本文主要是介绍致力技术民主化,开源新贵BigDL的进阶之路,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
人工智能正在改变着各行各业。英特尔资深首席工程师,大数据技术全球CTO戴金权,将就开源、大数据、深度学习等话题分享英特尔在人工智能方面所做的工作。本文会介绍英特尔在大数据分析、深度学习开源软件方面的研究,以及英特尔是如何推动AI技术民主化,让行业更方便地使用人工智能技术。

英特尔资深首席工程师,大数据技术全球CTO戴金权发表主题演讲《AI民主化——开源,大数据和深度学习》
近年来,Spark已经成为了业内大数据处理分析的主流计算框架,它有大量的组件来提供丰富的功能。BigDL是英特尔在Spark上构建的一个面向Apache Spark的开源、分布式的深度学习框架。英特尔希望将深度学习和大数据平台相结合,提供一个统一的大数据分析平台,使深度学习更易于一般的大数据用户和数据科学家使用。
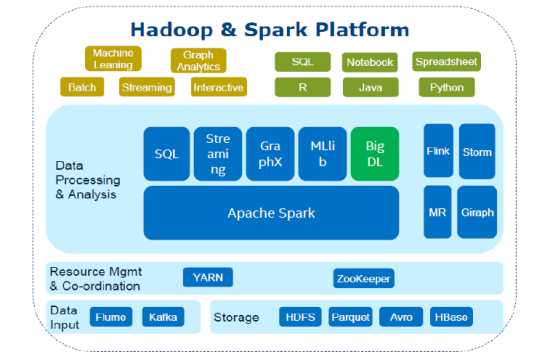
BigDL是Spark上一个标准的深度学习库,用户可以像编写标准的大数据Spark程序一样开发深度学习应用。它可以直接在用户现有的Hadoop和Spark集群上运行,无需对集群做任何修改,还可以重新使用现有的软硬件架构,而不需要设置特殊的软件或者硬件。从BigDL本身来说,它具备和主流深度学习框架Caffe、Torch、TensorFlow等相同的功能,并且为大数据平台或大数据集群、Hadoop集群、Spark集群进行了特别优化——这也正是BigDL和其他深度学习框架不一样的地方:一方面它在单点上利用英特尔MKL、多线程编程等,比其他开源框架更快,可以得到很高的性能;同时又充分利用Spark架构,在集群上进行横向扩展,方便跑在几十个甚至上百个节点上。此外,英特尔还对Python和JAVA提供全面支持,在Scala环境和Python环境的功能是等价的,这样也能够非常方便的让用户在生产环境中使用。
这样设计,BigDL不仅可以在Spark平台上和其他组件方便的交流,还能让企业建立起整套的端到端解决方案。其实,整个Hadoop生态环境也给用户提供了很多组件,包括管理机器、引入数据、存储数据以及分析等。这样一个更大的平台上,BigDL能够嵌入进去,让企业在现有的大数据生态上做研发,达到“深度学习民主化”。BigDL的主要开发目的就是要使深度学习更易于大数据用户、数据科学家来使用,这其中是由于几个重要的业界趋势导致的:
- 第一个趋势,数据规模扩展推动了深度学习的发展。随着数据增长,传统算法的效果会慢慢增加,但当数据规模大到一定程度之后它的增加却基本呈现水平趋势。而今天深度学习之所以这么有效,一个非常重要的原因是由于访问数据在不断增加,并且具备了在数据上进行高效分析和处理的能力。
- 第二个趋势,Hadoop成为了“数据重力中心”。目前,Apache Hadoop生态系统已经成为业内大数据平台、大数据存储、处理和分析的事实标准,Hadoop成为了“数据重力中心(Center Data Gravity)”。从这个意义上来说,任何数据分析的框架或技术,包括深度学习框架都能够很好地在以Apache Hadoop为代表的大数据平台上运行和集成。
- 第三个趋势,工业级机器学习/深度学习系统是复杂的大数据分析流水线。高级别的机器学习或深度学习系统,其实是非常复杂的端到端数据分析流水线,必须有大量组件组合在一起,从数据的输入、清洗、管理,再到特征的管理、提取、转换,包括资源的管理、调度和监测等等。机器学习/深度学习算法必须能在这样一个端到端的复杂流水线上和其他组件非常好地一起工作,这也是构建工业级深度学习应用非常重要的要求。
