或查询返回的行中的任何差异。提供了捕获和回放之间的基本性能比较。对于高级分析,回放比较周期和其他 AWR 报告可用于详细比较捕获和回放之间的各种统计数据
负载捕获
首先建立捕获目录,如下:
[oracle@dbserver ~]$ pwd
/home/oracle
[oracle@dbserver ~]$ mkdir db_replay_capture
[oracle@dbserver ~]$ cd db_replay_capture/
[oracle@dbserver db_replay_capture]$
[oracle@dbserver db_replay_capture]$ pwd
/home/oracle/db_replay_capture
[oracle@dbserver db_replay_capture]$
[oracle@dbserver ~]$ sqlplus / as sysdbaSQL*Plus: Release 19.0.0.0.0 - Production on Thu Mar 23 21:59:36 2023
Version 19.3.0.0.0Copyright (c) 1982, 2019, Oracle. All rights reserved.Connected to:
Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production
Version 19.3.0.0.0SQL> create or replace directory db_replay_capture_dir as '/home/oracle/db_replay_capture';Directory created.SQL>
建立测试表以及插入数据,如下:
SQL> conn c##spa123/spa123
Connected.
SQL>
SQL> create table test (id number, cust_name varchar2(20), dt date, amt number(8,2), store_id number(2));Table created.SQL> create sequence test_id_seq start with 1 maxvalue 99999999999999 minvalue 1 nocycle cache 20;Sequence created.SQL>
注:我们这里测试环境只用一台机器来模拟数据库重放,所以需要先建立一个还原点。
需要先确认是开启了归档模式,如下:
SQL> conn /as sysdba
Connected.-- 如下没有开启归档
SQL> archive log list;
Database log mode No Archive Mode
Automatic archival Disabled
Archive destination /home/oracle/oracle19c/product/19c/dbhome_1/dbs/arch
Oldest online log sequence 77
Current log sequence 79
SQL>
SQL> shutdown immediate
Database closed.
Database dismounted.
ORACLE instance shut down.
SQL> startup mount
ORACLE instance started.Total System Global Area 1157624440 bytes
Fixed Size 9134712 bytes
Variable Size 620756992 bytes
Database Buffers 520093696 bytes
Redo Buffers 7639040 bytes
Database mounted.
SQL> archive log list;
Database log mode No Archive Mode
Automatic archival Disabled
Archive destination /home/oracle/oracle19c/product/19c/dbhome_1/dbs/arch
Oldest online log sequence 77
Current log sequence 79
SQL> alter database archivelog;Database altered.SQL> select flashback_on from v$database;FLASHBACK_ON
------------------
NOSQL> archive log list;
Database log mode Archive Mode
Automatic archival Enabled
Archive destination /home/oracle/oracle19c/product/19c/dbhome_1/dbs/arch
Oldest online log sequence 77
Next log sequence to archive 79
Current log sequence 79
SQL>
SQL> alter system set db_recovery_file_dest_size=5G;System altered.SQL> alter system set db_recovery_file_dest='/home/oracle/flash_recovery_area' scope=both;System altered.SQL> alter system set db_recovery_file_dest_size=60G scope=both;System altered.SQL> alter system set db_flashback_retention_target=4320 scope=both;System altered.SQL> archive log list;
Database log mode Archive Mode
Automatic archival Enabled
Archive destination USE_DB_RECOVERY_FILE_DEST
Oldest online log sequence 77
Next log sequence to archive 79
Current log sequence 79
SQL> alter database flashback on;Database altered.SQL> select flashback_on from v$database;FLASHBACK_ON
------------------
YESSQL>
接下来,建立还原点,如下:
SQL> create restore point mypoint;Restore point created.SQL>
注:因为我们这里想要 capture 所有的信息,就跳过 add_filter 的设置。关于设置过滤器,可以参见本人后面博客的详细介绍!
