本文主要是介绍搭贝--钉钉、企微考勤数据获取,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、 功能介绍
考勤数据同步插件可以通过定时业务规则将企业微信、钉钉考勤相关数据同步到搭贝表单中。
- 钉钉签到记录同步:可以方便快捷的将钉钉中的签到数据同步到表单中。
- 钉钉考勤请假同步:可以方便快捷的将钉钉中的考勤请假数据同步到表单中。
- 钉钉考勤打卡同步:可以方便快捷的将钉钉中的考勤打卡数据同步到表单中。
- 钉钉用户考勤数据同步:获取用户的考勤打卡数据,获取的打卡信息中包含用户 打卡地址 和 备注信息 。
- 钉钉每日考勤统计同步:将钉钉考勤统计「每日汇总」中的数据同步到搭贝的表单。
- 企微打卡同步:可以方便快捷的将企微中的考勤打卡数据同步到表单中。
2、同步数据介绍
2.1 钉钉签到记录同步
插件获取到的钉钉签到记录数据如下表所示:
| 名称 | 内容含义 |
|---|---|
| 签到时间 | 日期时间 类型:年-月-日 时:分:秒,最终根据对应的日期组件设置的格式进行展示。 |
| 签到照片URL地址 | 单行文本、多行文本;多个地址使用分号进行隔开 |
| 签到详细地址 | 单行文本、多行文本 |
| 备注 | 单行文本、多行文本 |
| 签到成员 | 1、单行文本、多行文本:只显示人名 2、人员单选:如返回的用户 UserID 可以和搭贝中获取的钉钉用户 UserID 对上,则认为此成员为有效数据,可在组件中正常显示并用作业务处理;否则为无效数据,不在组件中正常显示无法用作业务处理中。 |
| 签到地址 | 单行文本、多行文本 |
| 拜访对象 | 单行文本、多行文本 |
2.2 钉钉考勤请假同步
插件获取到的钉钉考勤打卡数据如下表所示:
| 名称 | 内容含义 | 支持赋值的表单字段类型 |
|---|---|---|
| 请假单位 | 请假单位: ● 天 ● 小时 | 1、单行文本、多行文本 2、下拉单选:如果赋值为下拉选项中的内容则选项呈现选中状态,如果选项有重复,则选中排序第一个的值;如果不是选项值,则只赋值即可。 |
| 请假时长 | 假期时长,结合请假单位来计算;例如 1天,1小时 | 日期时间 类型:年-月-日 时:分:秒,最终根据对应的日期组件设置的格式进行展示。 |
| 请假结束时间 | - | 日期时间 类型:年-月-日 时:分:秒,最终根据对应的日期组件设置的格式进行展示。 |
| 请假开始时间 | - | 1、单行文本、多行文本 2、下拉单选:如果赋值为下拉选项中的内容则选项呈现选中状态,如果选项有重复,则选中排序第一个的值;如果不是选项值,则只赋值即可。 |
| 请假成员 | - | 1、单行文本、多行文本:只显示人名 2、人员单选:如返回的用户 UserID 可以和搭贝中获取的钉钉用户 UserID 对上,则认为此成员为有效数据,可在组件中正常显示并用作业务处理;否则为无效数据,不在组件中正常显示无法用作业务处理中。 |
2.3 钉钉考勤打卡同步
钉钉考勤打卡结果记录同步插件,用于获取企业内员工的实际打卡结果。
例如,企业给一个员工设定的排班是上午9点和下午6点各打一次卡,即使员工在这期间打了多次,本接口也只会返回两条记录,包括上午的打卡结果和下午的打卡结果,结果中不包含用户打卡地址和备注信息,如果需要包含请使用「钉钉用户考勤数据统计」。
插件获取到的钉钉考勤打卡数据如下表所示:
| 名称 | 内容含义 | 支持赋值的表单字段类型 |
|---|---|---|
| 打卡记录 ID | 打卡记录 ID/ bssid | 单行文本/数字/多行文本 |
| 打卡数据来源 | 打卡数据来源: ● 考勤机 ● IBeacon ● 钉钉考勤机 ● 用户打卡 ● 老板改签 ● 审批系统 ● 考勤系统 ● 自动打卡 | 1、单行文本、多行文本 2、下拉单选:如果赋值为下拉选项中的内容则选项呈现选中状态,如果选项有重复,则选中排序第一个的值;如果不是选项值,则只赋值即可。 |
| 考勤基准时间 | 计算迟到和早退,基准时间 | 日期时间 类型:年-月-日 时:分:秒,最终根据对应的日期组件设置的格式进行展示。 |
| 实际考勤打卡时间 | 实际打卡时间, 用户打卡时间的毫秒数 | 日期时间 类型:年-月-日 时:分:秒,最终根据对应的日期组件设置的格式进行展示。 |
| 考勤位置 | 位置结果: ● 范围内 ● 范围外 ● 未打卡 | 1、单行文本、多行文本 2、下拉单选:如果赋值为下拉选项中的内容则选项呈现选中状态,如果选项有重复,则选中排序第一个的值;如果不是选项值,则只赋值即可。 |
| 打卡结果 | 打卡结果: ● 正常 ● 早退 ● 迟到 ● 严重迟到 ● 旷工迟到 ● 未打卡 | 1、单行文本、多行文本 2、下拉单选:如果赋值为下拉选项中的内容则选项呈现选中状态,如果选项有重复,则选中排序第一个的值;如果不是选项值,则只赋值即可。 |
| 考勤类型 | 考勤类型: ● 上班 ● 下班 | 1、单行文本、多行文本 2、下拉单选:如果赋值为下拉选项中的内容则选项呈现选中状态,如果选项有重复,则选中排序第一个的值;如果不是选项值,则只赋值即可。 |
| 打卡成员 | 打卡人的 UserID | 1、单行文本、多行文本:只显示人名 2、人员单选:如返回的用户 UserID 可以和搭贝中获取的钉钉用户 UserID 对上,则认为此成员为有效数据,可在组件中正常显示并用作业务处理;否则为无效数据,不在组件中正常显示无法用作业务处理中。 |
| 工作日 | 工作日 | 日期时间 类型:年-月-日,最终根据对应的日期组件设置的格式进行展示。 |
| 排班 ID | 排班 ID | 单行文本/数字/多行文本 |
| 考勤组 ID | 考勤组 ID | 单行文本/数字/多行文本 |
| 唯一标识 ID | 唯一标识 ID | 单行文本/数字/多行文本 |
2.4 钉钉用户考勤数据同步
获取用户的考勤打卡数据,获取的打卡信息中包含用户 打卡地址 和 备注信息 。
插件获取到的钉钉考勤打卡数据如下表所示:
| 名称 | 内容含义 | 支持赋值的表单字段类型 |
|---|---|---|
| 外勤备注 | 打卡时的备注信息,如拜访客户 | 单行文本/多行文本 |
| 用户打卡地址 | 打卡用户实际打卡地址 | 单行文本/多行文本 |
| 打卡数据来源 | 打卡数据来源: ● 考勤机 ● IBeacon ● 钉钉考勤机 ● 用户打卡 ● 老板改签 ● 审批系统 ● 考勤系统 ● 自动打卡 | 1、单行文本、多行文本 2、下拉单选:如果赋值为下拉选项中的内容则选项呈现选中状态,如果选项有重复,则选中排序第一个的值;如果不是选项值,则只赋值即可。 |
| 考勤基准时间 | 计算迟到和早退,基准时间 | 日期时间 类型:年-月-日 时:分:秒,最终根据对应的日期组件设置的格式进行展示。 |