- 第四个趋势,统一的大数据平台推动了数据分析和数据科学的发展。五年前,大数据系统还有很多不一样的类型,比如存储、数据输入、资源管理、机器学习、图分析、流式处理、SQL语言、Python语言、R语言甚至于可视化的表格式处理等等。到今天,以Apache Hadoop和Spark为标准的大数据平台其实已经成为了统一的大数据平台,推动了大数据分析进入了民主化,让更多人更方便地分析数据。
英特尔要推动人工智能的民主化,就要做到高易用性、高效扩展、更低的TCO以及卓越的性能。BigDL正是为了满足这些需求,使深度学习更便于大数据和数据科学家来使用。
- 在存储数据的同一个Hadoop/Spark集群上使用深度学习来分析”大数据”。深度学习需要对大量的数据进行分析,BigDL能够让用户在存储数据的集群上直接运行深度学习,略去数据拷贝、模型拷贝等复杂、低效的工作。
- 在大数据(Spark)程序和工作流之中增加深度学习功能。构建真正完整的深度学习、机器学习能力,需要在现有大数据的工作流里增加深度学习功能,而BigDL能和Spark无缝结合,可以直接在工作流里面处理数据。
- 利用已有的Hadoop/Spark集群来运行深度学习应用。BigDL是一个标准的Spark上应用,做到的是Real Out of Box,可以在现有Hadoop、Spark集群上直接运行。BigDL把所有相关库的文件打包到MKL架构,那么所有的EI都会被自动分发到机器和云平台上,在使用BigDL时就不需要安装任何额外的东西,让用户无痛使用BigDL。
- 与其他用户和任务动态共享计算资源。BigDL能直接在Hadoop、Spark集群上运行,和其他用户共享计算资源,还可以重新利用大数据平台现有的一整套机制,来很方便地运维、管理深度学习应用。
从模型定义、数据处理、模型训练和模型调试四个方面,可以抽丝剥茧,深度解析BigDL的关键技术应用。
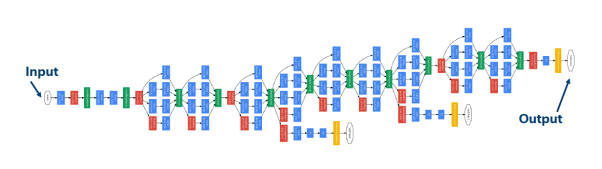
- 模型定义:下图是谷歌2014年左右提出的GoogleNet分类模型,使用起来非常方便。BigDL提供了两种模型定义方式:一是Sequential,前后有数据关系;另一种是Functional,没有那么直观但更有表现力。目前这两种方式也是所有深度学习库基本都遵循的方式。BigDL对包括Embedding(即嵌入层)在内的一百多种不同层次提供支持,同时还有SimpleRNN、LSTM、GRU、LSTM with Peeholes等非常丰富的循环神经网络支持。
- 数据处理:数据预处理,就是对图片做一些规划和抠取操作,使之符合模型输入的要求。无论是Python还是Scala,都是基于Spark大数据平台,数据存储在某一文件系统里,同时Spark把数据集合起来,形成一个分布式的数据集。所有的数据处理都在分布式数据集上进行,很多机器会一起去处理,效率较高。
- 模型训练:模型会做预测和判断,当结果与实际不同时用Loss function参数去评价差异性。Loss function不仅能够评价差异,还能提供反馈,指示模型应怎样调试参数使差距变小,不断循环再反馈到模型里去。当差异非常小的时候,那模型就训练好了。BigDL实际上提供了多至十种不同的训练算法,让用户非常方便地去训练模型。同时提供的多个组件能够自定义模型,在训练过程中灵活处理不同的情况。
- 模型调试:在深度学习中,模型如果初始化不好的话很容易训练失败,所以模型初始化时往往使用随机数据填充。目前BigDL支持几种常用的算法,能够适应不同模型的需求。此外,正规化也是比较重要的功能,可以提高模型质量。BigDL目前也提供了一些正规化的方式,包括一个全球正规化的参数、每个不同层独特设计的正规化参数等。