接下来,就可以开启捕获了,如下:
-- sysdbaSQL> BEGINDBMS_WORKLOAD_CAPTURE.start_capture (name=>'test_capture_1', dir=>'DB_REPLAY_CAPTURE_DIR', duration=> NULL);
END;
/ 2 3 4 PL/SQL procedure successfully completed.SQL>
开始负载模拟,如下:
[oracle@dbserver ~]$ pwd
/home/oracle
[oracle@dbserver ~]$ cat insert_test.sql
declarel_stmt varchar2(2000);
beginfor ctr in 1..1000 loopl_stmt := 'insert into test values ('||test_id_seq.nextval||','||''''||dbms_random.string('U',20)||''','||'sysdate - '||round(dbms_random.value(1,365))||','||round(dbms_random.value(1,999999),2)||','||round(dbms_random.value(1,99))||')';dbms_output.put_line(l_stmt);execute immediate l_stmt;commit;end loop;
end;
/[oracle@dbserver ~]$
SQL> conn c##spa123/spa123
Connected.
SQL> select * from test;no rows selectedSQL> @/home/oracle/insert_test.sqlPL/SQL procedure successfully completed.SQL> select count(*) from test;COUNT(*)
----------1000SQL>
停止捕获,如下:
SQL> conn / as sysdba
Connected.
SQL> BEGINDBMS_WORKLOAD_CAPTURE.finish_capture;
END;
/ 2 3 4 PL/SQL procedure successfully completed.SQL>
查看捕获的目录,如下:
[oracle@dbserver db_replay_capture]$ ls
cap capfiles
[oracle@dbserver db_replay_capture]$ ls cap
wcr_cr.html wcr_cr.text wcr_cr.xml wcr_fcapture.wmd wcr_scapture.wmd
[oracle@dbserver db_replay_capture]$
[oracle@dbserver db_replay_capture]$ ls capfiles/
inst1
[oracle@dbserver db_replay_capture]$ ls capfiles/inst1/
aa ab ac ad ae af ag ah ai aj
[oracle@dbserver db_replay_capture]$
[oracle@dbserver db_replay_capture]$ tree .
.
├── cap
│ ├── wcr_cr.html
│ ├── wcr_cr.text
│ ├── wcr_cr.xml
│ ├── wcr_fcapture.wmd
│ └── wcr_scapture.wmd
└── capfiles└── inst1├── aa│ ├── wcr_1st9dh0000000.rec│ ├── wcr_1st9dh0000001.rec│ └── wcr_1stf7h0000002.rec├── ab├── ac├── ad├── ae├── af├── ag├── ah├── ai└── aj13 directories, 8 files
[oracle@dbserver db_replay_capture]$
此时获取caputre_id,如下:
-- 通过内部函数读取:SQL> select DBMS_WORKLOAD_CAPTURE.get_capture_info('DB_REPLAY_CAPTURE_DIR') FROM dual;DBMS_WORKLOAD_CAPTURE.GET_CAPTURE_INFO('DB_REPLAY_CAPTURE_DIR')
---------------------------------------------------------------1SQL>-- 读取dba_workload_captures视图读取:
SQL> SELECT id, name FROM dba_workload_captures;ID NAME
---------- --------------------------------------------------------------------------------------------------------------------------------1 test_capture_1SQL>
负载处理
注:由于是测试环境、捕获和重放是同一台机器(正式环境下需要将捕获的文件复制到目标机器上),现在将数据库恢复到开始捕获前的状态,如下:
SQL> shutdown immediate;
Database closed.
Database dismounted.
ORACLE instance shut down.
SQL> startup mount;
ORACLE instance started.Total System Global Area 1157624440 bytes
Fixed Size 9134712 bytes
Variable Size 620756992 bytes
Database Buffers 520093696 bytes
Redo Buffers 7639040 bytes
Database mounted.
SQL> flashback database to restore point mypoint;Flashback complete.SQL> alter database open resetlogs;Database altered.SQL>
-- 数据库已闪回SQL> conn c##spa123/spa123
Connected.