| 实际考勤打卡时间 | 实际打卡时间, 用户打卡时间的毫秒数 | 日期时间 类型:年-月-日 时:分:秒,最终根据对应的日期组件设置的格式进行展示。 |
| 考勤位置 | 位置结果: ● 范围内 ● 范围外 ● 未打卡 | 1、单行文本、多行文本 2、下拉单选:如果赋值为下拉选项中的内容则选项呈现选中状态,如果选项有重复,则选中排序第一个的值;如果不是选项值,则只赋值即可。 |
| 打卡结果 | 打卡结果: ● 正常 ● 早退 ● 迟到 ● 严重迟到 ● 旷工迟到 ● 未打卡 | 1、单行文本、多行文本 2、下拉单选:如果赋值为下拉选项中的内容则选项呈现选中状态,如果选项有重复,则选中排序第一个的值;如果不是选项值,则只赋值即可。 |
| 考勤类型 | 考勤类型: ● 上班 ● 下班 | 1、单行文本、多行文本 2、下拉单选:如果赋值为下拉选项中的内容则选项呈现选中状态,如果选项有重复,则选中排序第一个的值;如果不是选项值,则只赋值即可。 |
| 打卡成员 | 打卡人的 UserID | 1、单行文本、多行文本:只显示人名 2、人员单选:如返回的用户 UserID 可以和搭贝中获取的钉钉用户 UserID 对上,则认为此成员为有效数据,可在组件中正常显示并用作业务处理;否则为无效数据,不在组件中正常显示无法用作业务处理中。 |
| 打卡流水ID | 单行文本/数字/多行文本 | |
| 班次ID | 班次ID | 单行文本/数字/多行文本 |
| 排班 ID | 排班 ID | 单行文本/数字/多行文本 |
| 考勤组 ID | 考勤组 ID | 单行文本/数字/多行文本 |
| 审批单ID | 单行文本/多行文本 |
2.5 钉钉每日考勤统计同步
钉钉考勤统计同步插件,获取钉钉智能考勤报表「每日汇总」的列值数据,其中包含了一定时间段内报表某一列的所有数据,以及相关的列信息。
注意:
- 1、如果获取考勤报表列值,返回的应出勤天数为0,则是因为应出勤天数字段,目前只支持获取距今天15内的值。
- 2、一次性最多同步20 列的数据。
 |
插件获取到的钉钉每日考勤统计数据如下表所示:
| 名称 | 字段描述 | 支持赋值的表单字段类型 |
|---|---|---|
| 考勤人员 | 考勤人姓名 | 人员单选 |
| 考勤日期 | 日期,格式为 年月日,具体展示形式根据字段实际设置的格式有关。 | |
| 应出勤天数 | 计为应出勤的天数 | 数字 |
| 补卡次数 | 已通过的补卡次数 | 数字 |
| 出勤班次 | 当天所上的班次 | 数字 |
| 出勤天数 | 计为出勤的天数 | 数字 |
| 休息天数 | 排班为休息的天数 | 数字 |
| 工作时长 | 打卡的时长 | 数字,设置保留小数后两位 |
| 迟到次数 | 计为迟到的次数 | 数字 |
| 迟到时长 | 计为迟到的时长 | 数字 ,设置保留小数后两位 |
| 严重迟到次数 | 计为严重迟到的次数 | 数字 |
| 严重迟到时长 | 计为严重迟到的时长 | 数字,设置保留小数后两位 |
| 旷工迟到次数 | 计为旷工迟到的次数 | 数字 |
| 早退次数 | 计为早退的次数 | 数字 |
| 早退时长 | 计为早退的时长 | 数字,设置保留小数后两位 |
| 上班缺卡次数 | 上班结果为缺卡的次数 | 数字 |
| 下班缺卡次数 | 下班结果为缺卡的次数 | 数字 |
| 旷工天数 | 计为旷工的天数 | 数字 |
