本文主要是介绍【目标检测】保姆级别教程从零开始实现基于Yolov8的一次性筷子计数,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
一,环境配置
一,虚拟环境创建
二,安装资源包
前言
最近事情比较少,无意间刷到群聊里分享的基于百度飞浆平台的一次性筷子检测,感觉很有意思,恰巧自己最近在学习Yolov8,于是看看能不能复现,自己也是新手小白,会说的比较详细,适合小白入手。
一,环境配置
对于环境配置,我的是Anaconda虚拟环境,python是3.8(建议大家大于3.7),tensorflow是2.10,GPU版本的,pytorch是1.8.0的,开发平台是pycharm。
教程:
配置Anaconda,CUDN,cudnn:Tensorflow-gpu保姆级安装教程(Win11, Anaconda3,Python3.9)_tensorflow-gpu 安装_酷酷的懒虫的博客-CSDN博客
注意:大家主要看里面配置Anaconda,CUDN,cudnn环境的部分就行,如果你的电脑不支持GPU,那么大家就可以配置cup的版本。怎么看支不支持GPU,看看笔记本有没有贴英伟达的标签就行。
配置pytorch:
GPU版本的PyTorch安装与环境配置_pytorch gpu版_「已注销」的博客-CSDN博客
这里一定要配置好,避免后续出现各种环境问题
一,虚拟环境创建
下载好anaconda后,可以专门建一个环境,然后把上述的包配置到虚拟环境中吗,这里有两种方式新建虚拟环境,一是命令行输入,二是图形化界面。
方法一:命令行操作
打开左下角开始键里的Anaconda Powershell Prompt(注意是中间有一个 Powershell,不要误打开第二个,之后对于命令行的操作我们都是在这里进行!!!),打开后默认的是base环境,就是电脑本地环境。
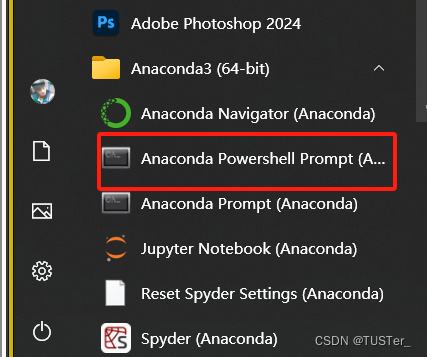
创建Yolov8环境,输入命令:conda create -n yolov8 ,表示创建一个名字为Yolov8的环境,如果想要指定python版本,可以加上如python=3.9,如果默认创建,会在C盘!
如果想要改盘,可以参考:w11下载anaconda在d盘,新建的虚拟环境总是在c盘怎么解决
之后输入:conda activate yolov8,如果成功切换就证明创建成功。
方法二:图形化界面操作
