本文主要是介绍YOLOv5结合华为诺亚VanillaNet Block模块,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

🗝️YOLOv5实战宝典--星级指南:从入门到精通,您不可错过的技巧
-- 聚焦于YOLO的 最新版本, 对颈部网络改进、添加局部注意力、增加检测头部,实测涨点💡 深入浅出YOLOv5:我的专业笔记与技术总结
-- YOLOv5轻松上手, 适用技术小白,文章代码齐全,仅需 一键train,解决 YOLOv5的技术突破和创新潜能❤️ YOLOv5创新攻略:突破技术瓶颈,激发AI新潜能"
-- 指导独特且专业的分析, 也支持对YOLOv3、YOLOv4、YOLOv8等网络的修改🎈 改进YOLOv5📖 ,改进点包括: 替换多种骨干网络/轻量化网络, 添加多种注意力, 包含自注意力/上下文注意力/自顶向下注意力机制/空间通道注意力/,设计不同的网络结构,助力涨点!!!

YOLOv5结合华为诺亚VanillaNet Block模块
- 介绍
- 核心代码
- 加入YOLOv5
- yaml文件:
- 运行结果
论文: VanillaNet: the Power of Minimalism in
Deep Learning
代码: https://link.zhihu.com/?target=https%3A//github.com/huawei-noah/VanillaNet
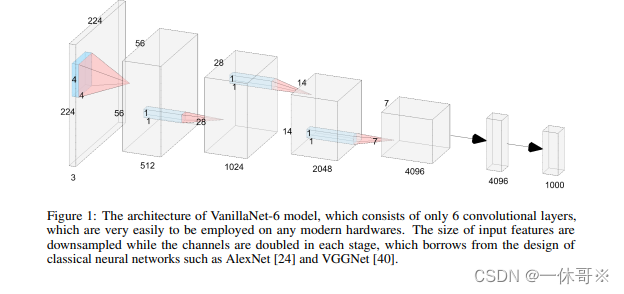
介绍
基础模型的设计哲学往往遵循“更多即更好”的原则,在计算机视觉和自然语言处理领域取得的显著成就中得到了验证。尽管如此,对于Transformer模型而言,随之而来的优化挑战和固有的复杂性也促使了向更简洁设计的转变。
本研究引入了VanillaNet,一种在设计上追求简洁性的神经网络架构。VanillaNet避免了复杂的构建如高深度网络结构、捷径连接和自注意力机制,呈现出一种令人耳目一新的简明强大。它的每一层都经过精心设计,简洁且直接,训练后的非线性激活函数被精简,以还原至最初的简洁结构。
VanillaNet以其对复杂性的挑战克服,成为资源受限环境下的理想选择,其易于理解和简化的构架开启了高效部署的新可能。广泛的实验结果验证了VanillaNet在图像分类、目标检测和语义分割等多项任务中可与知名的深度网络和视觉Transformer相媲美的性能,彰显了极简主义在深度学习中的潜力。VanillaNet的创新之路预示着重新定义行业格局和挑战传统模型的巨大潜力,为简洁而有效的模型设计铺开了全新的道路。


为了解决多头自注意力(MHSA)在可扩展性方面的问题,先前的研究提出了各种稀疏注意力机制,其中查询只关注有限的键值对,而非全部。通常依赖于静态的手工设计模式或在所有查询之间共享键值对的采样子集,缺乏自适应性和独立性。
本研究提出了VanillaNet,一种简单而高效的神经网络架构,它采用了几层卷积层,去除了所有分支,甚至包括捷径连接。通过调整VanillaNets中的层数来构建一系列网络。VanillaNet-9在保持79.87%准确率的同时,将推理速度降至2.91ms,远超ResNet-50和ConvNextV2-P。
令人惊讶的成果突显了VanillaNet在实时处理任务中的潜力。进一步扩展了通道数量和池化大小,从而得到了VanillaNet-13-1.5׆,在ImageNet上达到了83.11%的Top-1准确率。这表明,通过简单的扩展,VanillaNets可以实现与深层网络相当的性能。不同架构的深度与推理速度的对比显示,网络的深度而非参数数量与推理速度紧密相关,强调了简单和浅层网络在实时处理任务中的巨大潜力。VanillaNet在所有考察的架构中实现了最优的速度与准确度的平衡,特别是在GPU延迟较低的情况下,表明了在充分计算能力支持下VanillaNet的卓越性🍀。
核心代码
#Copyright (C) 2023. Huawei Technologies Co., Ltd. All rights reserved.#This program is free software; you can redistribute it and/or modify it under the terms of the MIT License.#This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the MIT License for more details.import torch
import torch.nn as nn
import torch.nn.functional as F
from timm.models.layers import weight_init, DropPath
from timm.models.registry import register_modelclass activation(nn.ReLU):def __init__(self, dim, act_num=3, deploy=False):super(activation, self).__init__()self.deploy = deployself.weight = torch.nn.Parameter(torch.randn(dim, 1, act_num*2 + 1, act_num*2 + 1))self.bias = Noneself.bn = nn.BatchNorm2d(dim, eps=1e-6)self.dim = dimself.act_num = act_numweight_init.trunc_normal_(self.weight, std=.02)def forward(self, x):if self.deploy:return torch.nn.functional.conv2d(super(activation, self).forward(x), self.weight, self.bias, padding=(self.act_num*2 + 1)//2, groups=self.dim)else:return self.bn(torch.nn.functional.conv2d(super(activation, self).forward(x),self.weight, padding=(self.act_num*2 + 1)//2, groups=self.dim))def _fuse_bn_tensor(self, weight, bn):kernel = weightrunning_mean = bn.running_meanrunning_var = bn.running_vargamma = bn.weightbeta = bn.biaseps = bn.epsstd = (running_var + eps).sqrt()t = (gamma / std).reshape(-1, 1, 1, 1)return kernel * t, beta + (0 - running_mean) * gamma / stddef switch_to_deploy(self):kernel, bias = self._fuse_bn_tensor(self.weight, self.bn)self.weight.data = kernelself.bias = torch.nn.Parameter(torch.zeros(self.dim))self.bias.data = biasself.__delattr__('bn')self.deploy = Trueclass Block(nn.Module):def __init__(self, dim, dim_out, act_num=3, stride=2, deploy=False, ada_pool=None):super().__init__()self.act_learn = 1self.deploy = deployif self.deploy:self.conv = nn.Conv2d(dim, dim_out, kernel_size=1)else:self.conv1 = nn.Sequential(nn.Conv2d(dim, dim, kernel_size=1),nn.BatchNorm2d(dim, eps=1e-6),)self.conv2 = nn.Sequential(nn.Conv2d(dim, dim_out, kernel_size=1),nn.BatchNorm2d(dim_out, eps=1e-6))if not ada_pool:self.pool = nn.Identity() if stride == 1 else nn.MaxPool2d(stride)else:self.pool = nn.Identity() if stride == 1 else nn.AdaptiveMaxPool2d((ada_pool, ada_pool))self.act = activation(dim_out, act_num)def forward(self, x):if self.deploy:x = self.conv(x)else:x = self.conv1(x)x = torch.nn.functional.leaky_relu(x,self.act_learn)x = self.conv2(x)x = self.pool(x)x = self.act(x)return xdef _fuse_bn_tensor(self, conv, bn):kernel = conv.weightbias = conv.biasrunning_mean = bn.running_meanrunning_var = bn.running_vargamma = bn.weightbeta = bn.biaseps = bn.epsstd = (running_var + eps).sqrt()t = (gamma 这篇关于YOLOv5结合华为诺亚VanillaNet Block模块的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