SQL> select * from test;no rows selectedSQL>
之后就开始预处理,由于是同一台机器测试的,数据库的目录也不需要重新建立,否则还需要建立目录:
CREATE OR REPLACE DIRECTORY db_replay_capture_dir AS '/home/oracle/db_replay_capture/';
SQL> conn / as sysdba
Connected.
SQL>
SQL> BEGIN
DBMS_WORKLOAD_REPLAY.process_capture('DB_REPLAY_CAPTURE_DIR');
END;
/ 2 3 4 PL/SQL procedure successfully completed.SQL>
这个时候再去看一下目录,上下两次对比 如下:

如上,预处理之后,目录方的中生成了重演的数据,pp19.3.0.0.0的目录
负载重放
这里使用wrc工具进行校验,效验结果会显示完成replay需要replay clients和hosts的数量,如下:
[oracle@dbserver ~]$ wrc mode=calibrate replaydir=/home/oracle/db_replay_captureWorkload Replay Client: Release 19.3.0.0.0 - Production on Thu Mar 23 23:02:49 2023Copyright (c) 1982, 2019, Oracle and/or its affiliates. All rights reserved.Report for Workload in: /home/oracle/db_replay_capture
-----------------------Recommendation:
Consider using at least 1 clients divided among 1 CPU(s)
You will need at least 3 MB of memory per client process.
If your machine(s) cannot match that number, consider using more clients.Workload Characteristics:
- max concurrency: 1 sessions
- total number of sessions: 2Assumptions:
