本文主要是介绍从云计算到云原生,服务器的星辰大海在哪儿-数据湾,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
从云计算到云原生,云计算的持续进化给服务器带来了更多的新需求与挑战。
今年以来,受疫情影响和新基建的不断加速推进,越来越多的企业开始选择上云,基于云的各种新产业、新业态、新模式全面爆发。也是在这个时候,云原生开始火了起来,也逐渐在技术人员的眼前开始刷屏。
云原生(Cloud Native)的由来
从简单的字面意思来理解,可以分为云和原生两部分,云的意思大家都了解,在此就不在赘述;原生的意思其实也很好理解,就是土生土长,我们在开始设计应用的时候就考虑到应用将来是运行云环境里面的,要充分利用云资源的优点,比如️云服务的弹性和分布式优势。
云原生的概念最早开始于2010年,在当时Paul Fremantle的一篇博客中被提及,他主要将其描述为一种和云一样的系统行为的应用的编写,比如分布式的、松散的、自服务的、持续部署与测试的。当时提出云原生是为了能构建一种符合云计算特性的标准来指导云计算应用的编写。
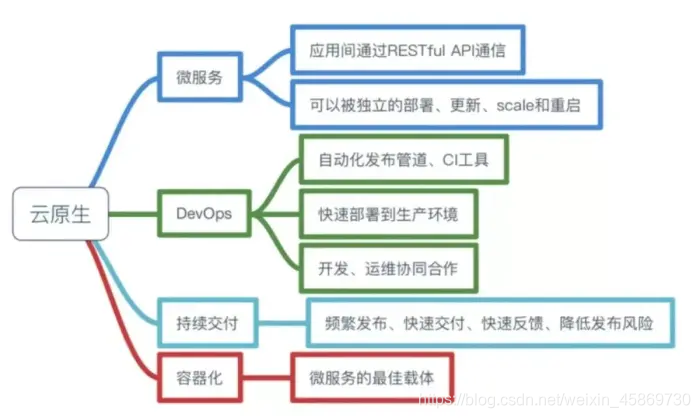
后来到2013年Matt Stine在推特上迅速推广云原生概念,并在2015年《迁移到云原生架构》一书中定义了符合云原生架构的特征:12因素、微服务、自服务、基于API协作、扛脆弱性。而由于这本书的推广畅销,这也成了很多人对云原生的早期印象,同时这时云原生也被12要素变成了一个抽象的概念。
CNCF基金会成立及云原生概念的演化
2015年由Linux基金会发起了一个The Cloud Native Computing Foundation(CNCF)基金组织,CNCF基金会的成立标志着云原生正式进入高速发展轨道,google、Cisco、Docker各大厂纷纷加入,并逐步构建出围绕Cloud Native的具体工具,而云原生这个的概念也逐渐变得更具体化。因此,CNCF基金最初对云原生定义是也是深窄的,当时把云原生定位为容器化封装+自动化管理+面向微服务。
到了2017年,云原生应用的提出者之一的Pivotal在其官网上将云原生的定义概况为DevOps、持续交付、微服务、容器这四大特征,这也成了很多人对Cloud Native的基础印象。
服务器的新需求与新发展
自从互联网巨头争相卖菜被批过后,几捆白菜外,互联网的星辰大海在哪儿也引发大众的思考
锦缎研究员认为服务器是“几捆白菜"外,互联网巨头值得重点布局的领域之一。
如果说要找一个被海外低端锁定的产业链,那服务器当仁不让是最为典型的产品之一:与华为海思涉及到的是高端智能手机芯片牵动每个人的神经不一样,服务器作为互联网的基础设施,与普通消费者并不直接接触,但实际服务器市场所面临的困境对比手机处理器芯片有过之而无不及。
另外一个角度是,服务器最大的需求者就是互联网/云计算公司,他们应具有天然的危机感。
在这一趋势下,传统服务器逐渐表现出机型功能复杂、创新节奏慢、成本压力大、应用周期长等局限性,难以完全满足云计算数据中心场景下对超大规模、需求多样、高性价比、安全可靠以及软硬件一体化等方面的要求。
为此,腾讯云通过持续的技术研发,为云上用户探索最合适的服务器解决方案,星星海首款自研四路服务器正是在这样的背景下横空出世,在四路、双路服务器平台的选择和配置上,腾讯云与英特尔及硬件合作伙伴更是火力全开,展现了互联网定制服务器在配置、性能、可管理性和高可靠层面的顶尖水准。
腾讯云并不是第一个投身互联网定制服务器的行业巨头,但正如后发先至的道理一样,早已看清前路的腾讯云从星星海自研服务器的设计研发开始就展现出了成熟的设计思路和对应用场景需求的精确把控;以应对云原生和人工智能等新技术的应用给计算带来的新要求。
未来的服务器的星辰大海在哪儿,已经有人为我们踏出了一步,能为用户打造更加稳定可靠,高性价比的服务器服务,为用户提供更多优质的选择,让用户将精力投入到主营业务和创新中,进而加速产业智变。
这篇关于从云计算到云原生,服务器的星辰大海在哪儿-数据湾的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