还是在刚才的左下角,点击Anaconda Navigator,打开Environments,这里会看到你电脑里所有的虚拟环境以及该环境中安装的包及其版本。

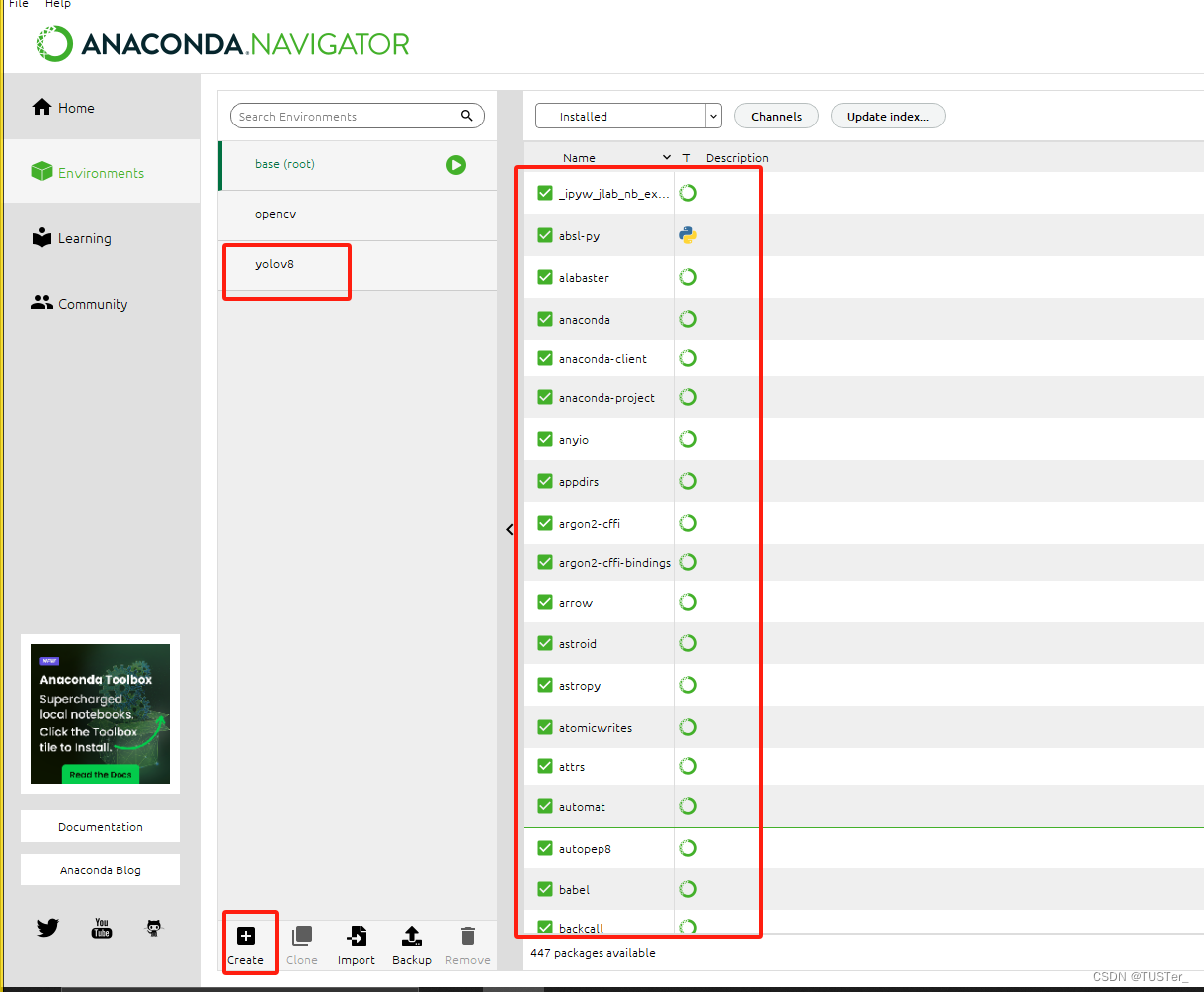
点击creat,创建新环境,在这里你可以对你的环境进行创建,删除,重命名等。如果上面出现yolov8就证明创建成功。
二,安装资源包
yolov8的训练相对于yolov5简单了很多,也比其他框架上手要来得快,因为很多东西都封装好了,直接调用或者命令行运行就行,首先需要先把代码git到本地(后续类似命令行操作都在Anaconda Powershell Prompt里输入,大家也可以在pycharm终端里输入,不过记得切换环境):
注意:如果安装过程比较慢,大家可以在命令行后加入清华源,豆瓣源等,教程:pip下载速度太慢解决方法
git clone https://github.com/ultralytics/ultralytics.git
然后安装ultralytics库,核心代码都封装在这个库里了。
pip install ultralytics再然后需要安装requirements.txt文件里需要安装的库,这里的文本文件就是运行这个项目需要配置的库的版本要求,根据需求配置环境才可以运行项目。
pip install -r requirements.txt
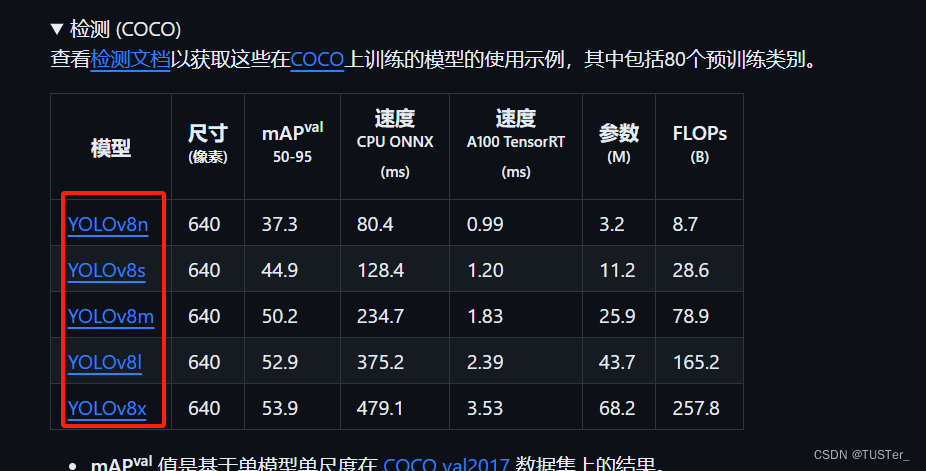
接下来我们可以把预训练模型下载下来,通俗来讲就是模型训练好的参数保存在里面的一个文件,使用命令行运行检测命令检查环境是否安装成功,将权重下载下来然后新建weights文件夹存放,项目文件默认的是yolov8n模型,其他的在官网里下载:下载预训练模型,不同的模型代表不同的性能和规模,有的精度低但是速度块,有的模型大有的小。
配置完成后,我们运行检测命令,测试yolov8是否可以运行,在项目文件的ultralytics/assets文件中有测试的两张图片。
yolo predict model=./weights/yolov8n.pt source=./ultralytics/assets/bus.jpg save
这篇关于【目标检测】保姆级别教程从零开始实现基于Yolov8的一次性筷子计数的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





