本文主要是介绍OpenShift 4 - 使用 VerticalPodAutoscaler 优化应用资源 Request 和 Limit,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
《OpenShift 4.x HOL教程汇总》
说明:本文已经在OpenShift 4.10 环境中验证
文章目录
- 了解 VPA 和 HPA
- 安装配置 VPA
- 当应用程序出现 OOMKilled 时,自动调整 requests 和 limits 配置
- 应用运行在无 VPA 情况下
- 应用运行在有 VPA 情况下
- 参考
了解 VPA 和 HPA
HPA - Horizontal Pod Autoscaler 和 VPA - Vertical Pod Autoscaler 是两种扩展容器应用处理能力的方式,HPA 是通过扩展 Pod 的数量实现的,而 VPA 是通过增加单个 Pod 的可用资源实现的。
通常 HPA 可用于水平扩展较容易的情况,例如 Serverless、FaaS、无状态微服务等。而 VPA 适用于水平扩展较复杂的情况,例如消息顺序处理、文件读写、数据库操作等。一般不建议对同一个资源同时应用 HPA 和 VPA。
VPA 会自动检查 Pod 中容器的运行状况和当前的 CPU 和内存资源,并根据它所了解的用量值更新资源限值和请求。VPA 使用单独的自定义资源(CR)来更新与工作负载对象关联的所有 Pod。VPA 能够自动计算这些 Pod 中容器当前的 CPU 和内存使用情况,并使用这些数据来决定优化的资源限制和请求,以确保这些 Pod 始终高效操作。例如,VPA 会减少请求资源超过使用资源的 Pod 的资源,并为没有请求充足资源的 Pod 增加资源。例如一个 Pod 当前使用了 CPU 的 50%,但只请求了 10%。VPA 会认定该 Pod 消耗的 CPU 多于请求的 CPU,并删除 Pod。工作负载对象(如副本集)会重启 Pod,VPA 使用推荐的资源更新新 Pod。
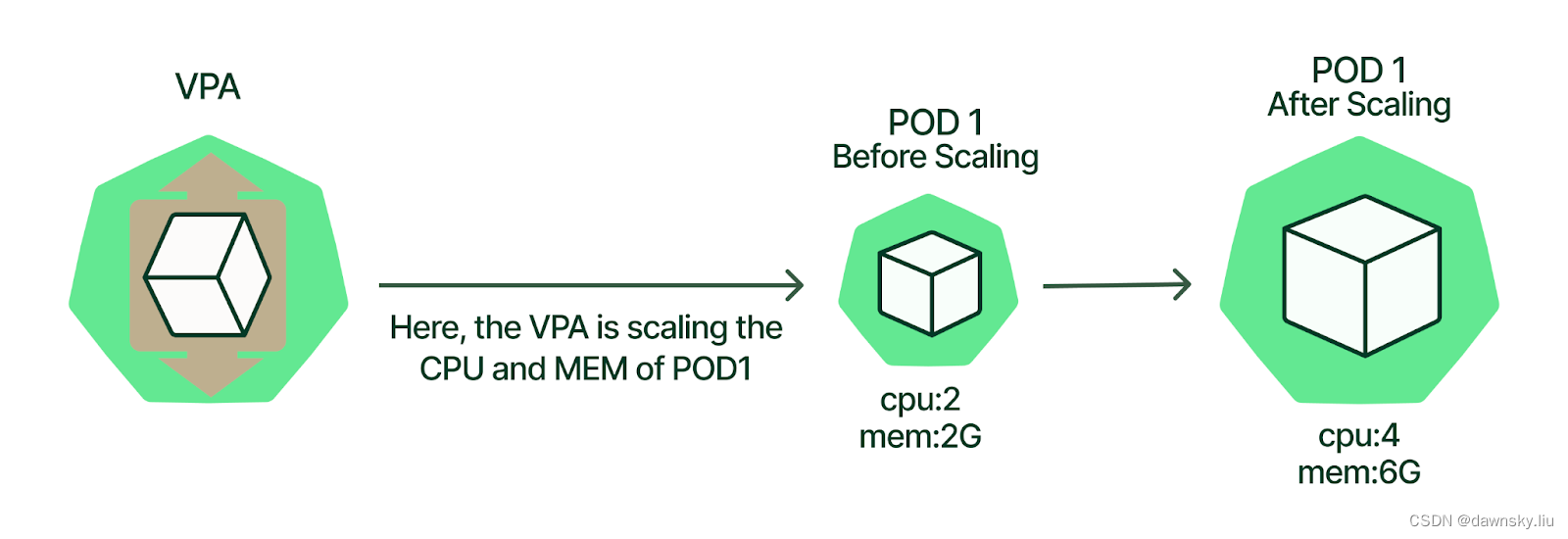
VPA 可以自动删除不符合建议的 Pod(建议工作负载对象至少运行两个副本,这样才不会影响连续运行)。在运行新的 Pod 时候,VPA 使用一个变异准入 webhook 来确保在运行 Pod 前将其资源调整为优化后的限制和请求。除了自动更新 Pod 外,还可手动删除 Pod,VPA 会使用其建议创建新的 Pod。
可以使用 VPA 来更好地利用集群资源,例如防止 Pod 保留比所需的 CPU 资源更多的资源。VPA 监控实际使用的工作负载,并对资源进行调整,以确保可以满足其他工作负载的需要。
如果停止在集群中运行 VPA 或删除特定的 VPA CR,则已由 VPA 修改的 pod 的资源请求不会改变。任何新 pod 都会根据工作负载对象中的定义获得资源,而不是之前由 VPA 提供的的建议。
