本文主要是介绍《十堂课学习 Flink SQL》第二章:Flink 基础,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
第二章是关于 Flink 的基础内容。主要包括 Apache Flink 框架概述;Flink 数据流处理和批处理的基本概念;Flink 编程模型;Table 以及 SQL 的简单介绍。本章节核心在于 Flink 的基本原理以及编程模式,不涉及环境搭建以及项目开发。
2.1 Apache Flink 框架概述
2.1.1 什么是 Flink 以及 Flink 的主要特点

Apache Flink 是一个开源的分布式流式处理框架,旨在处理实时大规模数据流。它提供了高吞吐量、低延迟的数据处理能力,适用于处理无界数据流,同时也支持批处理任务。Flink 的设计目标是在分布式环境中实现容错性、高可用性和高性能的流式数据处理。
Flink 的主要特点包括:

以上图片来自官网截图
| 特点 | 描述 |
|---|---|
| Correctness guarantees 正确性保证 | 状态一致性;事件时间处理;成熟的迟到数据处理 |
| Layered APIs 分层 AP I | 基于流 / 批数据的SQL;DataStream API & DataSet API;处理方法ProcessFunction (Time & State) |
| Operational focus 聚焦运维 | 灵活部署;高可用;保存点 |
| Scalability 大规模计算 | 水平扩展架构;支持超大状态;增量检查点机制 |
| Performance 性能卓越 | 低延迟;高吞吐;内存计算 |
2.1.2 Flink 工作原理以及主要工作方式
Apache Flink 的工作原理涉及多个关键组件和步骤,以下是 Flink 的基本工作流程:
-
作业提交:
- 用户通过 Flink API 编写数据处理程序,形成一个 Flink 作业。这个作业定义了数据的输入源、转换操作和输出目的地。
- 用户将作业提交给 Flink 集群,可以通过命令行工具、REST API 或 Flink Web UI 进行提交。
-
作业图构建:
- Flink 将用户提交的作业转化为一个逻辑执行图,也称为 JobGraph。JobGraph 包括了作业的任务(Tasks)和任务之间的数据流。
-
任务划分与调度:
- JobGraph 被拆分为多个任务,这些任务是作业中实际执行的最小单元。任务的划分通常根据数据流的拓扑结构和并行度进行。
- 任务调度器负责将这些任务分配到 Flink 集群中的 TaskManager 节点上执行。
-
任务执行:
- 每个 TaskManager 负责执行一个或多个任务。任务按照指定的并行度运行,处理输入数据并执行用户定义的操作符。
- 数据流在任务之间流动,触发相应的转换操作。这可以包括数据的过滤、映射、窗口操作等。
-
状态管理:
- Flink 允许在任务执行过程中维护状态信息。状态可以是键控状态(针对特定 key 的状态)或操作符状态(全局状态)。
- Flink 使用状态后端来管理和存储任务的状态,确保在发生故障时可以进行恢复。
-
检查点(Checkpoint):
- 为了实现容错性,Flink 引入了检查点机制。定期生成检查点,保存任务的状态。检查点可以存储在分布式文件系统中,以便在发生故障时进行恢复。
-
容错与故障恢复:
- 当 TaskManager 节点发生故障时,Flink 使用检查点来确保作业的状态能够被还原。系统会选择最近的检查点,然后重新启动失败的任务。
-
数据源与连接器:
- Flink 可以与各种数据源和系统集成,包括 Apache Kafka、Apache Hadoop、Elasticsearch 等。连接器允许 Flink 无缝地读取和写入不同的数据存储。
-
任务完成与结果输出:
- 一旦任务完成,Flink 将结果输出到指定的目的地,可以是文件系统、数据库或其他存储系统。
- 用户可以监控作业的进度和性能,查看日志以进行故障排除,这可以通过 Flink Web UI 或其他监控工具完成。
2.2 Flink 数据流处理与批处理