- 1 client process per 100 concurrent sessions
- 4 client processes per CPU
- 256 KB of memory cache per concurrent session
- think time scale = 100
- connect time scale = 100
- synchronization = TRUE[oracle@dbserver ~]$
接下来,开始replay。在上面的效验结果,显示一个CPU上建议一个client,所以我们这里开始一个replay client。
-- 使用 initialize_replay 装载metadata到tables里SQL> EXEC DBMS_WORKLOAD_REPLAY.initialize_replay (replay_name=>'test_capture_1', replay_dir=>'DB_REPLAY_CAPTURE_DIR');PL/SQL procedure successfully completed.SQL>
-- 将数据改成PREPARE REPLAY 模式:SQL> exec DBMS_WORKLOAD_REPLAY.prepare_replay(synchronization=>TRUE);PL/SQL procedure successfully completed.SQL>
-- 检查replay的状态:SQL> select name, status from dba_workload_replays;NAME STATUS
-------------------------------------------------------------------------------------------------------------------------------- ----------------------------------------
test_capture_1 PREPARESQL>
[oracle@dbserver ~]$ wrc system/123456 mode=replay replaydir=/home/oracle/db_replay_capture-- 执行之后,replay client 被暂停,并等待start replay 。 另开一个sqlplus 窗口执行如下命令:
[oracle@dbserver ~]$ sqlplus / as sysdbaSQL*Plus: Release 19.0.0.0.0 - Production on Thu Mar 23 23:16:36 2023
Version 19.3.0.0.0Copyright (c) 1982, 2019, Oracle. All rights reserved.Connected to:
Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production
Version 19.3.0.0.0SQL> exec DBMS_WORKLOAD_REPLAY.START_REPLAY ();PL/SQL procedure successfully completed.SQL> select name,status from dba_workload_replays;NAME STATUS
-------------------------------------------------------------------------------------------------------------------------------- ----------------------------------------
test_capture_1 IN PROGRESSSQL>
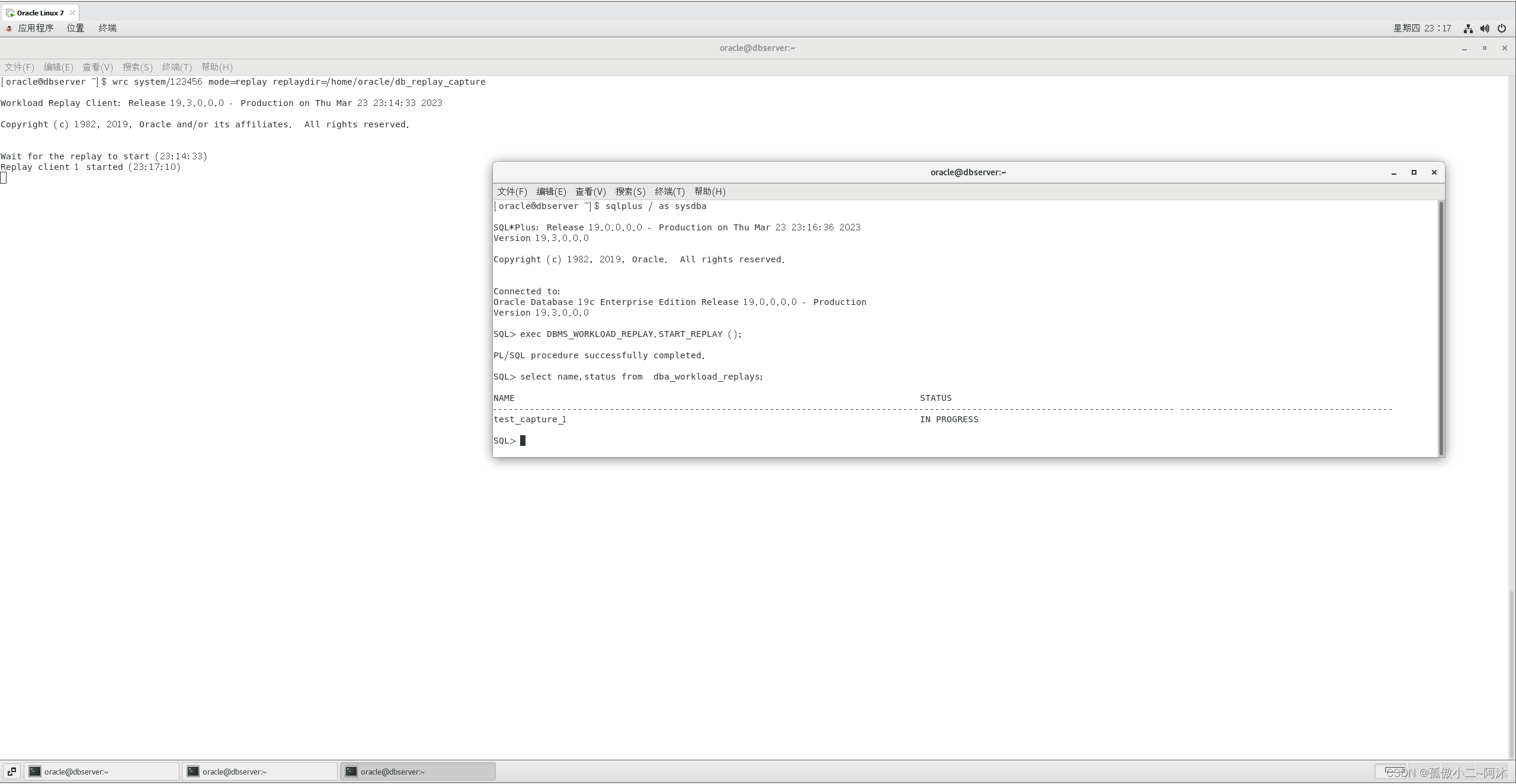
等dba_workload_replays中的状态变成compelte就完成replay。此时replayclient会显示操作开始和结束的时间,如下:
SQL> select name,status from dba_workload_replays;NAME STATUS
-------------------------------------------------------------------------------------------------------------------------------- ----------------------------------------
test_capture_1 COMPLETEDSQL>
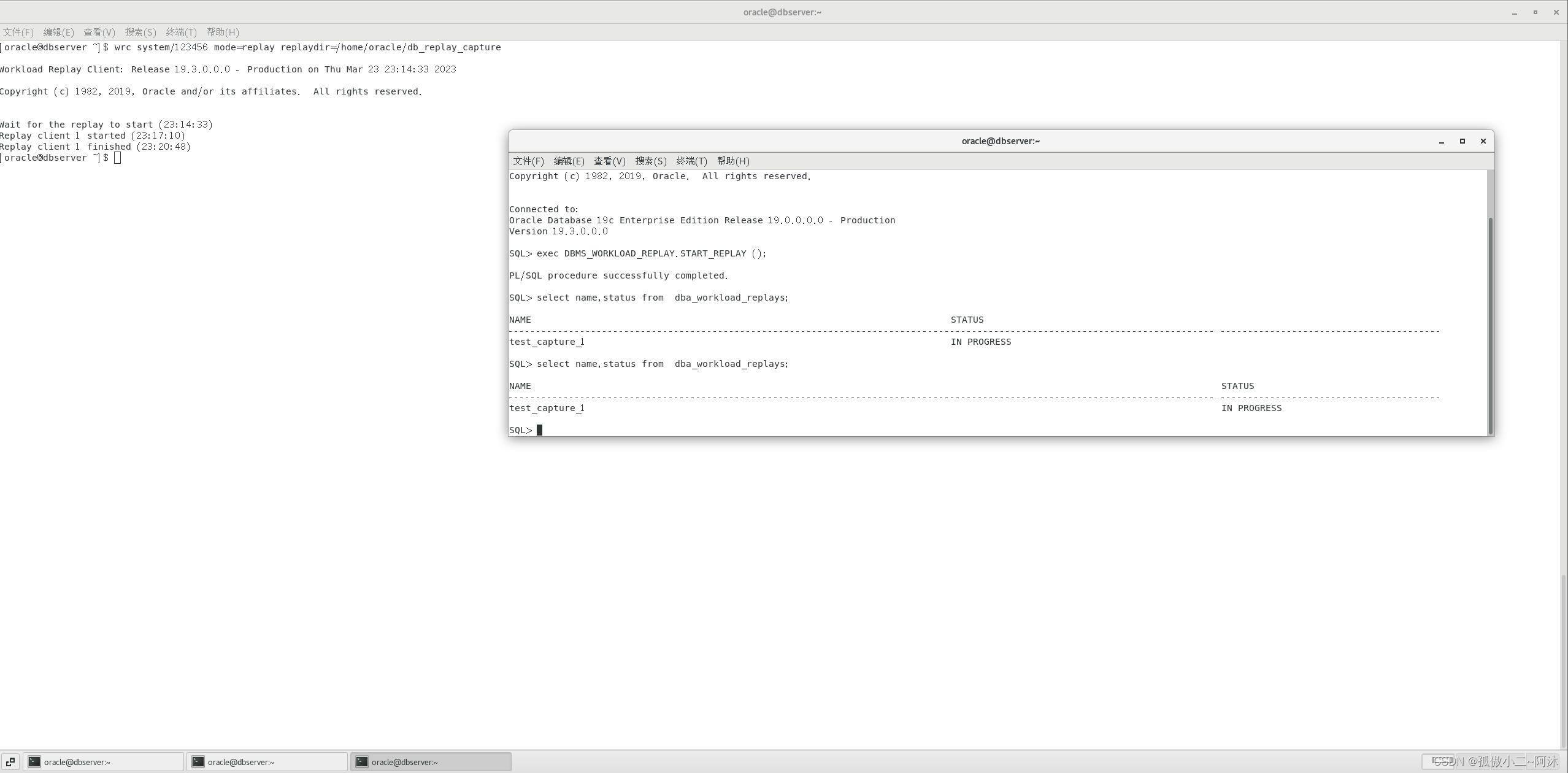
这时就可以验证replay结果,如下:
SQL> conn c##spa123/spa123
Connected.