2016年12月30日英特尔开源了BigDL,今年上半年又发布了两个版本0.1.0和0.1.1,专注于提高深度学习在数据科学家中的易用性,此外,BigDL在公有云、大数据分析平台上也都提供了非常好的支持。目前,BigDL支持Linux、Mac OS、Windows,基本上涵盖了主要工作环境。在上个月的ISC2017国际超算大会上,Cray发布的一款Cray Urika XC analytics software suite分析软件中直接集成了BigDL 0.1产品,这应该也是目前第一款BigDL商用发行版。
英特尔现在正工作在BigDL 0.2版本上。BigDL 0.2提供了更加丰富易用的分布式深度学习支持,包括对一些功能性API的支持、TensorFlow模型导入以及TensorFlow模型定义的支持。同时还整合了Spark ML,更加关注Windows平台支持。另外还支持用户把BigDL模型导出到Caffe、TensorFlow、Torch,把它作为本地的Java Program在本地的JVM运行。当然还会提供更多高级的神经网络支持及3D图像的处理。
BigDL具有丰富的应用场景,包括电商、工业制造、3D医疗、情感分析等多个领域。
- 欺诈交易侦测。英特尔和银联的电子商务与电子支付国家工程实验室一起利用BigDL构建了一个端到端的欺诈交易检测应用,本身构建这样一个端到端的数据处理就是一个大数据分析的典型应用,只是英特尔在里面加入了新的深度学习功能。
- 工业制造中的产品缺陷检测。工业制造商需要在大量的流水线图片中自动检测出产品有没有瑕疵,整个过程就是一个端到端的数据处理,从图片输入、Proposal Extraction、图像预处理、训练预测,最后回到原始图片进行后处理。某种意义上这正是一个图像识别和目标检测的典型应用。
- 3D医疗影像分析。英特尔在跟国外一个非常大的医疗研究机构合作,研究更好的3D医疗影像分析,在即将发布的BigDL 0.2里也加入了非常多的3D图片分析和处理功能。
- 自然语言的情感分析。人工智能的命题就是利用BigDL深度学习框架来分析金融营销的活动情感,正在进行的2017年英特尔杯全国并行应用挑战赛项目,英特尔会和银联合作,对银联促销和营销时用户给的反馈进行数据抓取分析。
- 与Spark SQL和流式处理的无缝集成。训练出来的BigDL模型可以直接在SparkSQL里构建一个UDF,用在SQL查询里面。任何一个分析师都只会写SQL应用,但是借助BigDL来使用UDF,能够在SQL应用里直接调用深度学习模型,方便使用人工智能技术。
总的来说,从硬件、软件到上层体验,包括从数据中心端到设备端,英特尔有一个非常完整、一致的体验和技术。对BigDL的大力开发,就是希望在Spark大数据平台上能够更快、更容易地应用深度学习解决方案。基于这样的框架,用户可以学习数据中的知识,并且带来更多的生产力,促进人工智能计算的民主化。
大咖访谈,话技术风云
在媒体问答环节,英特尔公司软件与服务事业部副总裁、系统技术及优化部门总经理Michael Greene,英特尔资深首席工程师、大数据技术全球CTO戴金权,共业界多家媒体,深度探讨了BigDL应用、市场现状、战略分析等问题。

英特尔公司软件与服务事业部副总裁、系统技术及优化部门总经理 Michael Greene

英特尔资深首席工程师、大数据技术全球CTO 戴金权
深入解读,全面探析开源项目BigDL
Q:BigDL的研发规模有多大?在上海和硅谷人员的分工上有怎样的侧重?
戴金权: BigDL的上海和硅谷研发团队总计二十人左右,工作内容有多方面:Spark整体战略分析,人工智能、深度学习的应用需要端到端的数据科学分析工作,也包括机器学习等等;除了框架平台本身,还会有一些算法模型方面的工作,涉及整个大数据分析、机器学习、深度学习、人工智能这样一个完整的平台和流水线。从算法到框架,再到底层大数据的框架工作都会涉及。在上海和硅谷人员的分工上没有严格区分,不管是分布式系统还是深度学习框架,再到上面的模型算法,都是等同的团队。
Q:BigDL是目前英特尔首推的大数据和深度学习框架吗?作为一个开源项目,后续有商业变现的考虑吗?
