本文主要是介绍cpca库使用简明教程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
cpca是chinese_province_city_area_mapper的简称,可用于处理中文地址,这里记录cpca库的主要使用方法。
安装
pip install cpca
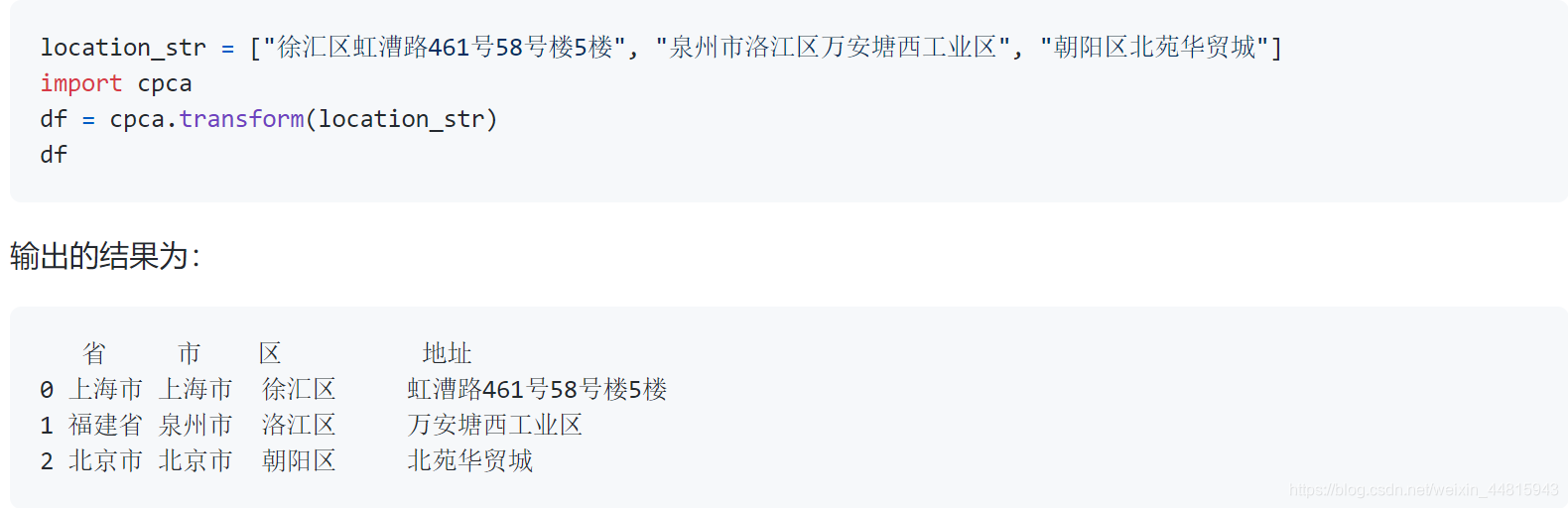
cpca.transform
cpca.transform 是 cpca库的核心功能,其输入是任意可迭代对象,输出为pandas的DataFrame对象,参数及含义如下:
- location_strs :包含地址信息的字符串,是一个可迭代对象,可迭代对象的元素数量将等于输出结果中DataFrame的行数量。
- umap:一个自定义的字典,用于处理“行政区”重名问题。自定义的字典应指明重名区默认对应哪个“行政省市”。另外省、市行政区域名称不存在重名问题,因此仅考虑“行政区”重名问题即可。
- index:指定自定义的DataFrame的index值。
- cut:是否使用分词匹配模式,默认是True,会提高处理速度。若指定False,则会采用“全文匹配的模型”,该模型下的精度会高些,但处理速度会慢些。
- lookahead:默认为8个字符,可以理解为窗口大小。
- pos_sensitive:默认为False,改为True时,则在输出的DataFrame中将新增三列,分别表示抽取省、市、地区的起始位置。若值为-1,表示位置为推断出来的。
- open_warning: 是否显示警告信息,默认True,建议打开(当发现重名区并且不知道将其映射到哪一个市时,会将其加入警告信息并显示,打开此功能可以帮助解决数据集中的重名区问题)。
函数输入输出如下所示,信息来自官方文档:
参考资料
https://github.com/DQinYuan/chinese_province_city_area_mapper
这篇关于cpca库使用简明教程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