在自然环境中,数据的产生原本就是流式的。无论是来自 Web 服务器的事件数据,证券交易所的交易数据,还是来自工厂车间机器上的传感器数据,其数据都是流式的。但是当你分析数据时,可以围绕有界流(bounded)或 无界流(unbounded)两种模型来组织处理数据,当然,选择不同的模型,程序的执行和处理方式也都会不同。
批处理是有界数据流处理的范例。在这种模式下,你可以选择在计算结果输出之前输入整个数据集,这也就意味着你可以对整个数据集的数据进行排序、统计或汇总计算后再输出结果。
流处理 正相反,其涉及无界数据流。至少理论上来说,它的数据输入永远不会结束,因此程序必须持续不断地对到达的数据进行处理。
在 Flink 中,应用程序由用户自定义算子转换而来的流式 data flows 所组成。这些流式 data flows 形成了有向图,以一个或多个源(source)开始,并以一个或多个汇(sink)结束。

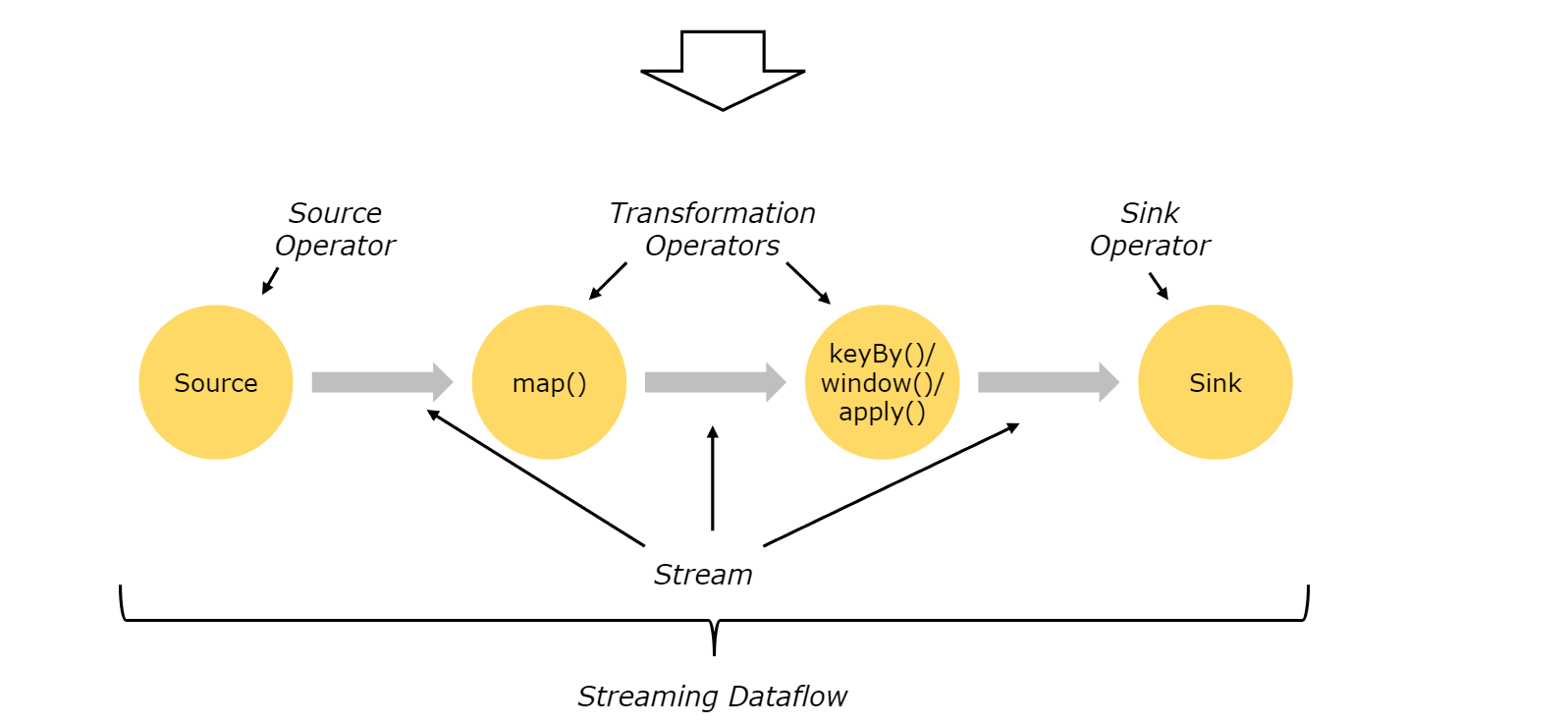
事实上,第一章中提到过,Flink 的一个优点在于 流批一体,结合上面的代码可以看出,Flink 处理流数据或批数据的方法基本是一致的。所谓的流处理以及批处理更加强调的是处理的数据特点:有界数据流(批处理)、无界数据流(流处理)。
2.3 Flink 编程模型
Apache Flink 提供了两种主要的编程模式:批处理模式(Batch Processing)和流处理模式(Stream Processing)。这两种模式在 Flink 中有不同的 API 和用法。
1. 批处理模式(Batch Processing):
在批处理模式下,Flink 处理有界的数据集,类似于传统的批处理作业。主要的 API 是 DataSet API。
- DataSet API:
- 使用
ExecutionEnvironment创建一个批处理的执行环境。 - 通过
readTextFile、fromCollection等方法读取有界的数据集。 - 应用一系列的转换操作,例如
map、filter、reduce等,来对数据进行处理。 - 最后使用
writeAsText、writeToSocket等方法将结果输出。
- 使用
// 注意:以下的代码都属于是伪代码,不能够直接执行。
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSet<String> input = env.readTextFile("path/to/input");
DataSet<Integer> result = input.map(s -> Integer.parseInt(s)).filter(i -> i % 2 == 0).reduce((i1, i2) -> i1 + i2);result.writeAsText("path/to/output");
env.execute("Batch Processing Job");
2. 流处理模式(Stream Processing):
在流处理模式下,Flink 处理无界的数据流,支持实时数据处理。主要的 API 是 DataStream API。
- DataStream API:
- 使用
StreamExecutionEnvironment创建一个流处理的执行环境。 - 通过
addSource、socketTextStream等方法定义数据源。 - 应用一系列的转换操作,例如
map、filter、keyBy、window等,来对数据进行处理。 - 最后使用
print、writeToSocket、addSink等方法将结果输出。
- 使用
// 注意:以下的代码都属于是伪代码,不能够直接执行。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> input = env.socketTextStream("localhost", 9999);
DataStream<Integer> result = input.map(s -> Integer.parseInt(s)).filter(i -> i % 2 == 0).keyBy(i -> i % 5).timeWindow(Time.seconds(10)).sum("value");result.print();