戴金权:英特尔在平台上做了大量的优化工作,在深度学习的框架中能够得到几十到几百倍的性能提升。所以说,BigDL是我们目前针对大规模、分布式的大数据架构,在大规模的至强服务器集群上非常重要的解决方案。大数据、深度学习的任务能够在英特尔平台上高效方便地运行,对英特尔来说也有非常大的价值。在开源这一点上,英特尔一直致力于通过开源社区打造好整个生态圈,使产业快速发展。BigDL同样如此,通过开源项目使更多人更方便地使用深度学习,让深度学习应用更广泛。因此目前,我们还是专注将开源软件做好,在现有的大数据集群上实现性能最佳,让用户、合作伙伴和消费者把服务提供出来。当然,英特尔还会致力于硬件加速和优化方面的工作,这可能正是我们下一步工作的方向。
Q:前面提到了BigDL与银联的合作,在类似数据安全性要求较高的领域,英特尔对于安全问题有怎样的考虑?
戴金权:大数据安全是一个非常重要的课题,类似银联的用户本身就有一套欺诈交易侦测的系统,但是利用BigDL,用深度学习训练十几二十个独立的神经网络模型,做一个Bagging集成,比现有系统的准确率会更高。英特尔在大数据安全方面也有非常多的考虑。在Hadoop整个生态系统里,除了有数据处理,其实还有很多数据安全、数据管理的项目,以更好地提供数据保护服务,这其实是英特尔一直在做的事情。
Q:BigDL从研发、测试到整个开源的阶段里经历过哪些比较难克服的挑战?
戴金权:从BigDL的角度来说,最大的挑战就是让它更易用。如何让更多人更方便地使用,是我们一直关注的问题,包括如何用现有的数据处理流程相整合、如何更方便地在现有集群上部署使用从而无缝扩展等等。因此我们和用户进行合作,工程师们在试用BigDL后认为BigDL使用起来十分方便,几乎不需要配置部署就可以跑得很好。当然,后续我们也希望从可用性、扩展性、性能、功能性方面做到更好。
时势纵览,AI民主化推动市场革新
Q:前面一直提到的民主化,有什么样的内涵?这种大数据和人工智能的民主化,对整个产业会有怎样的影响?
戴金权:前面所提到的要把大数据技术民主化,或者是普及化,从英特尔的角度来说就是希望它能够更方便、更广泛地让大家使用。目前可以看到,深度学习社区几乎每周都会有新的技术突破,这是非常令人激动的,但如果你看到生产环境中真正“沉默的大多数”,就会发现大数据和深度学习社区是不完全匹配的——深度学习现有的软件框架、硬件架构对他们来说不够用户友好,所以使用非常麻烦。我们开源了BigDL之后,让各行各业的工程师、一般的数据科学家,甚至一些分析师都能使用,这样才能让深度学习在各行各业中得到非常广泛的应用,推动技术变革。同时,这对于组织在业界的竞争力也会有十分重要的影响。
Q:现在的大数据、深度学习可以很好地进行数据融合吗?后续深度发展的话会有哪些问题?
戴金权:时下,大数据、深度学习在某些场景中的应用已经实现了非常好的效果,但对于组织来说,怎样利用大数据分析和人工智能并使之成为组织发展的一部分,还是会涉及技术之外的问题。另外从技术的发展角度来说,仍需要在一些重要领域继续努力,以深度学习为例:很多人都表示在有监督的学习里面能够做得不错,但其实这是非常狭隘的观点,真正的人工智能应该在无监督的领域下完成。所以,大数据、人工智能在技术上还需要进一步发展。
Q:BigDL对公有云和大数据分析平台都提供了支持,基于此,该如何看待大数据、云计算和人工智能三者的关系?
戴金权:人工智能是一个比较宽泛的概念,早期的人工智能多是一些规则系统、推理系统,但近几年来人工智能在很大程度上是用深度学习、机器学习构建学习的系统。在这个环境下,就像我前面提到的统一大数据平台,它能够对大数据进行管理和分析,并在上面构建机器学习、深度学习应用,这是人工智能的关键。人工智能里的算法和模型十分重要,但要构建工业级的系统应用,必然需要和大数据分析整个平台相互整合来构建。从某种程度上来说,大数据平台和云计算架构是非常一致的,不管是公有云还是在企业内部自己构建的平台,都是与云计算的特点一致,要做横向扩展。
Q:有人认为国外的技术更加先进,但在应用角度落地上国内做的更加优秀。大数据分析和人工智能在国内外的区别有哪些?