VPA 需要关联一个工作负载对象,VPA 支持一下策略更新工作负载:
- Auto 和 Recreate 模式会在 Pod 生命周期内自动应用 VPA 对 CPU 和内存建议。VPA 会删除项目中任何与建议不兼容的 Pod。当由工作负载对象重新部署时,VPA 会在其建议中更新新 Pod。
- Initial 模式仅在创建 Pod 时自动应用 VPA 建议。
- Off 模式只提供推荐的资源限制和请求信息,用户可以手动应用其中的建议。off 模式不会更新 Pod。
安装配置 VPA
- 使用默认配置在 OpenShift 中安装 Vertical Pod Autoscaler Operator。
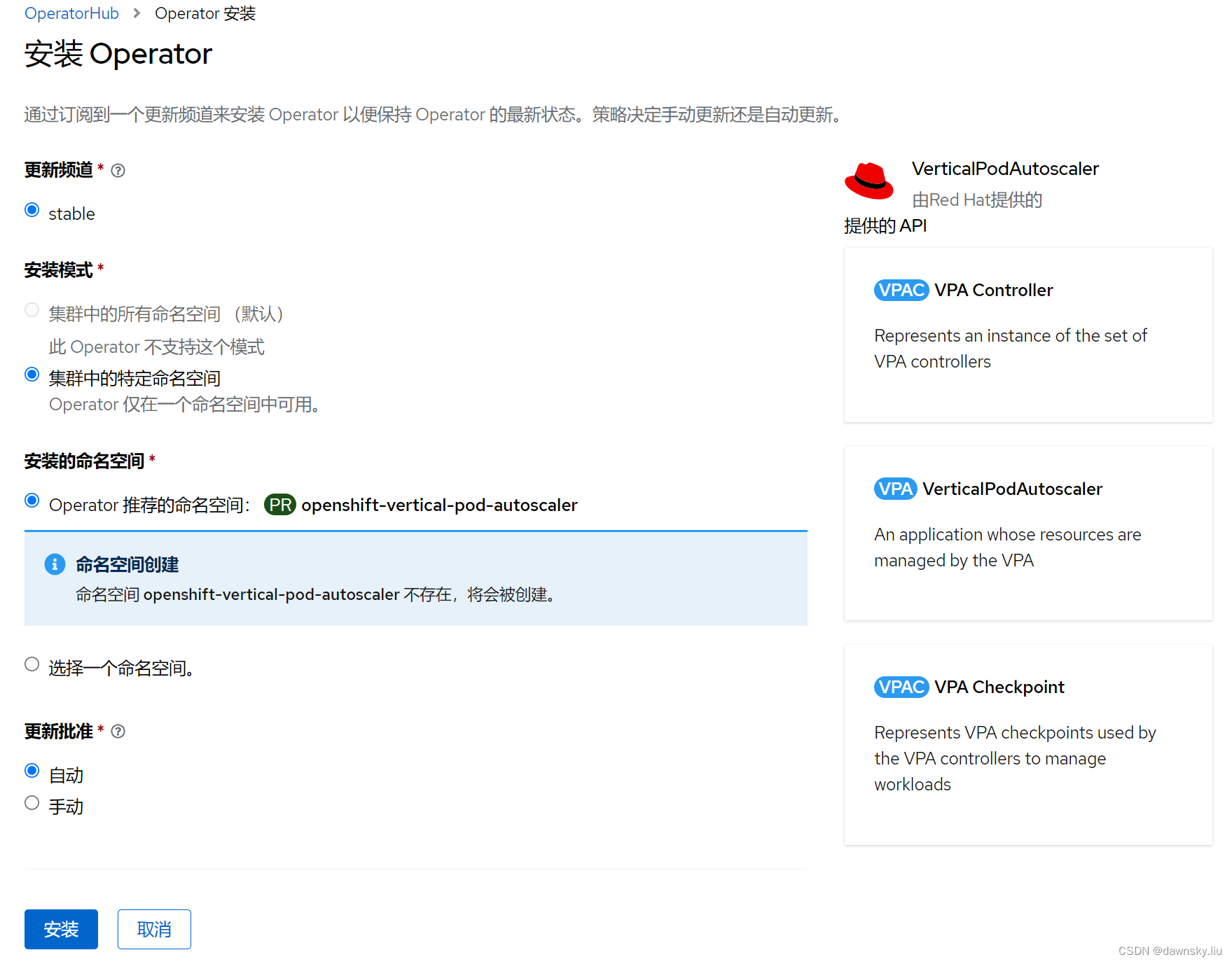
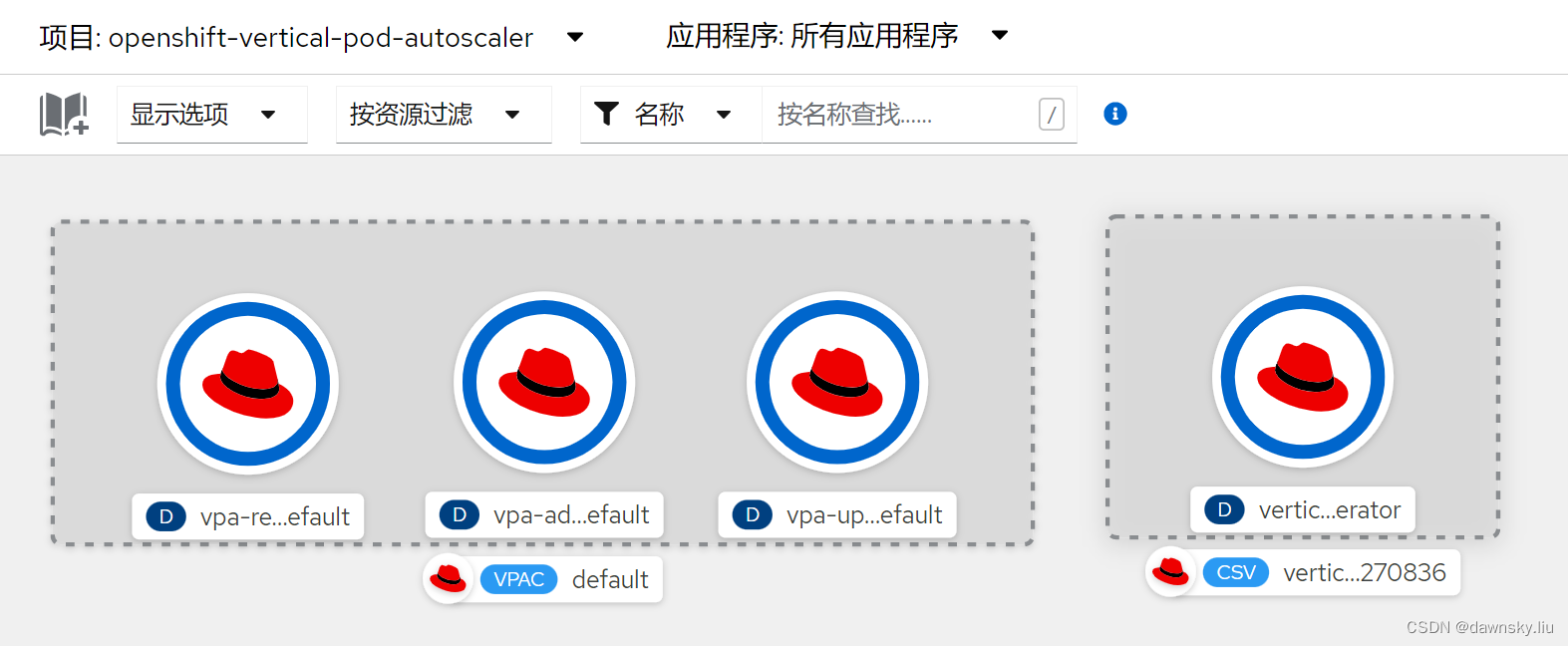
- 安装后会在 openshift-vertical-pod-autoscaler 项目中部署以下资源:
当应用程序出现 OOMKilled 时,自动调整 requests 和 limits 配置
应用运行在无 VPA 情况下
- 创建一个新项目。
$ oc new-project app-novpa
- 部署测试应用。注意:虽然为容器分配的内存上限为 200Mi,但是应用会申请 250M 的内存。
$ cat << EOF | oc -n app-novpa apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:name: stress-novpa
spec:selector:matchLabels:app: stressreplicas: 1template:metadata:labels:app: stressspec:containers:- name: stressimage: polinux/stressresources:requests:memory: "100Mi"limits:memory: "200Mi"command: ["stress"]args: ["--vm", "1", "--vm-bytes", "250M"]
EOF
- 部署应用后查看 Pod 运行状态,确认 Pod 出现 OOMKilled 情况而无法正常运行。
$ oc get pod -n app-novpa -w
NAME READY STATUS RESTARTS AGE
stress-novpa-5f8cf46f67-cscjh 0/1 Pending 0 0s
stress-novpa-5f8cf46f67-cscjh 0/1 Pending 0 0s
stress-novpa-5f8cf46f67-cscjh 0/1 ContainerCreating 0 0s
stress-novpa-5f8cf46f67-cscjh 0/1 ContainerCreating 0 2s
stress-novpa-5f8cf46f67-cscjh 0/1 OOMKilled 0 3s