env.execute("Stream Processing Job");
在这两种模式下,Flink 提供了类似的操作符,但是在流处理模式下,还引入了一些用于处理无界数据流的新概念,如窗口操作和事件时间处理。用户可以根据任务需求选择合适的编程模式。此外,Flink 还提供了 Table API 和 SQL API,使得用户可以使用类似 SQL 的语法进行数据处理。
2.4 Table API & SQL 介绍
Apache Flink Table API 是一个基于关系型查询的 API,允许用户使用类似 SQL 的语法对数据进行查询和转换。Table API 提供了一种更高层次、更声明式的方式来定义数据处理逻辑,而不需要显式地编写低级的转换和函数。
以下是 Flink Table API 的一些关键特点和用法:
-
声明式查询语法:
- 使用 Table API,用户可以通过声明式的查询语法来表达数据处理逻辑,类似于 SQL 查询语句。这使得代码更易读、更易理解。
-
集成 SQL:
- Flink Table API 与 Flink SQL 紧密集成,允许用户在代码中嵌入 SQL 查询。这使得开发者可以根据任务需求选择使用 Table API 或直接使用 SQL。
-
数据源和目的地:
- Table API 支持各种数据源和目的地,包括文件系统、Apache Kafka、Apache HBase 等。用户可以通过简单的 API 调用来连接和操作这些数据源。
-
流处理和批处理一致性:
- Table API 支持流处理和批处理一致的编程模型。用户可以在同一份代码中定义处理逻辑,并根据作业的输入源选择相应的执行模式。
-
内置函数和操作符:
- Table API 提供了丰富的内置函数和操作符,例如聚合函数、窗口操作、时间处理等,使用户能够轻松完成各种常见的数据处理任务。
-
集成现有代码:
- 开发者可以在 Table API 中集成已有的 Flink DataStream 或 DataSet 代码,实现更灵活的混合编程。
下面是一个简单的示例,演示如何使用 Flink Table API 对流数据进行查询:
// 注意:以下的代码都属于是伪代码,不能够直接执行。
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);// 创建一个DataStream
DataStream<MyEvent> inputStream = env.addSource(new MyEventSource());// 将DataStream注册为表
Table myTable = tableEnv.fromDataStream(inputStream, "timestamp, user, product");// 使用Table API进行查询
Table resultTable = myTable.groupBy("user").select("user, product.count as itemCount");// 将结果输出到Sink
tableEnv.toRetractStream(resultTable, Row.class).print();env.execute("Table API Example");
这个示例演示了如何使用 Table API 对流数据进行分组、聚合,并输出结果。 Table API 提供了更高层次的抽象,使得开发者能够以一种更直观的方式进行数据处理。
以上的代码主要意图在于简单描述编程模型,均不能正常执行,后面的章节我们以示例的方式详细介绍。
2.5 本章小结
第二章节仍然是准备过程,相关的知识储备非常重要,不一定要求能背诵,但是略微了解、有点印象对于接下来的进一步学习很有作用。此外也是面试官喜欢问的问题。原因很简单,面试官无法让你现场秀一段代码,但是可以通过询问这些问题看看应聘者的基础是否扎实。一般通过这一关以后,才会继续问项目开发相关的内容,让应聘者描述一下自己负责的项目以及主要的架构与技术等等。
Smileyan
2023.11.25 0:45
这篇关于《十堂课学习 Flink SQL》第二章:Flink 基础的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