戴金权:中国不管是数据规模、应用场景还是落地时间,其实非常领先,能够快速把技术应用到生活场景中,我觉得这是中国很大的优势——快速应用技术并反过来推动技术发展。当然,因为大数据、人工智能从某种程度上还是高端科技,所以在人才储备等方面,国外的一些大学、企业可能做得比较早。但也不完全如此,就比如BigDL团队,我们在上海和硅谷的工程师中,有超过一半的工程师都在上海。我觉得从某种意义上来说,中国在人才、技术方面并没有很大差距,所以说大家基本是在同一起跑线上。
软硬件结合,助力英特尔战略升级
Q:英特尔之前是一家聚焦于硬件的公司,现在软件对于英特尔而言也越来越重要了吗?未来软件这块的商业模式能谈一下吗?
Michael Greene:事实上软件对于英特尔来说一直都是非常重要的。最早我们就寻求多种方式去和软件开发商合作,比如在PC端,微软和开源社区Linux都是我们的合作伙伴,后来软件开发的重心从PC端迁移到云、数据中心,还有机器学习和AI。我们也会跟随这样的趋势,完成软件开发的重心迁徙。
我们在软件服务上的宗旨就是创造好的软件和解决方案,由英特尔芯片去赋能,并在英特尔硬件上运行。我们的商业模式也一直没有改变,就是硬件加软件的结合,以使我们的客户和使用者能够得到更好更强的运算能力。在芯片制造方面,英特尔当然是非常强的,在处理器、存储芯片的制作方面我们也保持着非常高的水准,不断提高计算能力。所以在软件方面我们的商业模式就是一以贯之,不断打造这样的生态系统,通过软件助力整个英特尔的架构。
Q:英特尔内部软件部门和硬件部门是怎样协同协作的?
Michael Greene:在英特尔内部,部门之间的边界往往非常模糊,很难有一个精准的界定。对我们来说软件和硬件具有同样的一个目标,就是为客户提供完整优化的最佳解决方案。一切工作始于客户需求,客户需求往往是以软件需求的形式来提出的。我们在内部就会把软件的需求和整个硬件的发展路线图结合在一起,最终能够保证交付的是软硬件结合的解决方案。
Q:英特尔在国内外市场的应用落地程度上有什么不同?
Michael Greene:我们密切关注中国市场和全球的市场变化,也看到很多公司正在转型成为一个数据驱动的公司,这个趋势不管在中国还是全球范围内都相当一致。我们BigDL的宗旨就是通过这样的框架,加速公司转化为数据驱动公司的过程。在数据分析这块,中国市场和全球市场并没有太多不同,所以中国的应用和实践也可以供美国,或者非洲、印度、欧洲去借鉴。因为现在整个世界的连接度非常高,每个公司或者每个市场都在竭力于利用数据池和数据库去挖掘更多的洞察和知识。
Q:英特尔内部客户需求的搜集方面是什么样的形式?技术的快速迭代下,客户需求呈现什么样的特点?英特尔的软件研发重点又呈现怎样的变化趋势?
Michael Greene:一方面,我们和开源社区合作,从开源社区中获取客户洞察,了解开发者的需求。另一方面,我们还有一个专业的销售团队,不断和已有的客户沟通,了解他们的目标和业务发展路线图。此外,我们也和客户、合作伙伴签订合作备忘录,基于这些合作备忘录进行定期的分享,互相匹配,以保证不会错失任何的机会。在过去几年间可以看到整个软件开发者的需求在不断进化:从一开始只需要优化计算库,到现在希望的是一个完整、全面的数据解决方案。随着开发者需求的不断进化,英特尔在软件上的开发服务也会不断进化。
更多精彩,欢迎关注CSDN大数据公众号!

这篇关于致力技术民主化,开源新贵BigDL的进阶之路的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