stress-novpa-5f8cf46f67-cscjh 1/1 Running 1 (1s ago) 4s
stress-novpa-5f8cf46f67-cscjh 0/1 OOMKilled 1 (2s ago) 5s
stress-novpa-5f8cf46f67-cscjh 0/1 CrashLoopBackOff 1 (2s ago) 6s
stress-novpa-5f8cf46f67-cscjh 0/1 OOMKilled 2 (18s ago) 22s
应用运行在有 VPA 情况下
- 创建一个新项目。
$ oc new-project app-vpa
- 部署测试应用,其中为容器分配内存上限为 200Mi,而应用只申请 150M 内存。
$ cat << EOF | oc -n app-vpa apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:name: stress
spec:selector:matchLabels:app: stressreplicas: 1template:metadata:labels:app: stressspec:containers:- name: stressimage: polinux/stressresources:requests:memory: "100Mi"limits:memory: "200Mi"command: ["stress"]args: ["--vm", "1", "--vm-bytes", "150M"]
EOF
- 确认此时应用可以正常运行,然后查看 Pod 的状态和当前对内存的 Request 和 Limit。
$ oc get deployment -n app-vpa
NAME READY UP-TO-DATE AVAILABLE AGE
stress 1/1 1 1 21m$ oc get pod -n app-vpa -w
NAME READY STATUS RESTARTS AGE
stress-589cd958-7dlhc 1/1 Running 0 14s$ oc get pod -n app-vpa -l app=stress -o yaml | grep requests -A1requests:memory: 100Mi$ oc get pod -n app-vpa -l app=stress -o yaml | grep limits -A1limits:memory: 200Mi
- 创建 VerticalPodAutoscaler 对象,将其关联名为 stress 的 Deployment,并对其下所有容器 ( containerName: ‘*’ ) 有效。其中 minAllowed 和 maxAllowed 是针对 Request 的有效上限和下限。
$ cat << EOF | oc -n app-vpa apply -f -