| 出差时长 | 计为出差的总时长 | 数字,设置保留小数后两位 |
| 外出时长 | 计为外出的总时长 | 数字,设置保留小数后两位 |
| 事假 | 数字,设置保留小数后两位 | |
| 调休 | 数字 ,设置保留小数后两位 | |
| 病假 | 数字 ,设置保留小数后两位 | |
| 年假 | 数字 ,设置保留小数后两位 | |
| 产假 | 数字,设置保留小数后两位 | |
| 陪产假 | 数字,设置保留小数后两位 | |
| 婚假 | 数字,设置保留小数后两位 | |
| 例假 | 数字,设置保留小数后两位 | |
| 丧假 | 数字,设置保留小数后两位 | |
| 哺乳假 | 数字,设置保留小数后两位 | |
| 加班-审批单统计 | 按照审批单,统计计为加班的总时长 | 数字 |
| 工作日加班 | 数字 | |
| 休息日加班 | 数字 | |
| 节假日加班 | 数字 | |
| 考勤结果 | 每天的打卡结果 | 单行文本、多行文本 |
| 班次 | 当天所排的班次 | 单行文本、多行文本 |
| 上班1打卡时间 | 日期,格式:年月日时分 | |
| 上班1打卡结果 | 单行文本、多行文本 | |
| 下班1打卡时间 | 日期,格式:年月日时分 | |
| 下班1打卡结果 | 单行文本、多行文本 | |
| 上班2打卡时间 | 日期,格式:年月日时分 | |
| 上班2打卡结果 | 单行文本、多行文本 | |
| 下班2打卡时间 | 日期,格式:年月日时分 | |
| 下班2打卡结果 | 单行文本、多行文本 | |
| 上班3打卡时间 | 日期,格式:年月日时分 | |
| 上班3打卡结果 | 单行文本、多行文本 | |
| 下班3打卡时间 | 日期,格式:年月日时分 | |
| 下班3打卡结果 | 单行文本、多行文本 | |
| 关联的审批单 | 请假、出差、补卡等关联到考勤的审批单 | 单行文本、多行文本 |
| 旷工迟到天数 | 计为旷工迟到的次数 | 数字 |
| 用户自己添加的字段 | 用户使用钉钉专业版时自行新增的报表字段 | 单行文本 |
2.6 企微打卡同步
插件获取到的企业微信打卡数据如下表所示:
| 名称 | 内容含义 | 支持赋值的表单字段类型 |
|---|---|---|
| 打卡成员 | 接收企业微信打卡数据中的成员信息 | 人员单选:如返回的用户可以和搭贝中获取的企微用户对上,则认为此成员为有效数据,可在组件中正常显示并用作业务处理;否则为无效数据,不在组件中正常显示无法用作业务处理中。 |
| 打卡组名称 | 接收企业微信打卡规则中的规则名称信息 | 单行文本、多行文本 |
| 打卡类型 | 目前有:上班打卡,下班打卡,外出打卡 | 1、单行文本、多行文本 2、下拉单选:如果赋值为下拉选项中的内容则选项呈现选中状态,如果选项有重复,则选中排序第一个的值;如果不是选项值,则只赋值即可。 |
| 异常类型 | 异常类型,字符串,包括: ● 时间异常 ● 地点异常 ● 未打卡 ● wifi异常 ● 非常用设备。 如果有多个异常,以分号间隔 | 1、单行文本、多行文本 2、下拉单选:如果赋值为下拉选项中的内容则选项呈现选中状态,如果选项有重复,则选中排序第一个的值;如果不是选项值,则只赋值即可。 |
| 打卡时间 | 实际打卡时间 | 日期时间(精确到时分秒),最终根据对应的日期组件设置的格式进行展示。 |