SQL> select count(*) from test;COUNT(*)
----------1000SQL>
分析报告
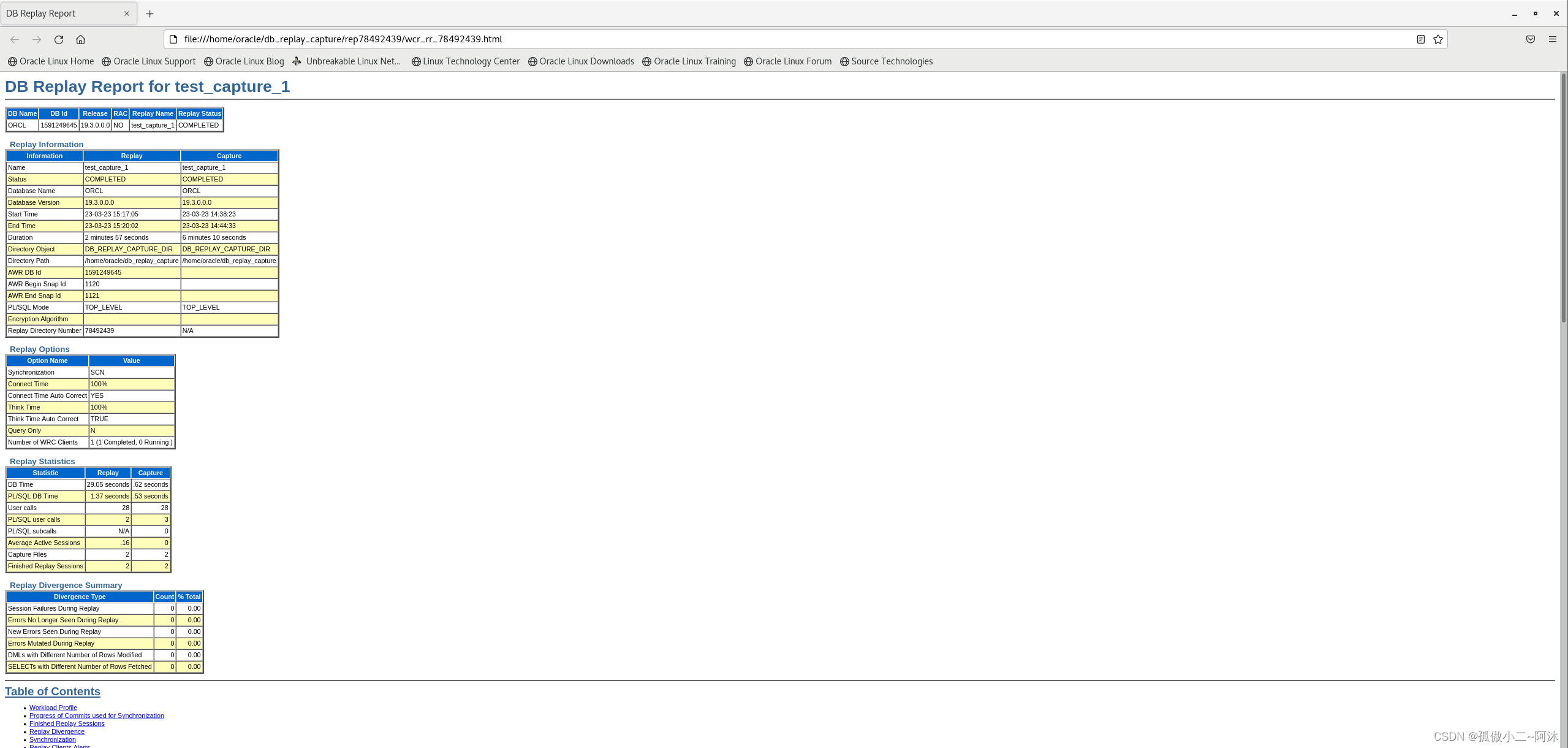
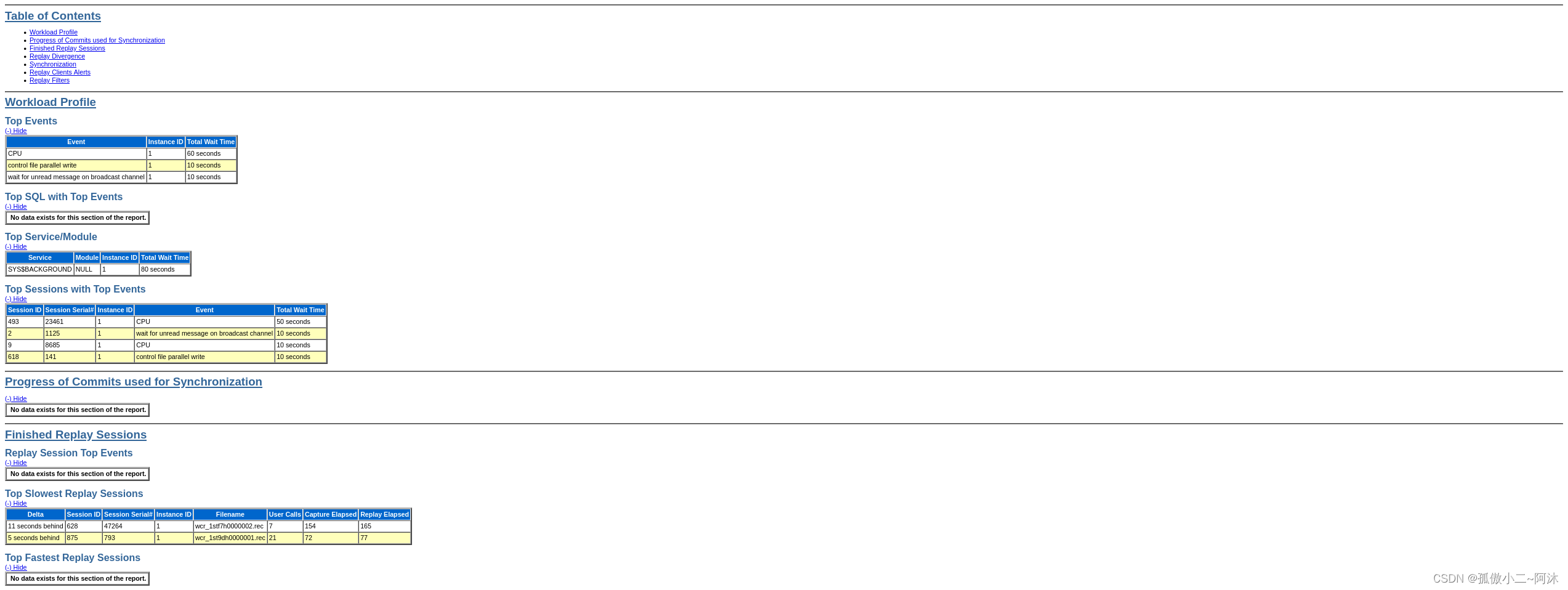
生成报告,如下:
SQL> DECLAREl_report CLOB;
BEGINl_report := DBMS_WORKLOAD_REPLAY.report(replay_id=>1, format=>DBMS_WORKLOAD_REPLAY.TYPE_HTML);
END;
/ 2 3 4 5 6 PL/SQL procedure successfully completed.SQL>
[oracle@dbserver db_replay_capture]$ ls
cap capfiles pp19.3.0.0.0 rep78492439
[oracle@dbserver db_replay_capture]$ ls rep78492439/
wcr_ra_78492439.dmp wcr_ra_78492439.log wcr_replay_div_summary.extb wcr_replay_thread.extb wcr_replay.wmd wcr_rep_uc_graph_78492439.extb wcr_rr_78492439.cc.xml wcr_rr_78492439.html wcr_rr_78492439.txt wcr_rr_78492439.xml wcr_tracked_commits.extb
[oracle@dbserver db_replay_capture]$
如上,目录下面多了rep开头的子目录,html文件就是生成的报告。

这篇关于Oracle的学习心得和知识总结(十三)|Oracle数据库Real Application Testing之Database Replay实操(一)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