apiVersion: "autoscaling.k8s.io/v1"
kind: VerticalPodAutoscaler
metadata:name: stress-vpa
spec:targetRef:apiVersion: "apps/v1"kind: Deploymentname: stressresourcePolicy:containerPolicies:- containerName: '*'minAllowed:cpu: 100mmemory: 50MimaxAllowed:cpu: 1000mmemory: 1024MicontrolledResources: ["cpu", "memory"]
EOF
说明:VPA 支持黑名单机制,即黑名单中的容器不会被应用 VPA 策略。
- 查看当期 VPA 对象。
$ oc get vpa -n app-vpa
NAME MODE CPU MEM PROVIDED AGE
stress-vpa Auto 1 262144k True 90s
- 查看 VPA 建议分配的 CPU 和内存。其中 lowerBound 为建议分配的资源最低量,target 为建议分配的资源量,upperBound 为建议分配的资源最高量,uncappedTarget 为最新的建议分配资源量。VPA 使用 lessBound 和 upperBound 值来确定一个 Pod 是否需要更新。如果 Pod 的资源请求低于 lowerBound 值,或高于 upperBound 值,则 VPA 会终止 Pod ,并使用 target 值重新创建 Pod 。
$ oc get vpa stress-vpa -n app-vpa -oyaml
。。。recommendation:containerRecommendations:- containerName: stresslowerBound:cpu: "1"memory: 262144ktarget:cpu: "1"memory: 262144kuncappedTarget:cpu: 1643mmemory: 262144kupperBound:cpu: "1"memory: 1Gi
- 修改名为 stress 的 Deployment,将其使用内存改为 “250M"。注意:此时应用申请的 “250M" 内存已经超过了由 Deployment 中的 limits 规定分配给 Pod 的内存上限了。
$ oc patch deployment stress -n app-vpa --type='json' -p='[{"op": "replace", "path": "/spec/template/spec/containers/0/args/3", "value": "250M" }]'
- 修改后可查看 Pod 的变化情况,原有 Pod 会被删除,新的 Pod 会被创建。
$ oc get pod -n app-vpa -w
NAME READY STATUS RESTARTS AGE