| 标准打卡时间 | 标准打卡时间,指此次打卡时间对应的标准上班时间或标准下班时间 | 日期时间(精确到时分秒),最终根据对应的日期组件设置的格式进行展示。 |
| 打卡地点 | 实际打卡地点 | 单行文本、多行文本 |
| 打卡地点详情 | 打卡地点详情 | 单行文本、多行文本 |
| 打卡WI-FI名称 | 打卡WI-FI名称 | 单行文本、多行文本 |
| 打卡的 MAC 地址 | 打卡的 MAC 地址/ bssid | 单行文本、多行文本 |
| 打卡备注 | 打卡时添加的备注信息 | 单行文本、多行文本 |
| 打卡设备 ID | 如果管理员设置了打卡设备,通过设备打卡的成员会同步设备 ID | 单行文本、多行文本 |
| 打卡组 ID | 根据打卡组名称生成的唯一识别性打卡组 ID | 数字、单行文本、多行文本 |
| 班次 ID | 表示打卡记录所属规则中,所属班次的 ID;如果打卡规则设置的是「按班次上下班」进行打卡的话,每个班次会生成一个唯一性班次 ID | 数字、单行文本、多行文本 |
| 时段 ID | 如果打卡规则设置的是「按班次上下班」进行打卡的话,此 ID表示某一班次中的某一时段的ID,如上下班时间为9:00-12:00、13:00-18:00的班次中,9:00-12:00为其中一组时段 | 数字、单行文本、多行文本 |
3、使用前的配置
3.1 钉钉考勤类插件使用
在安装钉钉考勤类插件之后,需要配置「钉钉企业CorpID」「AppKey」「AppSecret」;
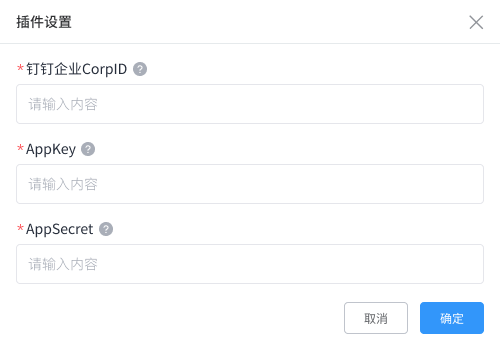 |
- 钉钉企业CorpID:同步的钉钉企业 CorpID,默认为当前账号所在的企业;
- AppKey:在钉钉开放平台中创建钉钉自建应用,内有 AppKey;
- AppSecret:在钉钉开放平台中创建的钉钉自建应用,内有 AppSecret;
钉钉自建应用的创建步骤:
1、首先管理员需要 PC 端登录 钉钉开发者后台 ,选择「应用开发 >> 企业内部开发 >> 钉钉应用」,点击「创建应用」。如下图所示:

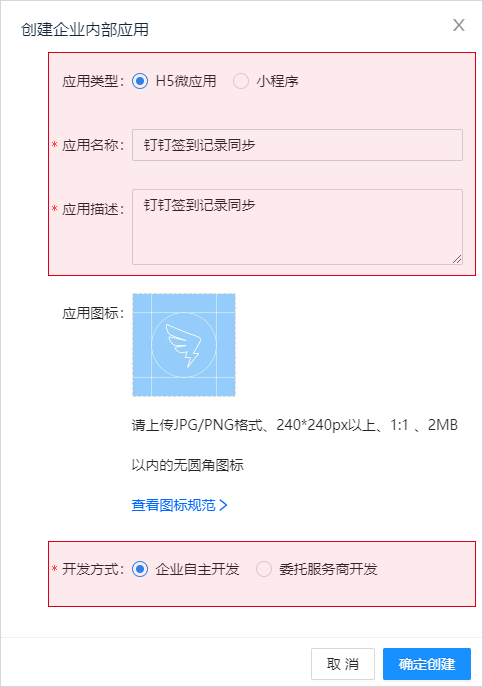
2、选择应用类型为「H5微应用」,填写应用名称和应用描述,选择开发方式为「企业自助开发」。如下图所示:
3、打开该应用,点击「权限管理」,为该应用申请「签到」「考勤」下的所有权限,如下图所示:


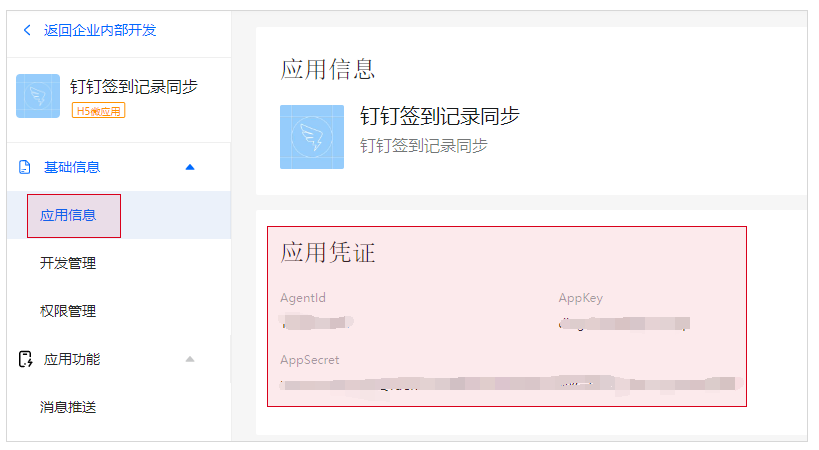
4、记录下创建的应用的 Appkey 和 AppSecret ,插件配置时需要填写。如下图所示:
5、在首页中记录下组织的 CorpId ,在暗安装完插件之后需要填写在插件配置中,如下图:

3.2 企微考勤插件
在企微上使用考勤插件无需配置,只需要安装开启即可。
4、使用方法
业务规则触发动作增加「定时重复」「定时单次」,根据设置的触发时间自动触发业务规则进行考勤数据同步。一个业务规则只能使用一个考勤类插件。
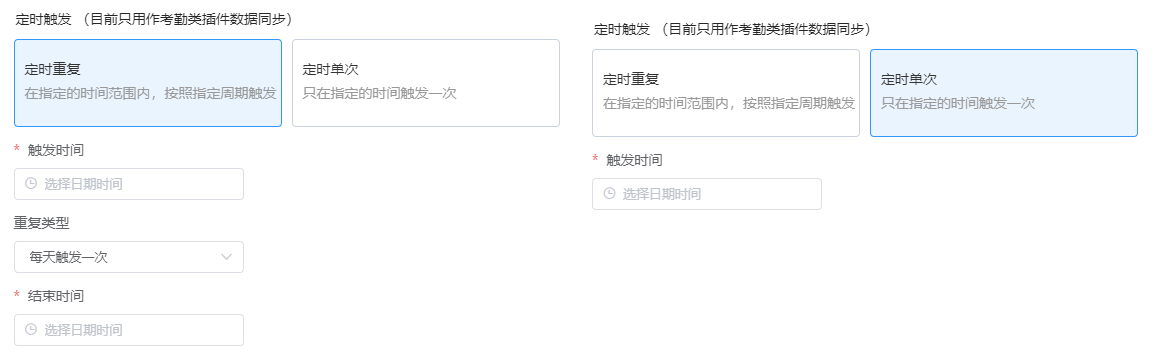 |
- 触发时间:设定第一次同步的时间。
- 重复周期:则按照设定的周期进行重复触发。
- 结束时间:按周期重复同步,直到结束时间为止。
这篇关于搭贝--钉钉、企微考勤数据获取的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