stress-7b9459559c-ntnrv 1/1 Running 0 5s
stress-7d48fdb6fb-7dlhc 1/1 Terminating 0 22m
- 确认新的 Pod 可用内存的上限被调整到 500Mi。
$ oc get pod -n app-vpa -l app=stress -o yaml | grep limits -A1limits:memory: 500Mi
- 再次修改名为 stress 的 Deployment,将其使用内存改为 “1500M"。由于 Pod 申请内存已经超过 VPA 中 upperBound 定义的 “1Gi" 上线,因此 Pod 再次出现 OOMKilled。
$ oc patch deployment stress -n app-vpa --type='json' -p='[{"op": "replace", "path": "/spec/template/spec/containers/0/args/3", "value": "1500M" }]'$ oc get pod -n app-vpa -w
NAME READY STATUS RESTARTS AGE
stress-5f8cf46f67-ntnrv 1/1 Running 0 5m54s
stress-947fdb66f-rfq5t 0/1 CrashLoopBackOff 1 (8s ago) 14s
stress-947fdb66f-rfq5t 0/1 OOMKilled 2 (17s ago) 23s
参考
https://access.redhat.com/documentation/zh-cn/openshift_container_platform/4.10/html/nodes/nodes-pods-vertical-autoscaler-using-about_nodes-pods-vertical-autoscaler
https://rcarrata.com/kubernetes/predictive-autoscaling-patterns-with-vpa/
https://cloud.redhat.com/blog/how-full-is-my-cluster-part-4-right-sizing-pods-with-vertical-pod-autoscaler
https://medium.com/infrastructure-adventures/vertical-pod-autoscaler-deep-dive-limitations-and-real-world-examples-9195f8422724
这篇关于OpenShift 4 - 使用 VerticalPodAutoscaler 优化应用资源 Request 和 Limit的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





